









機械学習のアンチパターン。過去にやらかした反省を込めて書きます。

私は、以前勤めていた会社でSEをやっていましたが、大人の事情で、突如、データ分析の仕事をする事になりました。
当然、右も左もわからないので、本を読んだりネットを見たりして勉強しました。
情報が溢れている時代・・本を読み、ネットで調べれば、機械学習のアルゴリズム、混同行列、ROC曲線、AUC、過学習・・などなどの基本的な事を学ぶ事はできます。
しかし、私は、かなり肝心な事を見落としていて、いわゆるアンチパターンと呼ばれるような事を犯しまくっていました。
その反省を込めて、自分がしでかしたアンチパターンについて以下、記載して行きます。
アンチパターン
以下、私が犯してしまったアンチパターンとなります。(アンチパターンなのでご注意を)
ランダムシードを固定しない。
機械学習のモデルでは、ランダムフォレストなどランダム性があるアルゴリズムが多くあります。
これらのアルゴリズムは、実行するたびに微妙に結果が異なります。
よって、パラメータを調整した時に、それによって改善したのかどうかをきちんと判定する事ができません。
なので、機械学習のライブラリには、必ずランダムシードに該当する引数があり、それを固定して実行しなければなりません。
# NG例 この書き方では、実行する事に結果が異なってしまう。
rf = RandomForestClassifier(max_depth=2)
# OK例 ランダムシードを固定しているので実行毎に同じ結果になる。
rf = RandomForestClassifier(max_depth=2, random_state=42)
アルゴリズムを決めうちにする。
「今回は、ランダムフォレストを使います。」
「今回は、サポートベクトルマシンを使います。」
最初っから、使用するアルゴリズムを決め打ちしていました・・
もちろん、データの多さや種類によって、その分析に最適そうなアルゴリズムというものは存在します。
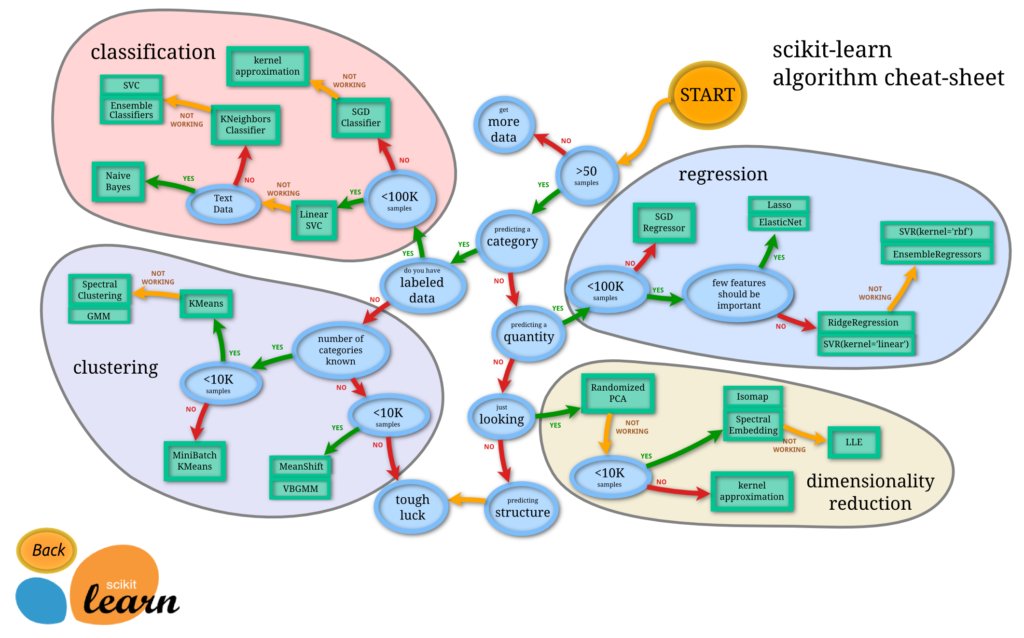 アルゴリズムチートシート(データによってどのようなモデルを選択すべきかの指標を示してます。)
アルゴリズムチートシート(データによってどのようなモデルを選択すべきかの指標を示してます。) 引用元:https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
このような図を顧客に見せて、「今回は、これです!(キリっ)」としてました。
しかし、実際にやってみないと、どのアルゴリズムが最適かなんてわからない事も多いのです。とりあえずパラメータ無調整でいいので、いくつかのアルゴリズムで試してみるべきです。
「Train many quick-and-dirty models from different categories (e.g., linear, naive Bayes, SVM, Random Forest, neural net, etc.) using standard parameters.」(標準のパラメータを用いて、異なるカテゴリー(例えば、線形、naive Bayes、SVM、ランダムフォレスト、ニューラルネット等)の多くの完璧ではないけど早くできるモデルで訓練する)
—『Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems』Aurélien Géron著
良い結果が出ない場合に、顧客から「あっちの方法なら、上手くいったのでは?」みたいな疑惑を持たれないようにするためにも、とりあえずいくつかのアルゴリズムを試しましょう。

因みに顧客から、「ディープラーニングでやって」とかアルゴリズム決めうちで言われるケースもあります。
このような顧客の場合、単なる無知でディープラーニングが常に最強と思っているのか「とりあえずAI(エーアイ)やりたい(社内的アピールで)」みたいなノリなのか判断が必要です。後者の場合ならば「まあ、そこまでおっしゃるなら・・」でディープラーニング一択でも仕方がないでしょう・・
検証データとテストデータを分けない。
教師データとテストデータに分けて分析するのは、さすがに機械学習(教師あり学習)をやっていれば、みなさん実施すると思います。
しかし、「検証データ=テストデータ」というのをやってしまう事例は結構あるのではないでしょうか?
これは、テストデータ(検証データ)を分析した性能を見て、パラメータを調整するという事であり、学習するために、テストデータを使用している事と同じです。
結果、過学習と同じ事が発生します。
なので、データは、教師データ、検証データ、テストデータに分けて、パラメータのチューニングは、教師データと検証データで実施して、モデルが完成した後に、テストデータでそのモデルの性能を測定するのです。
検証データによって最適なモデルのパラメータが決定した後は、教師データと検証データの両方を学習する事によりモデルを作成しなおします。そのモデルを最終的なモデルとして、最後にテストデータの性能を測定します。
テストデータでの性能が悪かったからと言って、それによってパラメータを調整してはいけません。(やりたい誘惑に襲われますが・・)
テストデータでの結果が悪かったという事は、そのモデルで運用した場合に、未知のデータには、適応しない可能性が高いことを示しているので、悪かった結果をそのまま報告するべきなのです。
交差検証しない。
これはひょっとしたら異論があるかもしれませんが、私としては交差検証は必須だと思っています。
前段で、データを教師データ、検証データ、テストデータに分けると記載しましたが、正確には、教師データと検証データの部分は、交差検証用に数パターン分けるイメージです。
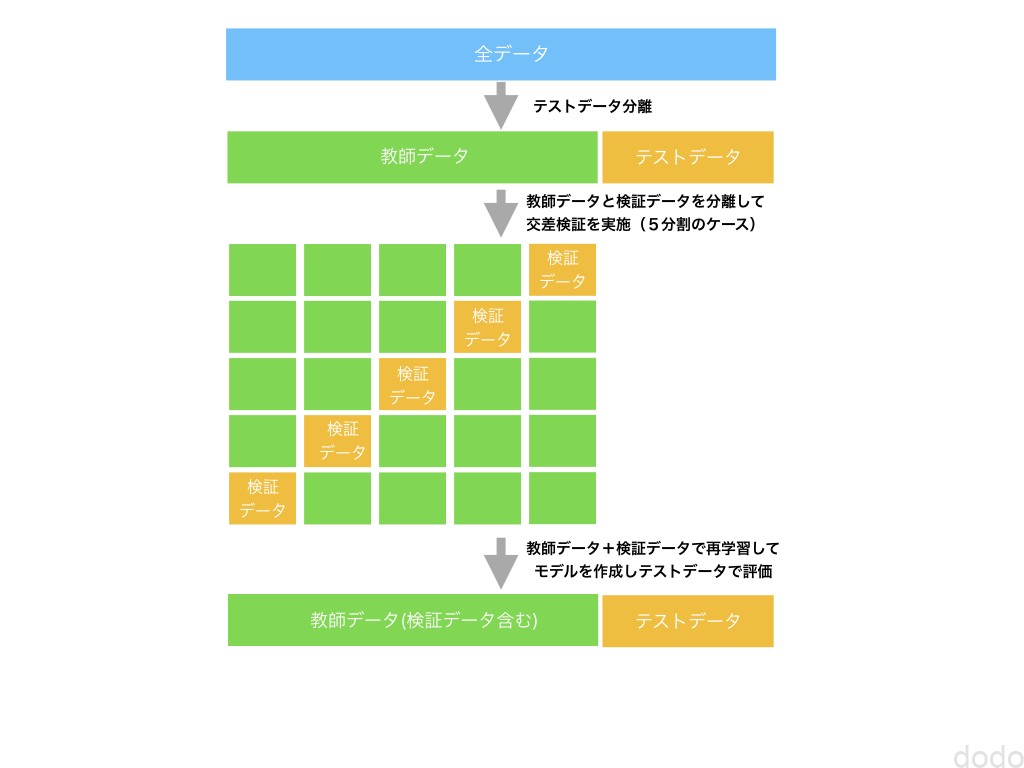 データ分割イメージ(5分割交差検証の場合)
データ分割イメージ(5分割交差検証の場合)
交差検証をしないと、どうしても、汎化性能に不安が残ります。
よっぽど特殊な事情がない限り交差検証は実施しましょう。
テストデータを見すぎる。
データを機械学習器に突っ込む前には、データを可視化してその傾向を見てでーた加工をどうするかなどの戦略を練ります。
ただし、データを教師データ、検証データ、テストデータに分けた後は、テストデータはもう見てはいけません。
パラメータ調整をあからさまにするつもりはなくても、データスヌーピングバイアス(data snooping bias)と言ってテストデータを覗き見する事によって無意識のうちにテストデータに最適化したモデルを作ってしまう場合があります。
なので、データを分割するための大雑把な傾向を掴んだ後は、テストデータは見ないようにしましょう。
スケーリング、欠損値補完にテストデータを使用する。
データのスケーリングや欠損値補完のために、データの分散、上限値、下限値、平均値など(以下、データの統計値と記載します。)を使用する事があると思います。
テストデータで性能を測定する時の注意点なのですが、データの統計値は、教師データ+検証データの統計値を使用する必要があります。
テストデータの前処理を実施するときにテストデータを含めて(もしくはテストデータのみで)、データの平均値などを求めてスケーリングや欠損値補完をしてはいけません。
極端な話、テストデータが1件ならば、その1件のデータの値=平均値、上限値、下限値になってしまうので、変ですよね?
前処理のロジックを独立させていると、ついつい無意識でやってしまいがちなので注意が必要です。
scikit-learnのpipelineの話で言えば、transformerを使用する場合、テストデータではfit_transformではなく、transformを使用しなければいけません。(詳細は以下の記事を参照してください。)

まとめ
以上、私がやらかした数々のアンチパターンについて記載しました。
意外にこのような事って初心者向けの本に書いてないしネットでも落ちていないんですよね・・
実は、英語では、かなりこのような情報が落ちているのですが、日本語での情報は圧倒的に少ないです。
データ分析の仕事をしていて気がついた事もありますが、実は、仕事を辞めた後に上でリンクを貼った『Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems』という本だったり、Courceraというサイトの講義で学んだものも多いです。

本記事が機械学習の初心者の方にとって少しでもご参考になれば幸いです。




