










今回はアンサンブル学習の手法の一つであるスタッキングという手法について取り上げます。
過去のアンサンブル学習についての記事は以下をご参照ください。


事前準備
前回とほぼ同様ですが、importしているライブラリが異なります。
前提条件
本ソースコードは、Python3.10.6で起動するJupyter Lab上で実行されています。
また使用している各ライブラリのバージョンは以下の通りです。
- numpy(1.22.4)
- pandas(1.4.3)
- scikit-learn (1.1.2)
タイタニックデータ取得+前処理
今回もタイタニックのデータを使用します。(タイタニックデータを使う意味はあまりないです・・)
データの取得と前処理については、以下の記事に詳細を記載しているため、今回はソースコードのみを掲載します。

(1)必要なライブラリをインポートします。
import numpy as np
import pandas as pd
import scipy.stats as stats
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split,StratifiedKFold
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler,OneHotEncoder
from sklearn.tree import DecisionTreeClassifier
from sklearn.compose import ColumnTransformer
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import StackingClassifier
from sklearn.base import ClassifierMixin,BaseEstimator
from sklearn.svm import SVC
import copy
import warnings
warnings.simplefilter('ignore')
(2)データを読み込んで教師データとテストデータに分割します。
X, y = fetch_openml(data_id=40945, as_frame=True, return_X_y=True)
categorical_features = ["sex", "embarked"]
numerical_features = ["age", "sibsp", "parch", "fare", "pclass"]
X = X[categorical_features + numerical_features]
seed = 42
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=seed)
(3)前処理のためのパイプラインを構築します。
numerical_transformer= Pipeline(
steps=
[
("imputer", SimpleImputer(strategy="mean")),
("scaler", StandardScaler())
]
)
categorical_transformer = Pipeline(
steps =
[
("imputer", SimpleImputer(strategy="most_frequent")),
('onehot', OneHotEncoder(drop='if_binary'))
]
)
transformer = ColumnTransformer(
[
("cat", categorical_transformer, categorical_features),
("num", numerical_transformer, numerical_features),
],
)
(4)分類器と前処理を行うtransformerを結合させたパイプラインを作ります。
def pipeline(transformer,estimator):
model = Pipeline(
[
("transformer", transformer),
("classifier", estimator)
]
)
return modelメタモデル
まずはスタッキングの基本となるメタモデルの概念について説明します。
アンサンブル学習の基本は、複数のモデルの予測結果の多数決、もしくは平均をとることでした。
しかし、モデルによって精度に差がある場合、精度が良さそうなモデルの予測結果は精度が悪いモデルの予測結果よりも精度への貢献度を大きくしたいものです。
アンサンブル学習(多数決・平均)の記事では、最後の方に“おまけ”で人為的にモデルの重みを変更して加重平均をとることをやりました。
その重みを設定する行為を学習して行うのがメタモデルの基本的な考え方です。
各モデルの予測結果をメタモデルの特徴量とすることでそれを実現します。
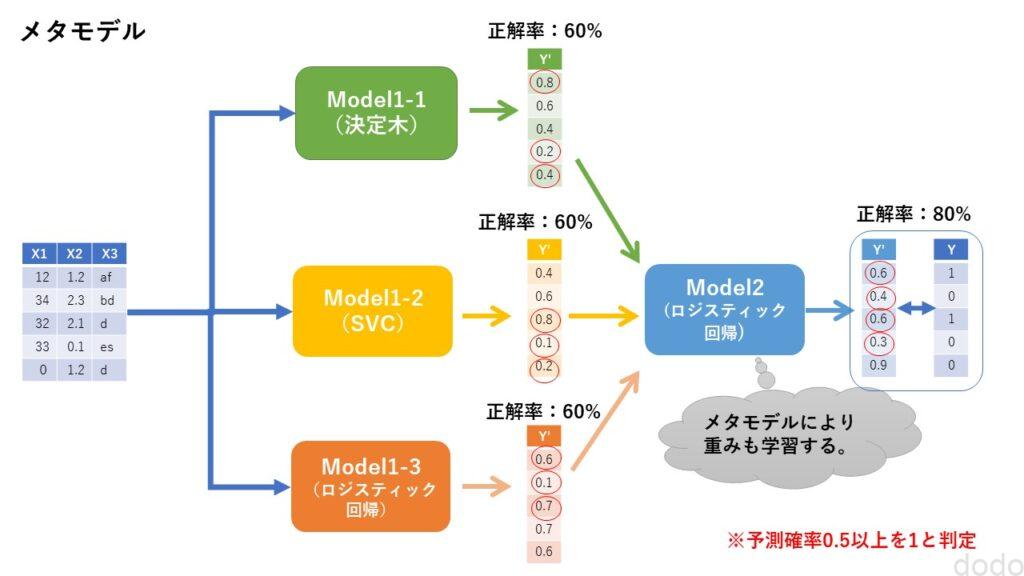 メタモデル
メタモデル
以下、メタモデルを実現する簡単な分類器を作成します。
class SimpleMetaClassifier(BaseEstimator, ClassifierMixin):
def __init__(self, estimators, meta_estimaator, random_state=0):
self.estimators = estimators
self.meta_estimaator = meta_estimaator
self.random_state = random_state
def fit(self, X, y):
#第一層と第二層(メタモデル)を同じデータで学習している。
X_meta = np.empty([len(y),len(self.estimators)])
#第一層のモデルで学習
for i, estimator in enumerate(self.estimators):
estimator.fit(X, y)
X_meta[:,i] = estimator.predict_proba(X)[:,0]
#第一層の予測結果を結合してメタモデルに入力して学習させる。
self.meta_estimaator.fit(X_meta, y)
return self
def predict_proba(self, X):
X_meta = np.empty([len(X),len(self.estimators)])
for i, estimator in enumerate(self.estimators):
X_meta[:,i] = estimator.predict_proba(X)[:,0]
pred_proba = self.meta_estimaator.predict_proba(X_meta)
return pred_proba
def predict(self, X):
pred = np.argmax(self.predict_proba(X), axis=1)
#yの型に戻す(ClassifierMixinでのscore計算のため)
pred = pred.astype(str)
return pred
fitの処理では、複数のモデルで学習した後、その分類器の予測結果を入力したメタモデルでさらに学習しています。
実際に3つの分類器(決定木、SVC、ロジスティック回帰)の予測結果を結合して、第二層のロジスティック回帰の入力としてモデルを作成する例を以下に示します。(3つのモデルの予測結果なのでメタモデルの特徴量の数は3です。)
est1 = DecisionTreeClassifier(random_state=seed)
est2 = SVC(random_state=seed, probability=True)
est3 = LogisticRegression(random_state=seed)
meta_est = LogisticRegression(random_state=seed)
stacking_model = pipeline(transformer,SimpleMetaClassifier([est1, est2, est3], meta_est, seed))
stacking_model.fit(X_train, y_train)
print(f"train score = {stacking_model.score(X_train,y_train)}")
print(f"test score = {stacking_model.score(X_test,y_test)}")実行結果
train score = 0.9724770642201835
test score = 0.7652439024390244
教師データの精度は良いことから「良く」学習はしているようですが、テストデータの精度の結果を見ると過学習していることがわかります。
過学習している最大の理由は、第一層と第二層(メタモデル)で同じデータを使用して学習していることです。
スタッキング
スタッキングでは、第一層と第二層(メタモデル)で学習するデータを分けます。
学習のプロセスは以下のとおりです。
- 教師データを2つに分割する。(A、Bとする)
- Aを第一層のモデルの学習に使用する。
- ❷で学習済みの第一層のモデルにBを入力して予測させる。
- ❸の予測データを入力して第二層(メタモデル)の学習に使用する。
以下に学習のイメージを掲載します。
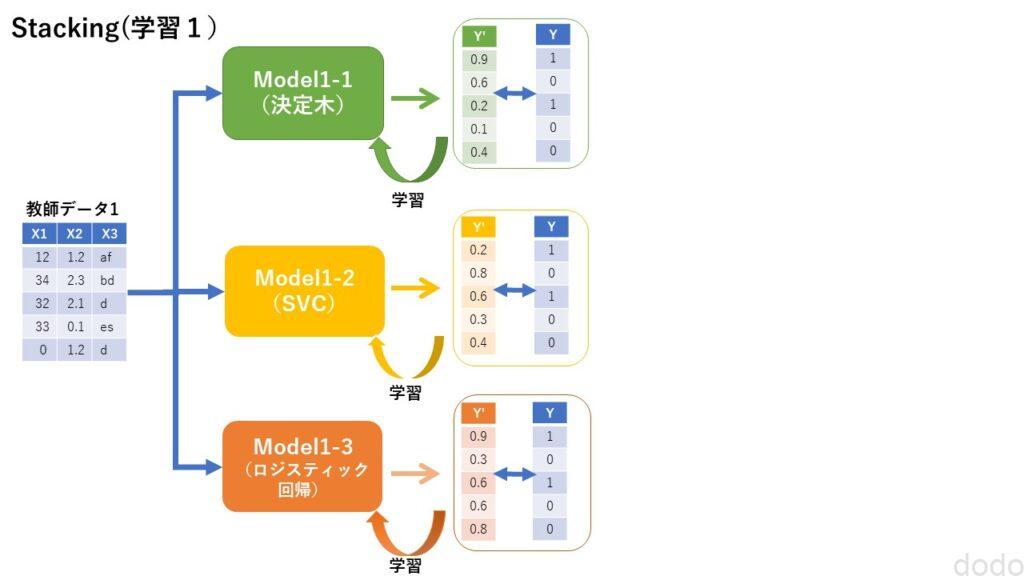 スタッキング(第一層の学習)
スタッキング(第一層の学習)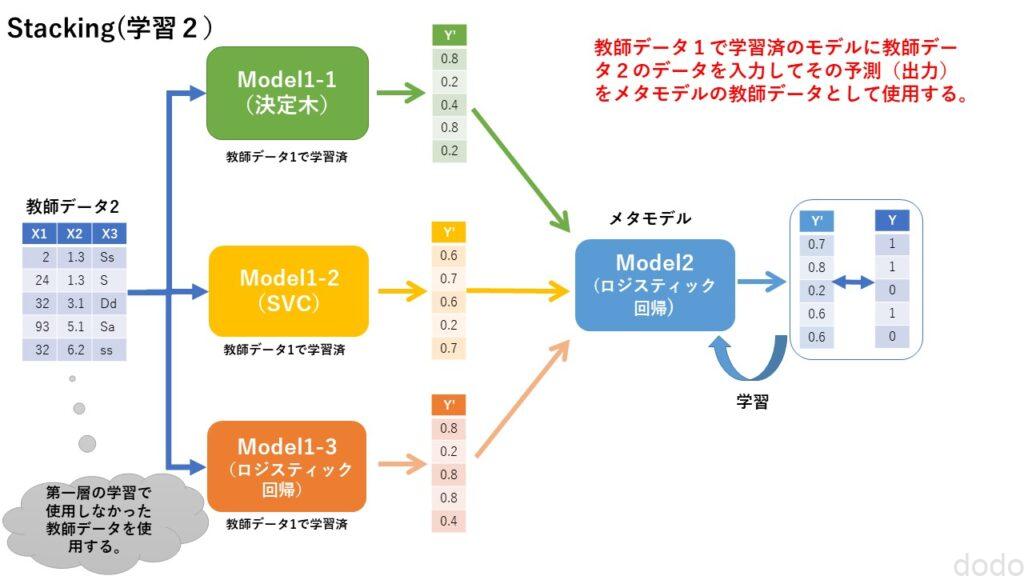 スタッキング(メタモデルの学習)
スタッキング(メタモデルの学習)
そして学習済みの第一層のモデル、第二層のメタモデルを組み合わせて予測を実施します。
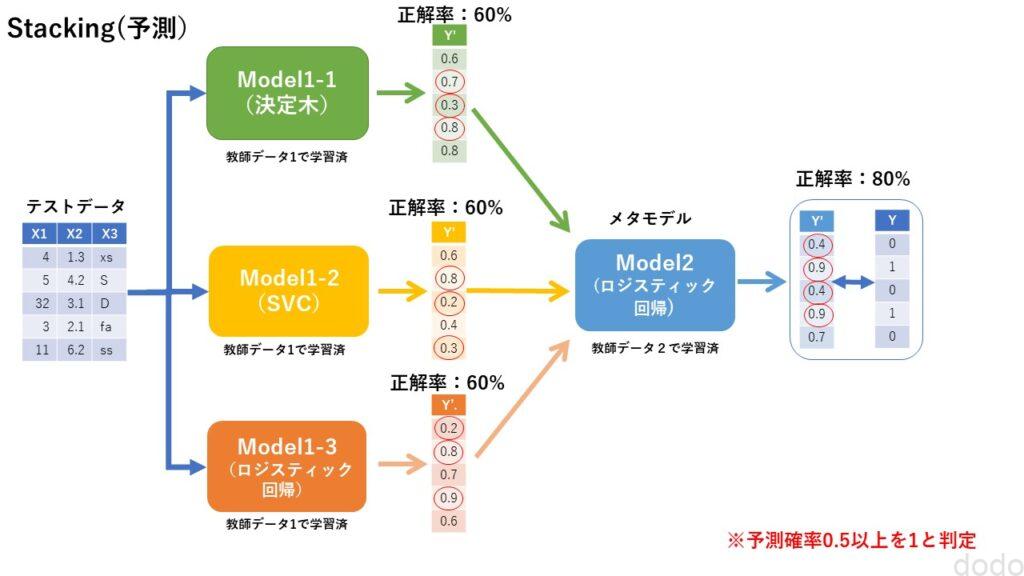 スタッキング(予測)
スタッキング(予測)
このイメージにもとづいてスタッキングの分類器を作成します。
class SimpleStackingClassifier(BaseEstimator, ClassifierMixin):
def __init__(self, estimators, meta_estimaator, random_state=0):
self.estimators = estimators
self.meta_estimaator = meta_estimaator
self.random_state = random_state
def fit(self, X, y):
X1, X2, y1, y2 = train_test_split(X, y, stratify=y, random_state=self.random_state)
X_meta = np.empty([len(y2),len(self.estimators)])
for i, estimator in enumerate(self.estimators):
estimator.fit(X1, y1)
X_meta[:,i] = estimator.predict_proba(X2)[:,0]
self.meta_estimaator.fit(X_meta, y2)
return self
def predict_proba(self, X):
X_meta = np.empty([len(X),len(self.estimators)])
for i, estimator in enumerate(self.estimators):
X_meta[:,i] = estimator.predict_proba(X)[:,0]
pred_proba = self.meta_estimaator.predict_proba(X_meta)
return pred_proba
def predict(self, X):
pred = np.argmax(self.predict_proba(X), axis=1)
#yの型に戻す(ClassifierMixinでのscore計算のため)
pred = pred.astype(str)
return pred
fit内の処理では、教師データを分割して、一方を第一層の学習に使用し、もう一方を第二層(メタモデル)の学習に使用しています。
この分類器を使用して、3つの分類器(決定木、SVC、ロジスティック回帰)の予測結果を結合して、第二層のロジスティック回帰の入力とするモデルを作成します。
est1 = DecisionTreeClassifier(random_state=seed)
est2 = SVC(random_state=seed, probability=True)
est3 = LogisticRegression(random_state=seed)
meta_est = LogisticRegression(random_state=seed)
stacking_model = pipeline(transformer,SimpleStackingClassifier([est1, est2, est3], meta_est, seed))
stacking_model.fit(X_train, y_train)
print(f"train score = {stacking_model.score(X_train,y_train)}")
print(f"test score = {stacking_model.score(X_test,y_test)}")実行結果
train score = 0.8267074413863404
test score = 0.8414634146341463
実行結果からメタモデルの教師データを分けることによって、過学習が抑えられていることがわかります。
スタッキング(交差検証版)
上記のスタッキングの実装では、第一層の教師データと第二層の教師データを完全に分離しましたが、より良い方法として教師データを交差検証の手法により分割する方法があります。
例として教師データを3分割(A、B、C)するとします。
すると1つの分類器につき、ABで学習したモデル1、ACで学習したモデル2、BCで学習したモデル3の3つが出来上がります。(3つの分類器でアンサンブルする場合は3✖️3=9個のモデルが出来上がります。)
ABで学習したモデル1でCを予測、ACで学習したモデル2でBを予測、BCで学習したモデル3でAを予測して、それを結合して第二層の入力とすれば、第一層で学習に使用していないデータ(このデータをOOF「Out-Of-Fold」といいます。)で第二層のメタモデルを学習することになり、しかも教師データを全て学習に使用できることになります。
上記のイメージで分類器を作成してみましょう。
class CVStackingClassifier(BaseEstimator, ClassifierMixin):
def __init__(self, estimators, meta_estimaator, predict_method='all', random_state=0, n_cv_splits=5):
self.estimators = estimators
self.meta_estimaator = meta_estimaator
self.predict_method = predict_method
self.random_state = random_state
self.n_cv_splits = n_cv_splits
def fit(self, X, y):
y = y.to_numpy()
if self.predict_method == 'all':
#予測用に教師データ全体に対して学習
self.estimators_ = []
for estimator in self.estimators:
fitted_estimator = copy.deepcopy(estimator).fit(X,y)
self.estimators_.append(fitted_estimator)
X_meta = np.empty([len(y),len(self.estimators)])
sf = StratifiedKFold(n_splits=self.n_cv_splits)
self.all_estimators_ = []
for i, estimator in enumerate(self.estimators):
cv_estimators = []
#交差検証
for train_index, test_index in sf.split(X,y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
#CVごとに未学習の状態の学習器をコピーして学習する
cv_estimator = copy.deepcopy(estimator)
cv_estimator.fit(X_train, y_train)
#交差検証によって学習に使用していないデータによる予測結果のみ蓄積される。
X_meta[test_index,i] = cv_estimator.predict_proba(X_test)[:,0]
cv_estimators.append(cv_estimator)
self.all_estimators_.append(cv_estimators)
#学習に使用していないデータをメタモデルの学習に使用する。
self.meta_estimaator.fit(X_meta, y)
return self
def predict_proba(self, X):
X_meta = np.empty([len(X),len(self.estimators)])
if self.predict_method == 'all':
#fself.estimatorsではなく、self.estimators_(fitで学習済)を使用していることに注意
for i, estimator in enumerate(self.estimators_):
X_meta[:,i] = estimator.predict_proba(X)[:,0]
elif self.predict_method == 'mean':
#CVモデルを全体に適用して、その平均を該当するモデルの予測結果とする。
for i, cv_estimators in enumerate(self.all_estimators_):
#CVモデルを全体に適用して、その平均を該当するモデルの予測結果とする。
X_meta[:,i] = np.mean([cv_estimator.predict_proba(X)[:,0] for cv_estimator in cv_estimators],axis=0)
else:
raise ValueError(f'predict_method value is incorrect {self.predict_method}')
pred_proba = self.meta_estimaator.predict_proba(X_meta)
return pred_proba
def predict(self, X):
pred = np.argmax(self.predict_proba(X), axis=1)
#yの型に戻す(ClassifierMixinでのscore計算のため)
pred = pred.astype(str)
return pred
fit内でStratifiedKFoldを使用して教師データを分割して、第一層のモデルを作成します。その後、モデルの学習に使用しなかったデータを用いて予測し、それをデータとして結合して第二層の入力としています。(正確には、さらにそれを分類器の数だけ特徴量として結合しています。)
交差検証のためのモデルを作成する場合に元の分類器のインスタンスをディープコピーしています。(ディープコピーを実施しないと、同じインスタンスを操作ことになってしまいます。)
上記のスタッキング分類器を使用した場合は呼び出し元で引数として渡される分類器には影響しません。(学習済にならない。)
(本来、これまでこのシリーズで作成していた分類器でもディープコピーした方が良いです・・)
なお、交差検証を利用してスタッキングモデルを作成した場合、予測には工夫が必要です。
上記の実装では、2パターンの予測方法を引数によって変更できるようにしました。
predict_method=’mean’にした場合
交差検証で分割した数だけ作成されるモデルを全て用いて、全体のデータを使用して予測します。
そしてその平均をそれを第二層(メタモデル)の入力とします。
predict_method=’all’にした場合
交差検証とは関係なく、引数で与えられた分類器のインスタンスで全体のデータを使用して予測して、それを第二層(メタモデル)の入力とします。
なお、predict_method=’all’を使用するためには交差検証で分割したモデルでハイパーパラメータを変更していないことが前提です。
predict_method=’all’のやり方は乱暴のように見えるかもしれません。
しかし本来、交差検証ではハイパーパラメータを数パターン試して、最も良い精度だったモデルのハイパーパラメータで全体のデータを学習してモデルを作成します。
なので全てのモデルのハイパーパラメータが同じならば、そのハイパーパラメータで全教師データを学習したモデルを用いて予測を実施してもおかしなことではありません。
ちなみにpredict_method=’all’しか使用しないならば、fitでの交差検証の実装はもっとシンプルにできます。
sklearn.model_selectionのcross_val_predictを使用すれば、学習に使用しなかったデータでの予測結果を結合して出力してくれます。
今回、使用しなかったのは、predict_method=’mean’の場合、交差検証の各モデルが予測時に必要で保存しておく必要があったからです。
では実際に作成した分類器を使用してみましょう。
まずはpredict_method=’mean’として実行します。
est1 = DecisionTreeClassifier(random_state=seed)
est2 = SVC(random_state=seed, probability=True)
est3 = LogisticRegression(random_state=seed)
meta_est = LogisticRegression(random_state=seed)
cv_stacking_model = pipeline(transformer,CVStackingClassifier(
estimators=[est1, est2, est3],
meta_estimaator=meta_est,
predict_method='mean',
random_state=seed))
cv_stacking_model.fit(X_train, y_train)
print(f"train score = {cv_stacking_model.score(X_train,y_train)}")
print(f"test score = {cv_stacking_model.score(X_test,y_test)}")
実行結果
train score = 0.8226299694189603
test score = 0.8414634146341463
交差検証をしない場合に比べて、良い結果が出るかと思いましたが、数値的には全く同じ結果でした・・(一つ一つのサンプルを見ると違う結果が出ています。)
まあ、こういうこともあるでしょう・・
次にpredict_method=’all’として実行します。
est1 = DecisionTreeClassifier(random_state=seed)
est2 = SVC(random_state=seed, probability=True)
est3 = LogisticRegression(random_state=seed)
meta_est = LogisticRegression(random_state=seed)
cv_stacking_model = pipeline(transformer,CVStackingClassifier(
estimators=[est1, est2, est3],
meta_estimaator=meta_est,
predict_method='all',
random_state=seed))
cv_stacking_model.fit(X_train, y_train)
print(f"train score = {cv_stacking_model.score(X_train,y_train)}")
print(f"test score = {cv_stacking_model.score(X_test,y_test)}")
実行結果
train score = 0.8287461773700305
test score = 0.8384146341463414
テストデータの精度は、predict_method=’mean’の方が良い精度が出ていました。
データや分類器の種類などでも結果は違うと思うので、余裕のある方はいろいろと試してみてください。
なお、sckit-learnには、StackingClassifierという分類器クラスが存在します。(当たり前ですがこちらを使いましょう。上記のスクラッチ実装はあくまでもお試しです。)
StackingClassifierを使用して同じアンサンブルモデル、メタモデルで試してみましょう。
est1 = DecisionTreeClassifier(random_state=seed)
est2 = SVC(random_state=seed, probability=True)
est3 = LogisticRegression(random_state=seed)
meta_est = LogisticRegression(random_state=seed)
sk_stacking_model = pipeline(transformer,StackingClassifier(estimators=[
('est1', est1), ('est2',est2), ('est3', est3)],
final_estimator=meta_est, cv=5))
sk_stacking_model.fit(X_train, y_train)
print(f"train score = {sk_stacking_model.score(X_train,y_train)}")
print(f"test score = {sk_stacking_model.score(X_test,y_test)}")実行結果
train score = 0.8287461773700305
test score = 0.8384146341463414
私が作成したスタッキング分類器でpredict_method=’all’とした場合と全く同じ結果になりました。
実は、実際にやってることは全く同じで、StackingClassifierではpredict_method=’all’のロジックにしか対応しておらず、また上記で交差検証の分割数は5を指定しています。(実はデフォルトで引数を指定しない場合も交差検証で5分割です。)
もちろん、他にもさまざまなオプションを指定できるので、興味のある方はいろいろと試してみてください。
なお、ここまで当たり前のようにメタモデルを第二層としていましたが、第二層までで限定しているわけではなく、何層も積み上げるケースもあります。
つまり第二層で複数のメタモデルを作成して、さらに第三層のメタメタモデルの入力にして、さらに・・・というケースです。
StackingClassifierは可変な層には対応していませんが、以下のようにすれば無理やり実施することも可能です。(以下、あくまで参考です。)
st1 = DecisionTreeClassifier(random_state=seed)
est2 = SVC(random_state=seed, probability=True)
est3 = LogisticRegression(random_state=seed)
meta_est1 = DecisionTreeClassifier(random_state=seed)
meta_est2 = SVC(random_state=seed, probability=True)
meta_est3 = LogisticRegression(random_state=seed)
metameta_est = LogisticRegression(random_state=seed)
sk_stacking_model1 = StackingClassifier(estimators=[
('est1', est1), ('est2',est2), ('est3', est3)],
final_estimator=meta_est1)
sk_stacking_model2 = StackingClassifier(estimators=[
('est1', est1), ('est2',est2), ('est3', est3)],
final_estimator=meta_est2)
sk_stacking_model3 = StackingClassifier(estimators=[
('est1', est1), ('est2',est2), ('est3', est3)],
final_estimator=meta_est3)
sk_stacking_model = pipeline(transformer,StackingClassifier(estimators=[
('meta_est1', sk_stacking_model1),
('meta_est2', sk_stacking_model2),
('meta_est3', sk_stacking_model3)],
final_estimator=metameta_est))
sk_stacking_model.fit(X_train, y_train)
print(f"train score = {sk_stacking_model.score(X_train,y_train)}")
print(f"test score = {sk_stacking_model.score(X_test,y_test)}")
実行結果
train score = 0.8287461773700305
test score = 0.8384146341463414
ただ、使っているデータでは予測結果は全く改善しませんでした・・これ以上はデータの前処理とモデル選択に依存する部分が多いのだと思います。
なお、第一層の学習が冗長であることなど、無駄が多いので、実際に(実用で)やる場合はもっと工夫が必要です。
ブレンディングという言葉を聞いたことがある方もいらっしゃるかと思います。
スタッキングとブレンディングを分けて定義している本やサイトもあります。
ただし、この区分けは、かなり曖昧です。
交差検証をしない場合をブレンディング、交差検証をする場合をスタッキングと言う場合や、第二層までの場合をブレンディング、第三層以降を使用する場合をスタッキングと言う場合があります。
ややこしいので、本記事では全てスタッキングという用語で統一しました。
まとめ
以上、スタッキングについて解説、実装をしてきました。
4回連続で、アンサンブル学習について記事を書いてきましたが、今回のスタッキングで終了です。
アンサンブル学習はKaggleのように少しでも高い精度を出すモデルを競い合うプラットフォームでは必須の手法となっております。
以下のリンク先は、Jeong Yoon Leeという方がKDD Cupと言う競技サイトで優勝した時のスタッキングモデルについての説明が記載されています。(英語です。)

この例では、第一層に64個、第二層に15個、第三層に2個、第四層に1個のモデルを使用してスタッキングを実行しています。(使用しているアルゴリズムも8種類、ハイパーパラメータ、教師データなどもバリエーションがあります。)
実業務ではここまでやることはありませんが、手法自体については学んでおいても損はないでしょう。
一連の記事が基本的な考え方と手法についての整理のために少しでもお役に立てれば幸いです。

