










PyCaratという非常に便利な機械学習のためのライブラリがあることを最近知りました。
以前、MNISTを様々なモデルで評価するという事をやってみましたが、同じように複数モデルで比較するとともに最終モデルを生成するといった分析のプロセスをこのPyCaratを使用してシミュレーションしてみます。
なお、本記事の作成にあたって以下の公式サイトを参照しております。細かいAPIの仕様などは以下をご参照ください。
https://pycaret.readthedocs.io/en/latest/
https://pycaret.gitbook.io/docs/
前提条件
本ソースコードは、Python3.7.5で起動するJupyter Lab上で実行されています。
使用している各ライブラリのバージョンは以下の通りです。
- numpy(1.20.3)
- pandas(1.3.5)
- scikit-learn (0.23.2)
- pycarat(2.3.10)
またPyCaratの分類器を使用するため以下のようにインポートしております。
from pycaret.classification import *MNIST
MNISTについては、以前の記事にも記載しましたが、手書き数字の機械学習データセットで、画像データ解析の入門用データとしてよく使用されています。
以下のコードより取得できます。
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1,)sckit-learnの0.24以上のバージョンでは、mnisit.dataがデフォルトでpandasのDataFrameになります。以下のコードをそのまま動かすためには、fetch_openmlに対して「as_frame=False」の引数が必要です。
先頭の10個のデータのみを可視化すると以下のようになります。
import matplotlib as mpl
import matplotlib.pyplot as plt
fig, ax = plt.subplots(2, 5,figsize=(10, 5))
for i in range(0,10):
r = i // 5
c = i % 5
ax[r,c].set_xticks([])
ax[r,c].set_yticks([])
ax[r,c].set_title(mnist.target[i],fontsize=30)
ax[r,c].imshow(mnist.data[i].reshape(28, 28), cmap='Greys')
plt.savefig("./mnist_10.png")
plt.show()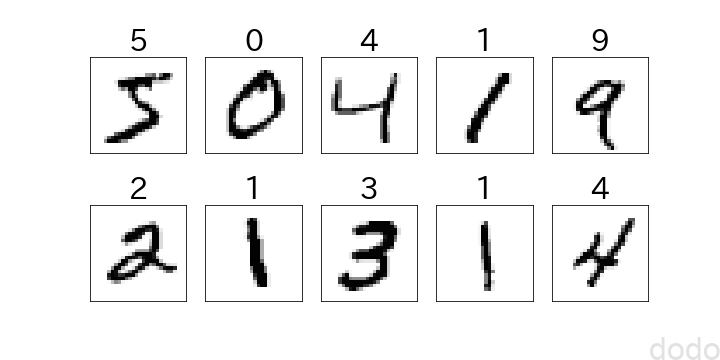 mnistサンプル
mnistサンプル前処理
まずはmninstのデータをDataFrame形式に変換します。
import pandas as pd
label = pd.DataFrame(mnist.target,columns=["label"])
label = label.astype("int64")
data = pd.concat([label, pd.DataFrame(mnist.data)] ,axis=1)
2行目でint形式にラベルを変換しているのは、後々、PyCaratでテストデータを評価するときに、モデルの予測ラベル(int型)とテストデータのラベル(Object型)の型の違いで、性能の評価がうまくいかないためです。(何故、そうなってしまうかはわかりません・・バグかも。。)
MNISTデータは7万件ありますが、お試しということで、教師データを1000件、テストデータを300件だけ抽出します。
from sklearn.model_selection import train_test_split
seed = 42
data_train, data_test = train_test_split(data,
test_size=300,
train_size=1000,
random_state=seed,
stratify=label)
なお、ラベルの割合は教師データとテストデータで均一になるように「stratify=mnist.target」により層化抽出(比例配分)しています。
またseedは実行毎に結果が変わらないように乱数状態を固定するために使用しております。(以後もこのseedを使用します。)
次にいよいよPyCaratの関数を使用してデータをモデルに投入するための前処理を実施します。
clf1 = setup(data = data_train, target="label",normalize=True,normalize_method="minmax",session_id=seed)
ここで、ターゲットとなる列の指定、規格化有無(→有)と規格化方法(0-1の間で規格化)を指定しております。
このsetupの引数は非常に多く、様々な前処理を組み込む事ができるので、興味ある方は先に挙げたサイトなどでご確認ください。
なお本コードをJupyter Lab上で実行すると以下のような情報が出力され、デフォルトの設定などを確認する事ができます。
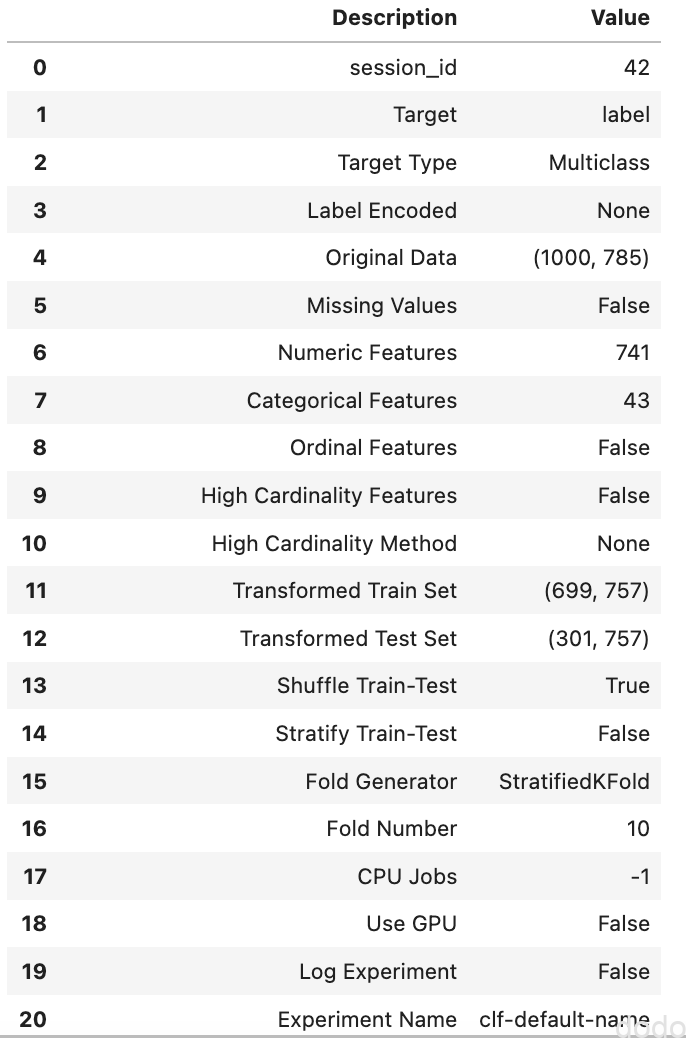 setup実行により表示される設定(一部のみ)
setup実行により表示される設定(一部のみ)
これを見ると教師データと検証データの比が7:3である事や10分割の交差検証法を用いる事などがわかります。
上で「教師データと検証データの比」と記載しましたが、ここに記載した「教師データ」と「検証データ」とは、MNISTを「教師データ」と「テストデータ」に分けた時の「教師データ」をさらに分割したものを意味しております。(教師データ→教師データ+検証データ)
これらは、モデルの訓練・生成する時のためのデータで、最初に分けた「テストデータ」は、モデルが決定された後にモデルを評価するために使用するので、混乱しないようにしてください。
モデルの比較
実際のプロジェクトでも、モデルを一つに決め打ちして、パラメータチューニングを行うのではなく、とりあえずデフォルトのパラメータで様々なモデルで試してみる事が重要です。
PyCaratを使用すると、そんな作業がわずか1行で実行できます。
best = compare_models()
これを実行すると以下のような結果が表示されます。
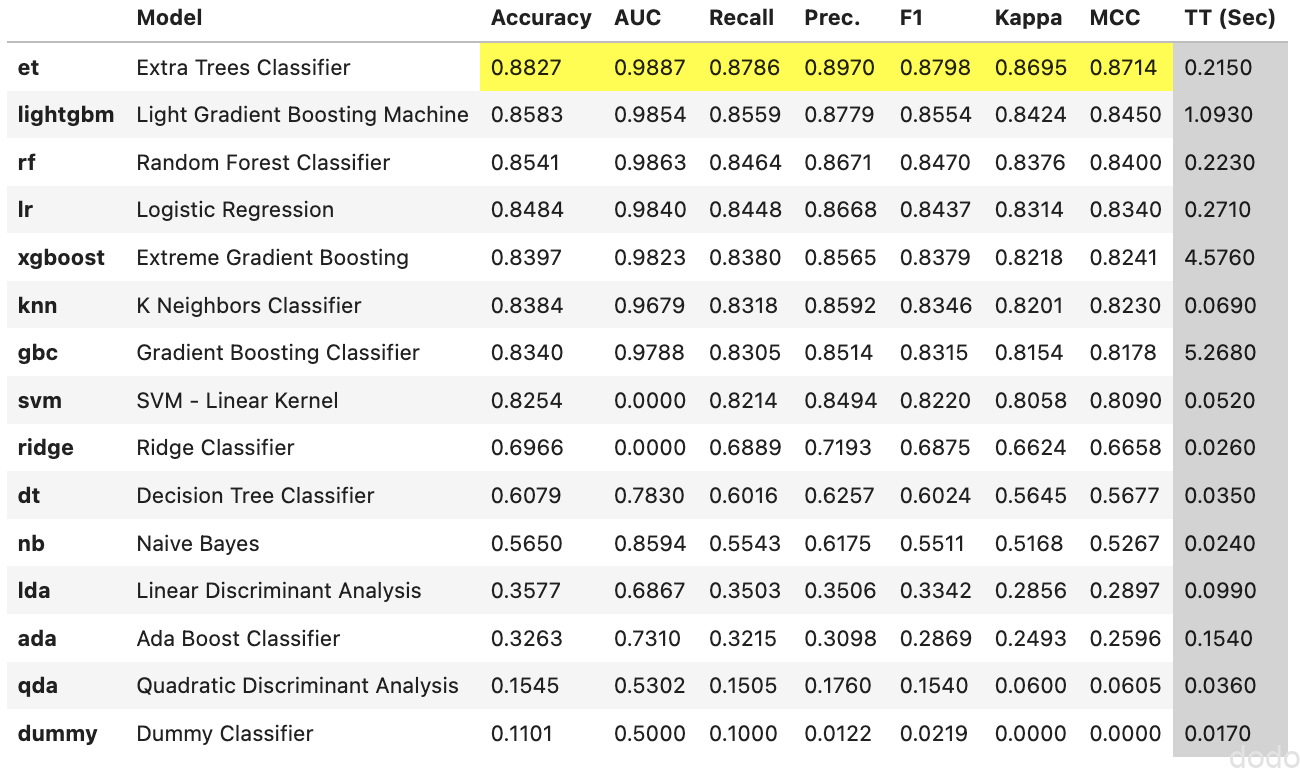 compare_modelの実行結果
compare_modelの実行結果様々な分類器で、それぞれ交差検証を実行した結果が成績順に表示されます。(Accuracyなどの評価指標は10分割交差検証の平均値となっています。)
MNISTの分類において、Random Forestの成績が良く決定木 (Decision Tree)やAda Boostの結果が悪いのは、前回の記事と同様ですね・・
返り値は、最も成績が良かったモデルである「Extra Tree Classifier」となっています。
Extra Tree Classifierは、あまり聞き馴染みない方もいるかもしれません。ランダムフォレストに似た決定木を使用したアンサンブル学習ですが、ランダムフォレストが木の分割方法について最適化された手法を用いるのに対して、Extra Tree Classifierは分割方法自体をランダムに決定します。
チューニング
分析のプロセスとして、分類器を決定したら、その分類器において、パラメータをチューニングしてさらに精度を向上させます。
PyCaratにはそのための関数を用意されており、モデルの比較で最良だった分類器を引数にして、tune_modelという関数を実行すれば、自動でパラメータチューニングしたモデルを生成する事ができます。
tuned = tune_model(best)
ただ、このモデルの精度を確かめたところ、モデル比較で選択されたデフォルトのパラメーのモデルであるbestのAccuracyが0.8827なのに対して、tunedのaccuracyは0.8340と下がってしまいました。
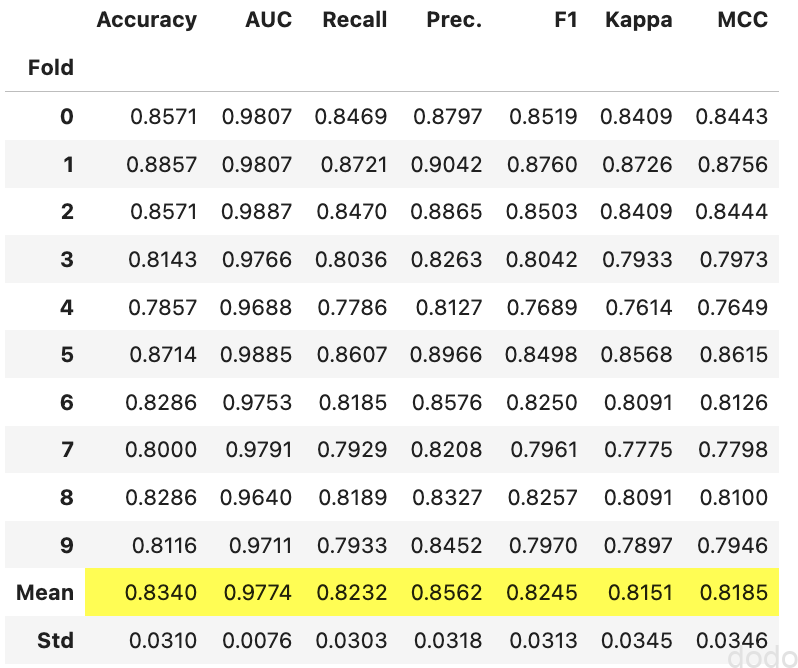 tune_modelの実行結果
tune_modelの実行結果パラメータチューニングしたら精度が下がるって、何か間違ってるのかな・・と思ったら、どうもデフォルトのチューニングではイテレーション回数が少なかったりパラメータ空間の指定が甘かったりで、こういう事もあるそうです・・・
なので、tune_modelについては、そんなにお気楽ではないようです。
パラメータチューニングは前処理の次に面倒くさい作業なので、ここがお気楽にできればどんなに良いかと思いましたが、世の中そんなにうまくはいかないですね・・
もちろん何かしらの設定で使いこなせば、うまくいくのかもしれませんが、とりあえず今は次の最終モデルの生成に進みたいと思います。
因みに以下のようにするとデフォルトパラメータのモデルとチューニングされたモデルのパラメータを表示することができます。
print(best)
print(tuned) パラメータの比較(上がデフォルトパラメータ、下がチューニングされたパラメータ)
パラメータの比較(上がデフォルトパラメータ、下がチューニングされたパラメータ)最終モデル
ここまでのモデルは教師データ中の検証データを除外したもので生成されたモデルですが、最終モデルは教師データ全てを使用してトレーニングしたものとして生成します。
通常は全教師データでモデルをfitしなおすという事をしますが、PyCaratではfinalize_modelという関数によって、この作業を実行します。
本来ならば、引数にはチューニングされたモデルを使用して以下のようにして最終モデルを生成するはずだったのですが・・
final_model = finalize_model(tuned)
デフォルトのパラメータのモデルの方が良いという結果が出てしまったので、ここでは特別に最終モデルは、以下のようにデフォルトのパラメータのモデルを元に生成します。
final_model = finalize_model(best)テスト
最終モデルが作成できたので、いよいよテストデータを用いて性能を検証します。
predictions = predict_model(final_model, data = data_test)
Jupyter Lab上で実行すると以下のように性能が表示されます。
 predict_modelにより表示された結果
predict_modelにより表示された結果テストデータでもAccuracy=0.9100となかなか良い結果となっております。
またpredict_modelによって返された結果は、元のテストデータに予測ラベル(Label)とその予測確率(Score)が追加されたものになっています。
predictions.head() predict_modelの返り値(LabelとScoreが追加)
predict_modelの返り値(LabelとScoreが追加)モデルの保存
最終モデルの検証ができたら、モデルを保存します。
save_model(final_model,'Final ETC 20200418')
この例ではカレントディレクトに「Final ETC 20200418.pkl」という名前のファイルが保存されます。
なお本モデルを再利用する場合は以下のようにして保存したモデルをロードします。
saved_final_model = load_model('Final ETC 20200418')まとめ
以上、PyCaratを用いて、データ分析の一連の作業について実行してみました。
特にモデルの比較は非常に簡単にできて良いと思いました。
一方、パラメータチューニングに関しては、引数を細かく指定しないお試し使用だとしても、少し期待はずれでした・・データによってはうまくいくのでしょうか・・
なお、今回はグラフなど全く表示しませんでしたが、グラフ表示の関数などもかなり豊富に用意されているようなので、次回、取り扱う場合は、そのような関数を利用してもう少し深掘りしてみたいと思います。

