









機械学習でのモデルの選定は悩ましく、実際の業務でもついつい「決め打ち」でモデルを決めてしまう事があるかと思います。
ただし、本来、ファーストステップとしては「標準のパラメータ」で、データの一部(膨大なデータ量の場合)だけを使っても良いので「とりあえず」タイプの異なる様々なモデルで評価して、モデル同士を比較した上で、モデルを選定するべきです。
本記事では、データセット「MNIST」を使って、「とりあえず」いくつかのモデルで評価した結果について記載します。
前提条件
掲載するソースコードは以下がインストールされている環境で実行しています。
- scikit-learn (0.22.2)
- xgboost (1.0.2)
- matplotlib(3.0.3)
MNIST
MNIST(Mixed National Institute of Standards and Technology database)は、手書き数字の機械学習データセットで、画像データ解析の入門用データとしてよく使用されています。
python+scikit-learnで、以下を実行することによりダウンロードする事ができます。
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1,)sckit-learnの0.24以上のバージョンでは、mnisit.dataがデフォルトでpandasのDataFrameになります。以下のコードをそのまま動かすためには、fetch_openmlに対して「as_frame=False」の引数が必要です。
mnist.dataには画像データ(28px*28pxの画像を784列のデータとして格納)、mnist.targetにはラベル(0〜9)が格納されており、データ数は70,000件となっています。(「print(mnist.data.shape)」を実行すると「(70000, 784)」と表示されます。)
先頭の10個のデータを可視化すると以下のようになります。
%matplotlib inline
import matplotlib.pyplot as plt
fig, ax = plt.subplots(2, 5,figsize=(10, 5))
for i in range(0,10):
r = i // 5
c = i % 5
ax[r,c].set_xticks([])
ax[r,c].set_yticks([])
ax[r,c].set_title(mnist.target[i],fontsize=30)
ax[r,c].imshow(mnist.data[i].reshape(28, 28), cmap='Greys')
plt.savefig("./mnist_10.png")
plt.show() mnistサンプル
mnistサンプル教師データ、テストデータを抽出
最初から70,000件を対象にして、モデルを選定しようとすると時間がかかり過ぎてしまいます。全てのデータを分析に使用するのは、モデル選定の後で良いので、「とりあえず」の評価のために、教師データを1000件、テストデータを300件を抽出します。
from sklearn.model_selection import train_test_split
#実行するたびに結果が変わらないようにseedを固定する。
seed = 0
#「とりあえず」の評価なので、教師データは1000個、テストデータは300個とし、ラベルにより層化抽出する。)
X_train, X_test, y_train, y_test
= train_test_split(mnist.data,
mnist.target,
test_size=300,
train_size=1000,
random_state=seed,
stratify=mnist.target)
#0から255までの値なので255で割って規格化する。
X_train = X_train /255
X_test = X_test /255
なお、ラベルの割合は教師データとテストデータで均一になるように「stratify=mnist.target」により層化抽出(比例配分)しています。
一度、教師データとテストデータを分割したら、テストデータは基本的に見てはいけません。可視化も教師データに対してのみ実施します。
テストデータを見る事によって人間が無意識のうちにテストデータにフィットするようなモデルを生成してしまう事があります。(これをデータスヌーピングバイアス(data snooping bias)と言います。)
9つの分類器で評価する。
以下、9つの分類器を交差検証することにより評価します。
- サポートベクターマシン(RBFカーネル)
- 線形サポートベクターマシン
- ランダムフォレスト
- XGBoost
- ロジスティック回帰
- 決定木
- K近傍法
- アダブースト
- ニューラルネットワーク(隠れ層は1つ (784→100→10))
これらを使用するために各ライブラリをインポートします。
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import RandomizedSearchCV
まずは、分類器を名前をキーとしてディクショナリーに格納します。
classifiers = {
#サポートベクターマシン(カーネルはRBF)
"SVM":SVC(gamma="auto", random_state=seed),
#線形サポートベクターマシン
"Liner SVM":SVC(kernel="linear",random_state=seed),
#ランダムフォレスト (木の数は100)
"Random Forest":RandomForestClassifier(random_state=seed),
#XGBoost
"XGBoost":XGBClassifier(random_state=seed),
#ロジスティック回帰(最適化にはliblinearを使用)
"Logistic Regression":LogisticRegression(solver="liblinear", random_state=seed),
#決定木
"Decision Tree":DecisionTreeClassifier(random_state=seed),
#K近傍法(k=5)
"KNeighbors":KNeighborsClassifier(),
#アダブースト(※デフォルトでは決定木の深さが1なので無制限に変更)
"AdaBoost":AdaBoostClassifier(DecisionTreeClassifier(max_depth=None),random_state=seed),
# ニューラルネットワーク(隠れ層は1つでユニット数は100 (784→100→10))
"Neural Network":MLPClassifier(max_iter=300, random_state=seed)
}
それぞれについて、交差検証(10分割)を実行します。
10分割の交差検証では、教師データを10分割して、9割を教師データ、1割を検証データとして、それを10回繰り返して、10回分の検証データの予測精度を検証します。
from sklearn.model_selection import cross_val_score
def get_cv_score(classifiers, X, y, cv=10):
cv_scores = {};
for k,clf in classifiers.items():
cv_scores[k] = cross_val_score(clf, X, y, cv=cv)
return cv_scores
cv_scores = get_cv_score(classifiers, X_train, y_train, 10)
cv_scoresには、それぞれの分類器の10分割分のスコア(精度:Accuracy)が格納されています。
箱ひげ図を使って、スコアを可視化すると以下のようになります。
def show_cv_score(cv_scores,cv):
plt.figure(figsize=(15, 10))
for i, score in enumerate(cv_scores.values()):
plt.plot([i+1]*cv, score, ".")
plt.boxplot([score for score in cv_scores.values()], labels=([k for k in cv_scores]))
plt.ylabel("Accuracy", fontsize=20)
plt.xlabel("Classifiers", fontsize=20)
plt.savefig("./classifiers_score.png",bbox_inches='tight', pad_inches=0)
plt.show()
show_cv_score(cv_scores,10)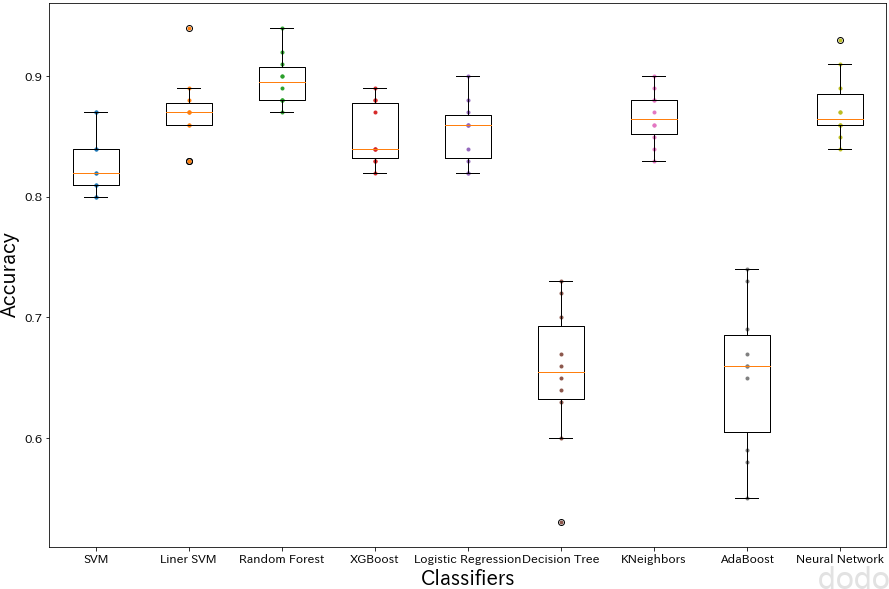 各分類器の比較
各分類器の比較こうして見ると、決定木とアダブーストが極端に精度が悪いです。
おそらく、決定木もアダブーストも真面目にパラメータの最適化をすれば、もっとよくなると思いますが、この段階でとりあえず候補からは外れるかなと思います。
意外に奮闘しているのが、線形モデル(線形SVM、ロジスティック回帰)です。
画像識別でこれだけの精度が出れば、なかなかのものだと思います。
実際の分析でも「それってロジスティック回帰で十分じゃない?」といったケースが多々あります。ただお客さんの中で「そんなのA.Iじゃないだろ!ディープラーニングだ!」「ディープラーニングでやるのが売りなので、ディープラーニングでやって」と言われて、不必要に複雑なモデルを使わなければいけなかったりするケースもあるので、困ったものです・・
今回のケースだと平均的なスコアを見る限り、ランダムフォレストかニューラルネットワーク(まあ、画像だからやっぱりニューラルネットワークかな・・)を掘り下げて行くことになるかと思います。(「とりあえず用」にはscikit-learnを使いましたが、ニューラルネットワークを選択するならば、Tensoflowもしくはkerasを使用した方が良いでしょう。)
テストデータの精度を見る。
実際の業務では、教師データ(+検証データ)で入力データのクレンジング、パラメータサーチをして練り上げたモデルを生成し、最後にそのモデルにテストデータを投入してテストをします。
ですが、ここでは「余興として」9つのモデルそれぞれで、テストデータを投入した場合の精度を見てみることにします。
実際の業務で、テストデータでの精度を判定材料として、モデルの選定をしてはいけません。それは「テストデータの精度」というパラメータを教師データに取り込んでいる事と同義になります。あくまでもモデルの選定は教師データ(+検証データ)で実施します。
教師データ全体でモデルをフィット(学習)させます。
for k,clf in classifiers.items():
clf.fit(X_train, y_train)分割したデータで作成した交差検証の各モデルではなく、交差検証により最適なパラメータを得られた分類器で教師データ全体(検証データを含む)を学習したモデルで、テストデータをテストします。
精度と混同行列を可視化するための関数を定義します。せっかくなので、最新のscikit-learn(>=0.22.0)で追加された「plot_confusion_matrix」を使って見ます。
from sklearn.metrics import (accuracy_score,plot_confusion_matrix)
#全体的に文字を大きくする
plt.rcParams["font.size"] = 18
def show_metrics(classifiers,X,y,datakind):
fig, ax = plt.subplots(3, 3,figsize=(20, 20))
for i,(k,clf) in enumerate(classifiers.items()):
#予測
y_predict = clf.predict(X)
#混同行列をプロット(sklearn 0.22.0以降)
disp = plot_confusion_matrix(
clf,
X,
y,
display_labels=range(10),
cmap=plt.cm.Blues,
ax=ax[ i // 3, i % 3],
)
accuracy = accuracy_score(y,y_predict)
disp.ax_.set_title(k + ": acc="+ f"{accuracy:.2f}")
plt.savefig(f"./{datakind}_models_metrics.png",bbox_inches='tight', pad_inches=0)
plt.show()※「plot_confusion_matrix」を使用するためにはscikit-learn のバージョンは0.22.0以上である必要があります。
まずは、教師データの精度・混同行列を見てみましょう。
show_metrics(classifiers,X_train,y_train,"train")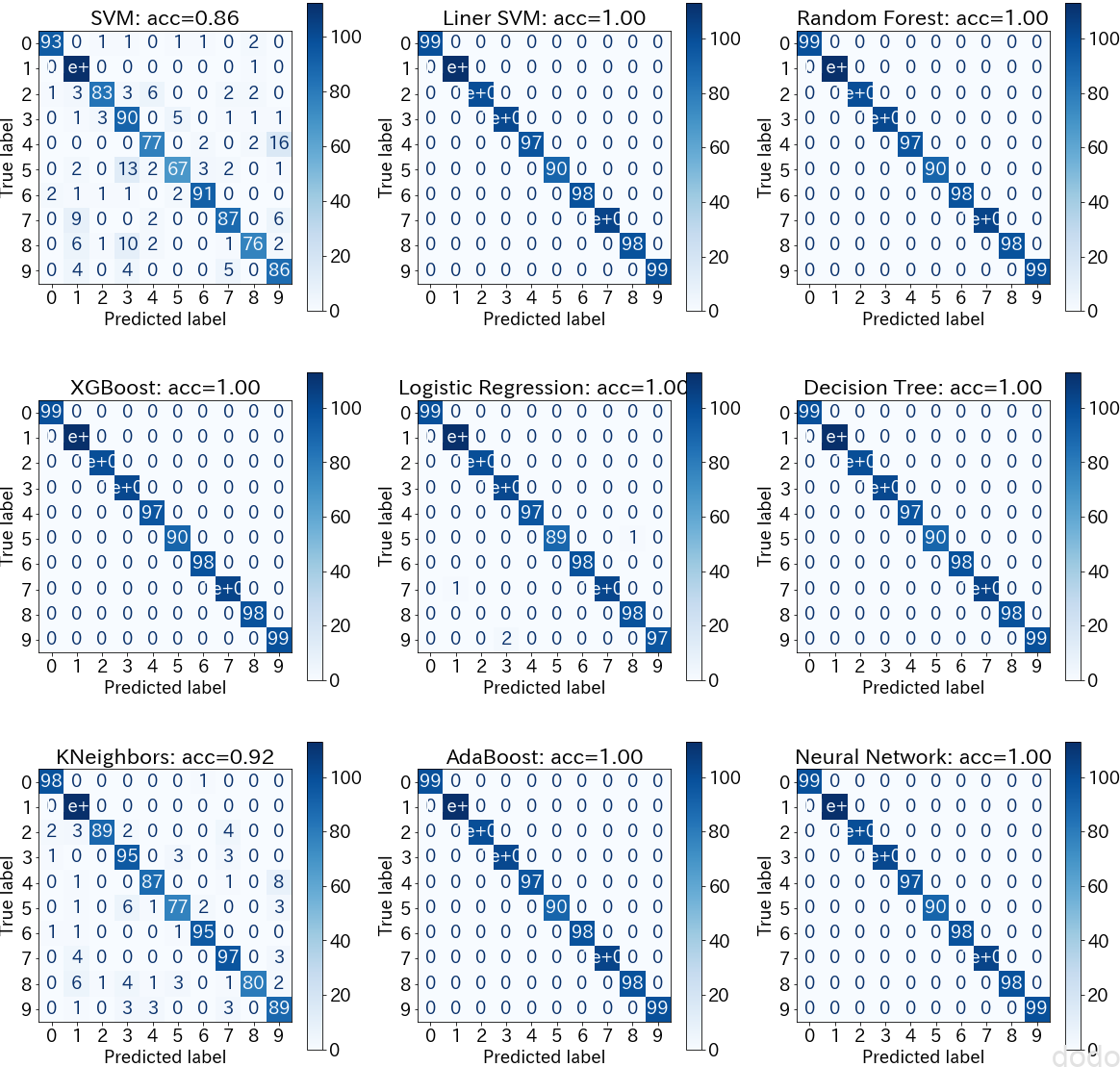 教師データの精度・混同行列
教師データの精度・混同行列一見すると、交差検証では性能が出ていなかった決定木、アダブーストでも高い精度が出ているようにみえます。
このモデルをテストデータに適用して見るとどうなるでしょうか。
show_metrics(classifiers,X_test,y_test,"test")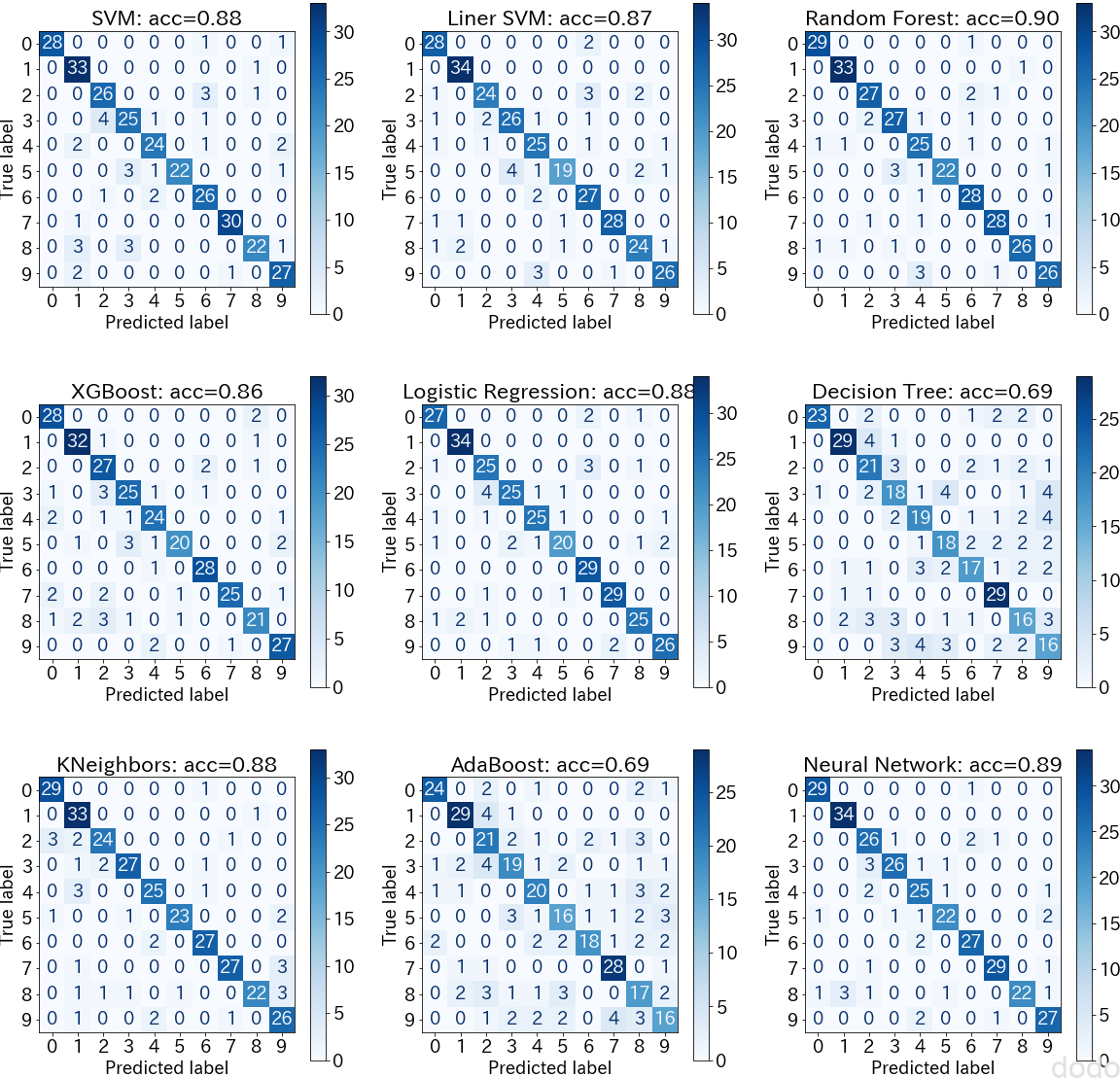 テストデータの精度・混同行列
テストデータの精度・混同行列やはり、交差検証で精度が悪かった決定木とアダブーストは、テストデータでも精度が悪いです。
そして交差検証で精度が良かったランダムフォレストとニューラルネットワークは精度が良く、交差検証の結果が未知(モデル生成では使っていない)のデータの精度に良く反映されている事がわかります。(データ分布が検証データとテストデータで良くマッチしているのでしょう。世のデータではなかなかこんな風にうまくは行きませんが・・)
まとめ
データセット「MNIST」を使って、「とりあえず」いくつかのモデルで評価してみました。
実際にはデータを可視化してクレンジングする作業など、面倒臭い作業が多々ありますが、「そのデータを使って分析をする意味があるのか?」「良い結果が見込めるのか?」などを判定するためにも、いくつかの分類器で評価してみる事は重要です。(時間とのトレードオフですが・・)
なお、「まずはいくつかの分類器で試す」方法をとった方が良いというのは、以下の本に紹介されておりますので、最後に紹介しておきます。
「Train many quick-and-dirty models from different categories (e.g., linear, naive Bayes, SVM, Random Forest, neural net, etc.) using standard parameters.」(標準のパラメータを用いて、異なるカテゴリー(例えば、線形、naive Bayes、SVM、ランダムフォレスト、ニューラルネット等)の多くの完璧ではないけど早くできるモデルで訓練する)
—『Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems』Aurélien Géron著


