










今回は、アンサンブル学習の中でもブースティングについて説明・実装していきます。
過去のアンサンブル学習については以下をご参照ください。

なお、ブースティングには大きく分けて、AdaBoostと勾配ブースティングがありますが、今回、実装する例はAdaBoostのみとします。
事前準備
前回とほぼ同様ですが、importしているライブラリが異なります。
前提条件
本ソースコードは、Python3.10.6で起動するJupyter Lab上で実行されています。
また使用している各ライブラリのバージョンは以下の通りです。
- numpy(1.22.4)
- pandas(1.4.3)
- scikit-learn (1.1.2)
タイタニックデータ取得+前処理
今回もタイタニックのデータを使用します。
今更ですが、このアンサンブルシリーズ、タイタニックデータを使っている意味がなく(精度しか出さないし)、各モデルの決定境界とかを可視化できるようなもっと単純なデータを使えば良かったと後悔しています・・
データの取得と前処理については、以下の記事に詳細を記載しているため、今回はソースコードのみを掲載します。

(1)必要なライブラリをインポートします。
import numpy as np
import pandas as pd
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler,OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.base import ClassifierMixin,BaseEstimator
import warnings
warnings.simplefilter('ignore')
(2)データを読み込んで教師データとテストデータに分割します。
X, y = fetch_openml(data_id=40945, as_frame=True, return_X_y=True)
categorical_features = ["sex", "embarked"]
numerical_features = ["age", "sibsp", "parch", "fare", "pclass"]
X = X[categorical_features + numerical_features]
seed = 42
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=seed)
(3)前処理のためのパイプラインを構築します。
numerical_transformer= Pipeline(
steps=
[
("imputer", SimpleImputer(strategy="mean")),
("scaler", StandardScaler())
]
)
categorical_transformer = Pipeline(
steps =
[
("imputer", SimpleImputer(strategy="most_frequent")),
('onehot', OneHotEncoder(drop='if_binary'))
]
)
transformer = ColumnTransformer(
[
("cat", categorical_transformer, categorical_features),
("num", numerical_transformer, numerical_features),
],
)ブースティング
バギングでは複数の学習器はそれぞれ独立でした。
しかしブースティングは、1つの学習器で学習した結果を別の学習器に反映させます。
複数の学習器を順番に学習させていく時に、前の学習器で予測を誤ったデータを次の学習器で重点的に学習させます。
最終的には全ての学習器の予測結果について、そのモデルの重み(誤り率から算出)に応じた加重平均(もしくは多数決)をとって予測結果を算出します。
AdaBoost
AdaBoostは、ブースティング手法のうちの一つです。
AdaBoostの基本的な考え方は以下の通りです。
- 各データの重みの初期値を設定する。
(初期値はデータ数分の1) - 最初の学習器で学習する。
- 学習器の予測結果から重み付き誤り率を算出する。
(データの重みが大きいデータの誤りを大きくする。) - 重み付き誤り率から学習器の重みを更新する。
(誤り率が小さいほど大きい) - 予測を誤ったデータの重みを更新する。
(誤ったデータの重みが大きくなる。) - 次の学習器にて重みが大きいデータを重点的に学習する。
- ❸ から❻を学習器の数だけ繰り返す。
(→学習器の完成) - それぞれの学習器の予測結果に、それぞれの学習器の重みをかけた値で加重平均(多数決)を取り、予測結果とする。
学習と予測のイメージ図を以下に掲載します。
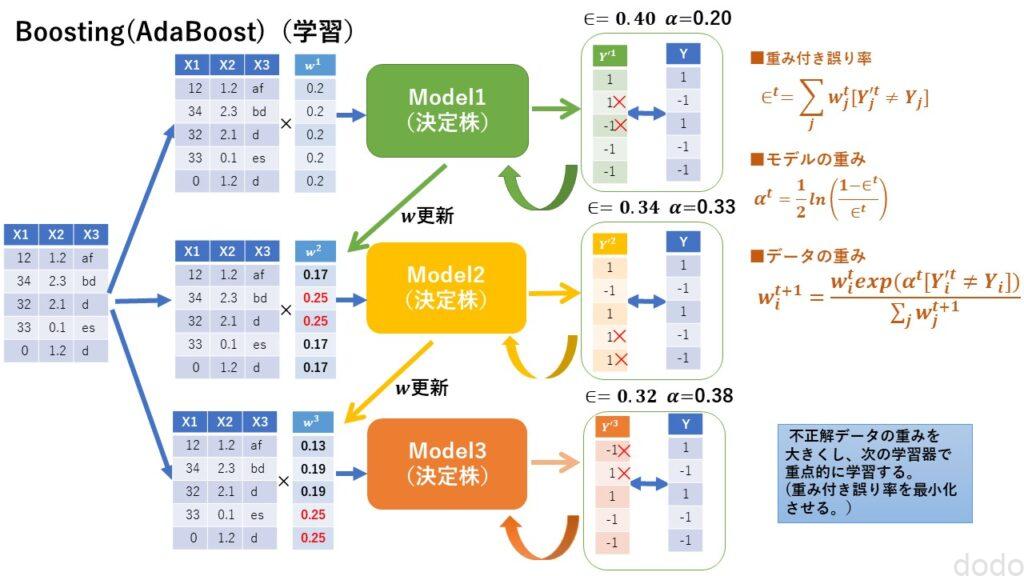 AdaBoost(学習)
AdaBoost(学習)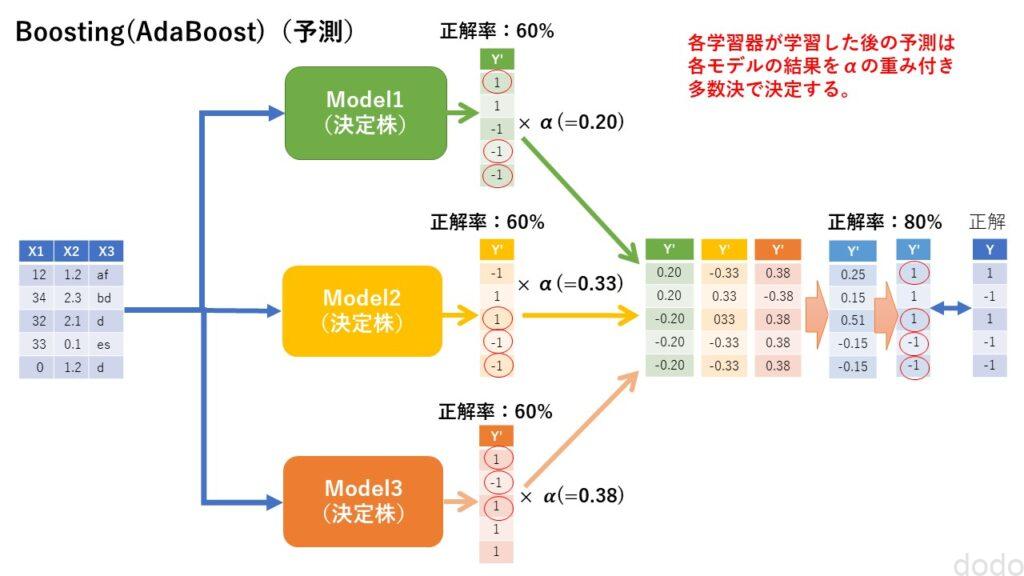 AdaBoost(予測)
AdaBoost(予測)
なお、AdaBoostでは学習器として決定株(深さ1の決定木)を使用します。
スクラッチで実装
それでは実際に実装して行きましょう。
まずは頑張ってスクラッチで実装します。
前回と同様、分類器と前処理を行うtransformerを結合させたパイプラインを作ります。
def pipeline(transformer,estimator):
model = Pipeline(
[
("transformer", transformer),
("classifier", estimator)
]
)
return model
そして、AdaBoostの分類器を作成します。
ソースコードは以下となります。
class PseudoAdaBoostClassifier(BaseEstimator, ClassifierMixin):
def __init__(self, n_estimators, random_state=0):
self.n_estimators = n_estimators
self.seed = random_state
def fit(self, X, y):
#numpyに揃える
y = y.to_numpy().astype(int)
size = len(y)
self.estimators_ = []
self.alphas_ = []
#各モデルで使用するシードを生成
base_random_state = np.random.RandomState(self.seed)
rndarr = base_random_state.randint(np.iinfo(np.int32).max, size=self.n_estimators)
#重みの初期値
alpha = 1 #万が一最初っから全て正解の場合のみ使用
weights = np.array([1 / size for _ in range(size)])
#重みの初期値の累積和
cumsum_weights = np.cumsum(weights)
for i in range(self.n_estimators):
model = DecisionTreeClassifier(max_depth=1, random_state=rndarr[i])
#ブートストラップにより擬似的にエラーになったデータを重点的に学習
if i > 0:
#モデル毎のシード生成
random_state = np.random.RandomState(rndarr[i])
#重みの累積和の値をもとにブートストラップするための乱数(0-1)
rnds = random_state.uniform(0,1,size)
#重みの累積和からブートストラップするためのインデックスを取得
indexs = [PseudoAdaBoostClassifier.__get_index(
cumsum_weights, rnd, 0, self.n_estimators, self.n_estimators)
for rnd in rnds]
#教育データをサンプリングして学習、予測
re_X, re_y = X[indexs], y[indexs]
model.fit(re_X, re_y)
else:
model.fit(X, y)
#予測は全データで実施
y_predict = model.predict(X)
#誤りから重みを更新する(全て正解の場合は更新しない)
errors = (y_predict != y).astype(int)
if sum(errors) != 0:
#重みを更新、モデルの重み(alpha)を取得
alpha, weights = PseudoAdaBoostClassifier.__get_weights(weights, errors)
cumsum_weights = np.cumsum(weights)
#モデルとモデルの重みをリストに保存
self.estimators_.append(model)
self.alphas_.append(alpha)
return self
def predict(self, X):
base_pred = [np.where(model.predict(X).astype(int)==0 ,-1 ,1) for model in self.estimators_]
weight_pred = np.array(self.alphas_).reshape(self.n_estimators,1) * base_pred
pred = np.sign( np.sum(weight_pred, axis=0))
#yの型に戻す(ClassifierMixinでのscore計算のため)
pred = np.where(pred == -1, '0', '1')
return pred
@staticmethod
def __get_weights(pre_weights, errors):
error_rate = sum(pre_weights * errors) /sum(pre_weights)
alpha = 1/2 * np.log((1-error_rate)/error_rate)
#エラーの方が多かったらスキップ
if alpha < 0:
alpha = 0
weights = pre_weights
else:
weights = pre_weights * np.exp(alpha * errors)
weights = weights / np.sum(weights)
return alpha, weights
@staticmethod
def __get_index(cumsum_arr, num, i0, i1, imax):
i = (i1 + i0) // 2
if num > cumsum_arr[i]:
if i == imax:
return i
elif num <= cumsum_arr[i+1] or i+1 == imax:
return i+1
else:
return PseudoAdaBoostClassifier.__get_index(
cumsum_arr, num, i, i1, imax)
else:
if i == 0:
return i
elif num > cumsum_arr[i-1] or i-1 == 0:
return i
else:
return PseudoAdaBoostClassifier.__get_index(
cumsum_arr, num, i0, i, imax)
基本的には、上で説明した通りに実装しただけですが、誤ったデータ(重みを大きくしたデータ)を次の分類器で重点的に学習するロジックはトリックを使っています。
これを真面目に実装すると決定株の中のロジックまで踏み込む必要がありますが、今回はそれをしないで疑似的に実現させています。
その疑似的な方法とは、2つ目以降の決定株の教師データをブートストラップを用いて抽出し、その時に重みが大きいデータが選ばれる確率を高くする方法です。
仮に3件しかデータがないと仮定してそれぞれの重みがそれぞれ0.1、0.6、0.3だったとします。
この時、1番目から累積和を取ると0.1、0.7、1.0となります。
一様分布で0から1の範囲で乱数(R)を発生させ、0<R≦0.1の場合は1番目のデータが選ばれ、0.1<R≦0.7の場合は2番目のデータが選ばれ、0.7<R≦1.0の場合は3番目のデータが選ばれるようにします。
このようにすれば、範囲が狭い1番目のデータよりも3番目のデータの方が、3番目のデータよりも2番目のデータの方がブートストラップで選ばれる確率が高くなります。
なお、本分類器は、他にも例外処理など甘い箇所が多くあり、あくまでもAdaBoostのロジックのお試し実装なのでご注意ください。(ラベルも’0’、’1’であることを前提としています。)
とは言え、実際に使用して実行結果を見てみましょう。
psudo_adb_model =pipeline(transformer,PseudoAdaBoostClassifier(n_estimators=100, random_state=seed))
psudo_adb_model.fit(X_train, y_train)
print(f"train score = {psudo_adb_model.score(X_train,y_train)}")
print(f"test score = {psudo_adb_model.score(X_test,y_test)}")実行結果
train score = 0.7737003058103975
test score = 0.7987804878048781
適当に作った割には、まあまあの精度が出ています。(過学習もしていません。)
AdaBoostClassifierで実装
次にscikit-learn標準のAdaBoostClassifierで試してみましょう。
ab_model =pipeline(transformer,AdaBoostClassifier( n_estimators=100, random_state=seed))
ab_model.fit(X_train, y_train)
print(f"train score = {ab_model.score(X_train,y_train)}")
print(f"test score = {ab_model.score(X_test,y_test)}")実行結果
train score = 0.8103975535168195
test score = 0.8079268292682927
若干、私がスクラッチで作成した分類器よりも良い精度が出ています。(そして何より実行時間が早い・・)
また、パラメータでは学習率(デフォルトは1)を設定できて、モデルの重みを順次更新していくときにその重みを調整することができます。以下、0.1として実行します。
ab_model =pipeline(transformer,AdaBoostClassifier(n_estimators=100, learning_rate = 0.1, random_state=seed))
ab_model.fit(X_train, y_train)
print(f"train score = {ab_model.score(X_train,y_train)}")
print(f"test score = {ab_model.score(X_test,y_test)}")実行結果
train score = 0.7981651376146789
test score = 0.8109756097560976
過学習が抑えられテストデータでの予測精度が向上しています。
まとめ
以上、AdBoostについてスクラッチ実装とscikit-learnによる実装を試しました。
なお、最初にも記載しましたが、ブースティングには、勾配ブースティングという手法もあり、こちらの手法は、予測結果と実際の値の差を学習することによって、それを差っ引いていくという方法です。
scikit-learnのGradientBoostingClassifierや手法を改善させたCatBoostClassifier、XGBClassifier、LGBMClassifierなどのライブラリがあるので興味ある方は試して見てください。
(本当は勾配ブースティングについても記述するつもりでしたが、AdaBoostだけで力尽きました・・)
次回(?)は、最後、スタッキングについて、解説、実装していきたいと思います。(間に他の記事を挟む可能性があります。)


