










説明可能なAIというような言葉が出てきてから、もう数年が経過しているかと思います。
実際、顧客に「予測の精度が良い」という結果だけ見せても、それだけで満足する事は少なく、どのような要因でその結果が出ているのかを説明する必要がある場合が多々あります。
昔は、その説明のために特徴量の重要度というものを指標にする事が多かったです。
ただ、この重要度というものは、なかなか曲者で、カーディナリティが高い(とりうる値のバリエーションが多い)場合に重要度が高くなる傾向があったり、特徴量同士で相関が強いと重要度が分散したりする傾向があります。
ここでの重要度は、ツリー構造の分類器で使用されるジニ不純度をもとに算出される重要度に関しての記述となっています。Permutation Feature Importance (PFI)についてはまた別途、いつか考察します。
SHAPとは?
そんな中、近年、SHAPという手法が良く使われています。
SHAP(SHapley Additive exPlanations)は、Shapley値というものを使って、予測に特徴量がどれだけ寄与するかを算出する手法です。
元々、Shapley値というのはゲーム理論で得られた利益を貢献度に応じてプレイヤーに分配する理論です。
プレイヤーを特徴量、プレイヤーの貢献度を予測への寄与度に読み替えます。
なお、Shapley値を真面目に計算すると、特徴量の階乗に比例して計算量が増えて、とても計算できないので、SHAPでは近似値を計算しております。
PyCarat+SHAPで可視化
実際にSHAPを用いて特徴量の寄与度を可視化してみましょう。
SHAPは単独でライブラリが存在するので、あえてPyCaratを使用する必要はないのですが、最近、せっかくPyCaratを記事化しているので、本記事ではPyCaratのライブラリ(SHAPのライブラリをラッピングしている)を使用します。
前提条件
本ソースコードは、Python3.7.5で起動するJupyter Lab上で実行されています。
また使用している各ライブラリのバージョンは以下の通りです。
- numpy(1.20.3)
- pandas(1.3.5)
- scikit-learn (0.23.2)
- pycarat(2.3.10)
- shap(0.40.0)
PyCaratの分類器を使用するため以下のようにインポートしております。
from pycaret.classification import *タイタニックデータ取得
今回は、機械学習のテストデータとして定番とも言って良いタイタニックのデータ(生存したか亡くなったか・・)を使用します。
タイタニックのデータは以下のコードにより取得できます。
from sklearn.datasets import fetch_openml
titanic = fetch_openml(data_id=40945, as_frame=True)
取得したデータのtargetとdataを結合してDataFrameに変換します。
import pandas as pd
data = pd.concat([pd.DataFrame(titanic.target), pd.DataFrame(titanic.data)] ,axis=1)
データの中身は以下のようになっております。
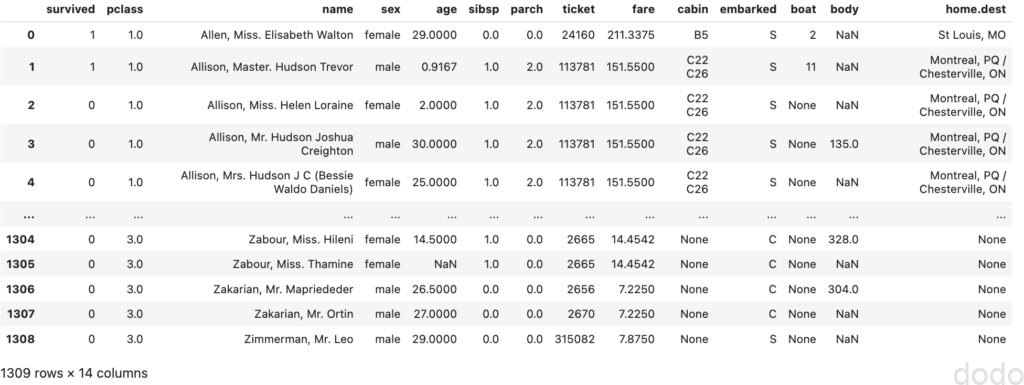 タイタニックデータ
タイタニックデータ
データの詳細については以下のOpenMLのサイトをご参照ください。

前処理
PyCaratのsetupにより前処理を実施します。
seed = 42
exp1 = setup(data = data,
target='survived',
normalize=True,
ignore_features=['name','ticket','cabin','boat','body','home.dest'],
session_id=seed)
ここで、教育データとテストデータ(厳密には検証データ)の分割、規格化、予測に関係がなさそうな特徴量(厳密には関係あるかもしれないけど、かなり加工が必要そうな特徴量)の除外をしています。
モデルの比較
モデルを比較して精度(Accuracy)が良いTOP5を取得します。
classifiers = compare_models(n_select = 5)実行結果は以下となります。
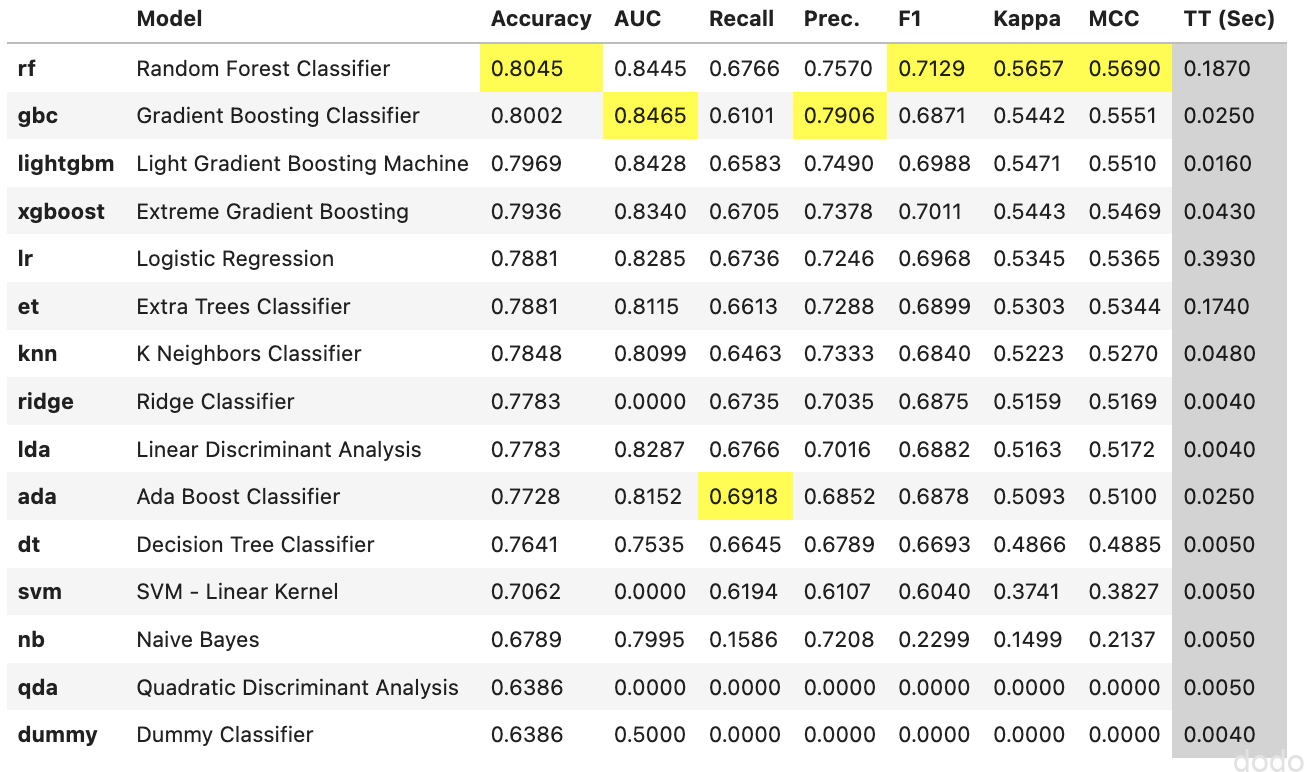 モデル比較結果
モデル比較結果1位から5位は以下のモデルとなりました。
- ランダムフォレスト
- グラジエントブースト
- LGBM
- XGBoost
- ロジスティック回帰
全てのモデルについてパラメータチューニングを実施します。
tuned_models = [tune_model(clf) for clf in classifiers]※パラメータチューニングにより結果が良くならないモデルもありますが、今回はとりあえず良しとします。
寄与度の可視化(全体)
PyCaratでSHAP値を可視化するためには、interpret_modelという関数を使用します。
しかし、この時点である事がわかりました・・
PyCaratのSHAPは、ツリー系の分類器しかサポートしていません。
interpret_model(tuned[4])(ロジスティック回帰のケース)を実行したら、以下のようなエラーが表示されました。
結論として、精度が良かったTOP5のうちグラジエントブーストとロジスティック回帰は、PyCaratでは可視化できません。
SHAPのライブラリ自体は、ツリー用、ディープラーニング用、線形回帰用、さらには全てのモデルに対応できるクラスが用意されているので、PyCaratのラッパーも早く対応してほしいです・・・
気を取り直して、最も精度が良かったランダムフォレストで可視化を実施します。
interpret_model(tuned_models[0])実行すると以下のグラフが表示されます。
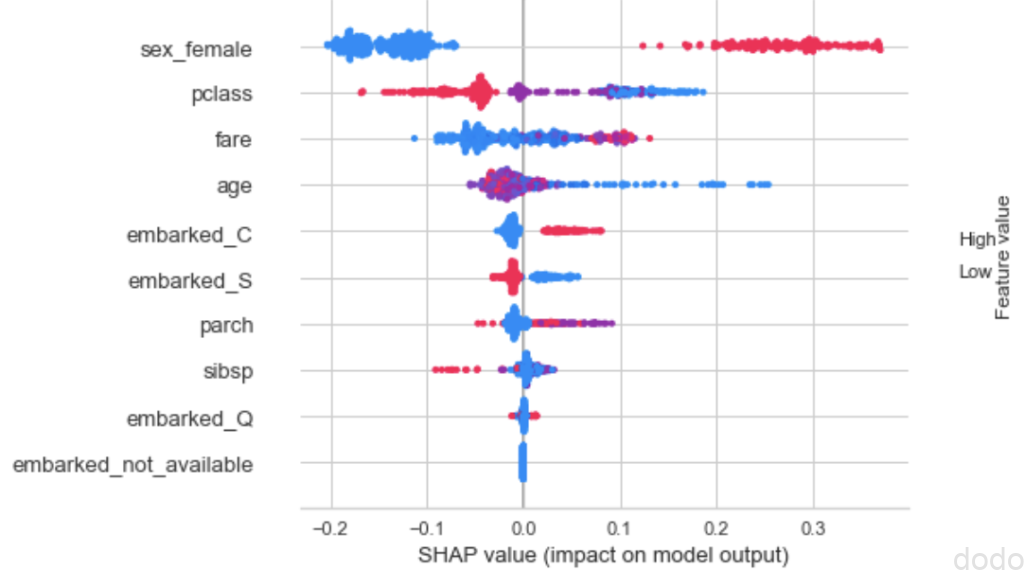 SHAP値(全体):角データのSHAP値をプロット
SHAP値(全体):角データのSHAP値をプロット各データ(検証データ)のSHAP値を特徴量ごとにプロットしたものになります。
生存=1、死亡=0のラベルを設定しているため、SHAP値がプラスのデータが生存に寄与しており、SHAP値がマイナスのデータが死亡に寄与しています。
また、赤い点はデータの値が高く、青い点はデータの値が低い事を表しています。
これらの事からどのような解釈ができるか見ていきましょう。
最も寄与度が高いsex_female(女性かどうか。女性=1、男性=0)は、赤い点がSHAP値がプラスで、青い点がSHAP値がマイナスの傾向が強くなっています。
これは、女性の生存確率が高く、男性の生存確率が低い事を表しています。
同様に、pclass(客性のクラス)は、高級なほど(つまり1等、2等、3等と値が低いほど)生存確率が高く、fare(料金)は高いほど生存確率が高く、age(年齢)は低いほど生存確率が高い事がわかります。
逃げるのに女性と子供を優先して紳士的だったけど、結局、金持ちの助かる確率高かったよね・・という、まあ身も蓋もない(しかし実際にそうだった)結果が表れています。
なお、以下、単純に各特徴量の寄与度を比較するためには、各データのSHAP値の絶対値の総和を可視化します。
interpret_model(tuned_models[0],plot_type='bar')実行すると以下のグラフが表示されます。
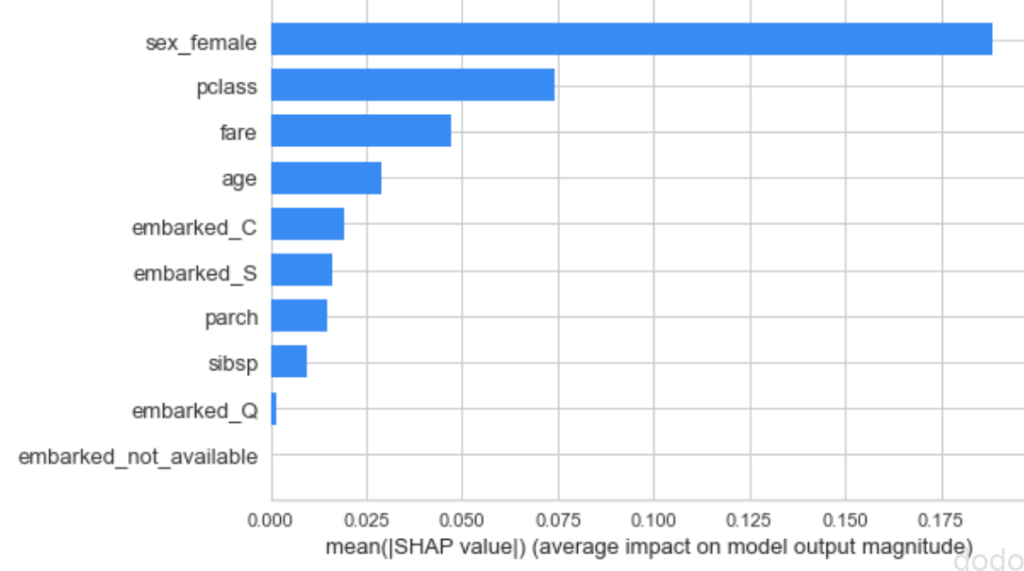 SHAP値(全体):各データのSHAP値の絶対値の総和
SHAP値(全体):各データのSHAP値の絶対値の総和
寄与度の可視化(個別)
SHAP値の良いところは、各データごとの予測結果に特徴量の値がどのように寄与したかがわかる事です。
PyCarat経由での個別データのSHAP値の出力には、データのインデックスをobservationの引数で指定して、以下のように記載します。
interpret_model(tuned_models[0],plot='reason', observation=0)実行結果は以下のようになります。
 SHAP値(個別)
SHAP値(個別)ここで、base value(=0.3617)とは、各特徴量の寄与を考慮しない場合のSHAP値となります。
なお、ランダムフォレストの場合は、SHAP値の出力が確率となっており、このbase valueは全体の生存確率とほぼ近い値(完全にイコールではありません)になっています。
上記で、「ランダムフォレストの場合は」と記載しましたが、実際にXGBoostでの結果「interpret_model(tuned[3],plot=’reason’, observation=0)」を見ると、SHAP値の値が全く違います。XGBoostは、シグモイド関数での変換前の値を使用しているからです。(統一してほしい・・)
上図から分かる通り、サンプルの例では、ほぼ全ての特徴量がbase valueからの生存確率を下げる方向に働いている事がわかります。
寄与度の可視化(元のデータとの対比)
PyCaratを使っていて思うのですが、ラッピングされていてコード量が少なく済むが故にデータへのアクセスがかえって面倒くさい事があります。
SHAPの場合も、上記のobservation=0のデータが実際にどのデータなのかがわかりにくいです。
値も規格化されているので対応がつきにくく、さらに正解データ(実際に生存したのか死亡したのは)がわかりません。
上記のSHAP値=0.07は、あくまでもモデルが予測した生存確率であって、正解かどうかは別の話です。
ここで、ちょっと面倒ですが、元のデータとの対比を行なってみましょう。
observation=0で指定したデータはsetupで内部で分割された検証データであり、以下のようにして取得できます。
X_test = get_config('X_test')
X_test[0:1] 検証データ(observation=0)
検証データ(observation=0)この時点で既に規格化されています。元のデータを拾ってくるためには、一番左に表示されているindex=1148から元のデータを検索することになります。
data.iloc[X_test[0:1].index] 検証データ(observation=0):データ規格化前
検証データ(observation=0):データ規格化前
このままだと何度も試すのが面倒くさいので、関数化しました。
def get_original_data(model,i):
#テストデータ取得
X_test = get_config('X_test')
#テストデータのインデックスから規格化前のデータ取得
data_val = data.iloc[X_test[i:i+1].index]
#予測結果取得 (確率)
predicted_proba = model.predict_proba(X_test[i:i+1])[0][1]
#予測結果(確率をそのまま丸めてもいいけど、念の為、取得・・)
predicted = model.predict(X_test[i:i+1])[0]
#文字列化
predicted_str = f'{predicted}({predicted_proba:.2f})'
#予測結果結合
data_val.insert(0, 'predicted', predicted_str)
return data_val※ついでに予測結果も結合しています。
これにより、以下のようなSHAP値と元のデータの対比が簡単にできます。
index = 1
interpret_model(tuned_models[0],plot='reason', observation=index) SHAP値(個別)observation=1のデータ
SHAP値(個別)observation=1のデータget_original_data(tuned_models[0],index) 検証データ(observation=1):データ規格化前
検証データ(observation=1):データ規格化前こちらのデータは予測は生存確率44%で死亡と判定していますが、実際のデータは、生存(survived=1)となっています。
まとめ
以上、PyCarat+SHAPを使用して特徴量の寄与度を可視化してみました。
SHAPの良い所は、寄与度が可視化できて顧客に説明しやすい事です。
説明しやすいのは「SHAPと言う手法があって・・」で満足する顧客の場合です。SHAPのロジックまで深く知りたい顧客の場合は、少々、説明が大変かもしれません・・
ただし、説明しやすいからと言ってあまり盲信はしないようにしましょう。
算出されるSHAP値は、あくまでもモデルの予測結果に対する寄与度なので、予測がただしいかどうかとは関係ありません。
モデルの性能が良ければ説得力があるし、性能が悪ければ説得力はありません。
そして、トータルで同じような性能のモデルだとしても、特徴量の寄与度は異なる可能性はあります。
限界をわかりつつ使用する事が大事かと思います。
機械学習の結果の説明可能性については今後も重要になるので、これからも色々、記事にしていけたらと思います。


