










前回の記事では、動物判定の分類器の作成までを行いました。

今回は、このモデルを使用してアプリを作成します。
画面イメージ作成
画面イメージはv0で作成します。
v0へは以下の通り指示しました。
顔の画像をアップしたらその顔が犬、猫、猿、豚、蛙のうちどれに近いかを判定するアプリを作成します。
顔写真はファイルからアップロード、もしくはドラッグ&ドロップでアップロードします。 アップロードすると、円グラフが表示されて犬、猫、猿、豚、蛙の比率を%で表示します。 グラフの上に最も高かったカテゴリー(例:犬)で「あなたはOO%、犬です」と表示します。
画面イメージは添付を参照してください。
添付した画面イメージは以下の通りです。(Keynoteで作成しました。)
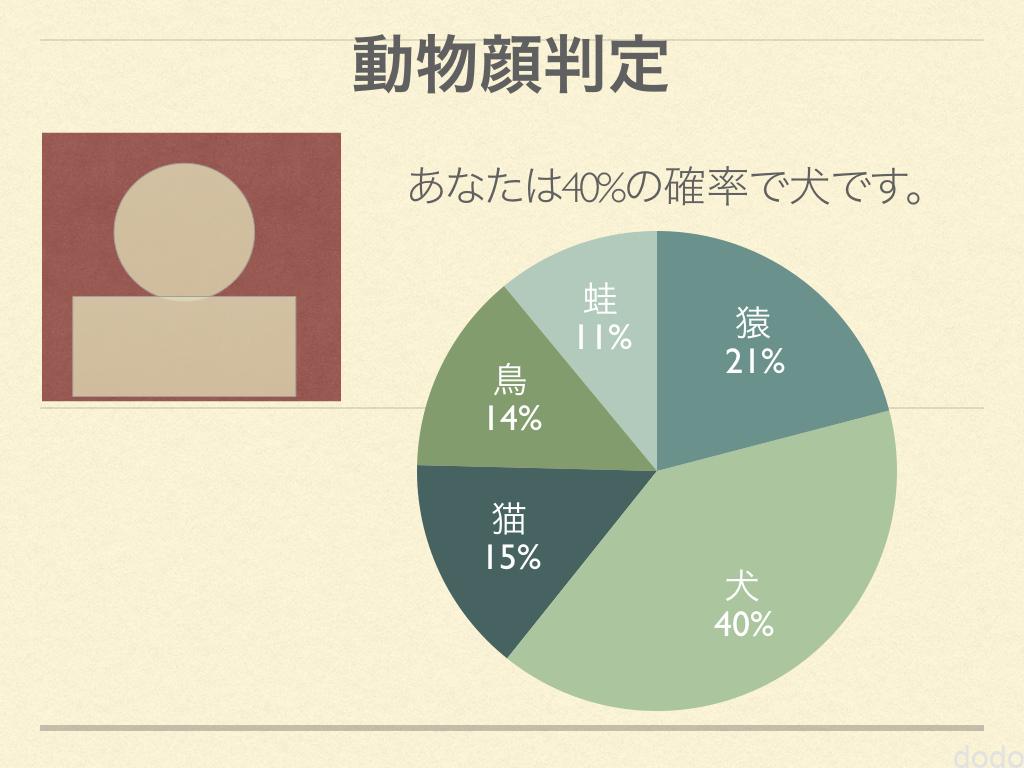 画面イメージ
画面イメージ最初に完成した画面のイメージは以下の通りです。
 v0作成画面1
v0作成画面1ただ、画像をドラッグ&ドロップしても、全く反応しません。「ファイルをアップロード」を押すとファイルダイアログが開き、ファイルを選択することはできますが、やはり何も起こりません。
2回ほど、その旨を伝えて修正を依頼しましたが、状況は変わりませんでした。
これは、以前経験した「ローカルに持ってこないと動かない」パターンかなと思いましたが、画像をアップロードした後のデザインが全くわからないまま、ローカルに移行するのは危険です。
そこで苦肉の策として、初期状態でデフォルトの画像が表示されるようにしました。(デフォルト画像は指示と一緒に添付しました。)
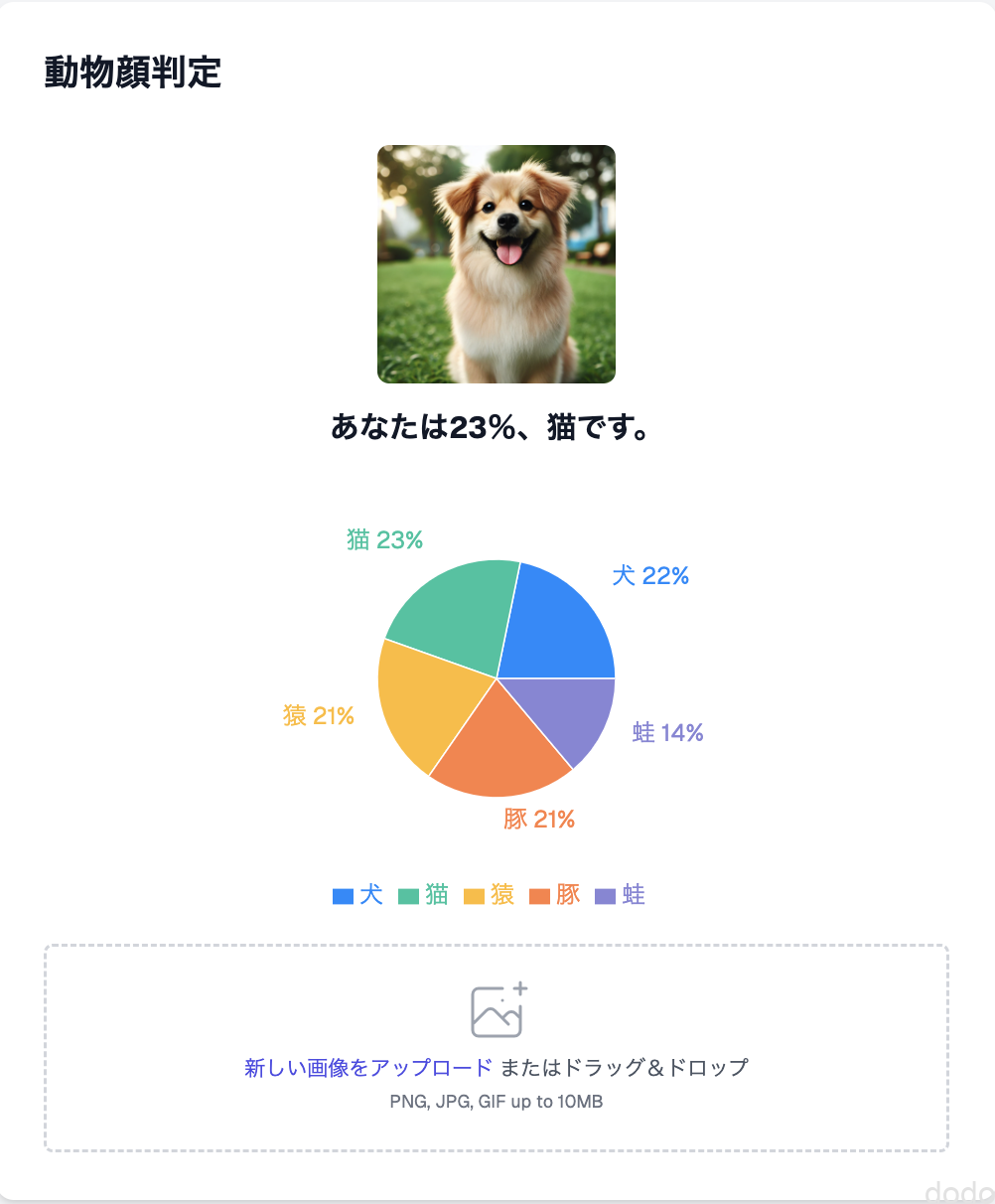 v0作成画面その2
v0作成画面その2添付したイメージに近いものは出来上がりましたが、「あなたはOO%、〇〇です」という文言が表示されず、それを繰り返し指摘しましたが、やはり表示されませんでした。
ここで諦めて、v0の機能を使用し、コマンドを使ってローカルにインストールしました。
すると、画像もアップロードできるし、「あなたはOO%、〇〇です」の文言も表示されます。
v0とローカルで挙動や見た目が異なることがあるのは、今後の課題かもしれません。
その後、Cursor Composerを使用して、画像のアップロード領域を画像の表示領域と同じにしたり、文字の位置を調整して以下のモックアップ画面が完成しました。(データは仮の固定データです。)
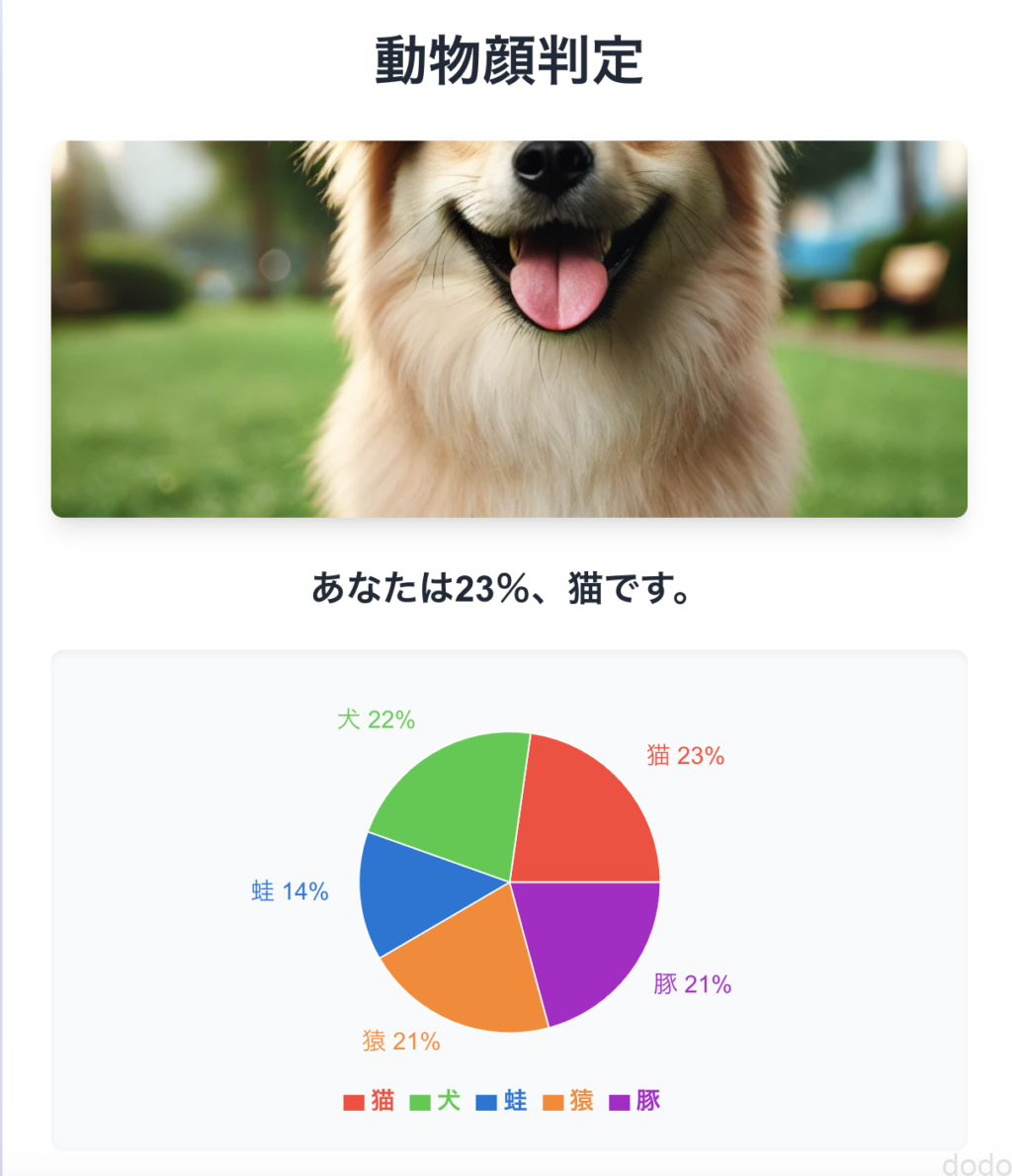
モックアップ完成
ロジック実装 -分類器を使用して判定-
実際に前回作成したモデルを使用して判定させるロジックを実装します。
Cursor Composerへの指示は以下の通りです。
実際にモデルを使用して判定して確率を円グラフにしてください。サーバーサイドをpythonのflaskで実装して、クライアントサイドから呼び出すようにしてください。なお、サーバーサイドのロジックは、image_cls.ipynbの最後のモデルをロードして確率を出力するロジックから生成してください。
ここでimage_cls.ipynbは、前回の記事に掲載したソースコードです。
驚くべきことに、この指示だけでサーバーサイドのPythonファイルが完成してしまいました。ソースを見る限り、ほぼ問題はありません。
クライアントサイド(TSXファイル)も修正されてり、Flaskからの応答結果を円グラフに反映するロジックが記載されています。
ただし、Flask-CORSを使用して別のオリジンからアクセスできるような仕組みになっていたため、「同一オリジンでNext.jsとFlaskを動作させるようにしてください」と指示したところ、next.config.jsが作成されました。
next.config.jsの内容は以下の通りです。
module.exports = {
async rewrites() {
return [
{
source: '/api/:path*',
destination: 'http://127.0.0.1:5000/:path*'
}
]
}
}
この仕組みによって、同一オリジンで動作するようになりました。
さて、実装はされましたが、まだFlaskから返す結果をうまく画面のグラフにマッピングできていません。
ここからは、FlaskとNext.jsの双方にログを仕込んで原因を究明しました。
エラーは出力されず、動作がうまくいかない時に、Cursor Composerに何度も「〇〇が動きません」「〇〇が表示されません」と伝えても、不具合が解消されないことがよくあります。その際は、「不具合の原因を追えるように例外処理を組み込み、できるだけ詳細なログを出力してください」と指示し、そのログを基に問い合わせた方が効率的です。(ログを仕込めば、自分で解決できるケースもあります。)
そして、ログを確認しながらCursor Composerに問い合わせを行い、最終的に完成しました。
以下は、動作させている画面です。
まずはテストとして、動物の画像を貼り付けます。
しっかり判定されているのが分かります。(判定結果が前回テストした時と同じなのは当然ですが、ラベルとの対応が正しい事を確認しています。)
次に人物の画像を貼り付けます。
判定結果に納得できるかはさておき、しっかり動作しています。
ちなみに、芸能人で「猿顔」「蛙顔」「豚顔」だと思う人(あくまで私の感想です)も試してみましたが、思ったような判定結果にはなりませんでした。
やはり、「〇〇の顔」と「〇〇顔」は別物のようです。
本気でこの判定器を作成するならば、本物の動物ではなく、人間の「〇〇顔」を集めてラベル付けし、学習させるべきかもしれません。
ただ、今回はお遊びなので、ここまでにしておきます。
ソースコード
最後に、参考としてクライアントサイドのTSXファイルとサーバーサイドのPythonファイルのコードを掲載します。(page.tsx.layout.tsxは省略します。)
animal-face-detector.tsx
サーバーからの返信とクライアントサイドのオブジェクトのマッピングを少し手修正した以外は、AIが生成したコードそのままです。
'use client'
import { useState, useCallback } from 'react'
import { useDropzone } from 'react-dropzone'
import { PieChart, Pie, Cell, Legend, ResponsiveContainer } from 'recharts'
import Image from 'next/image'
// 定数の定義
const ANIMAL_LIST = ['犬', '猫', '猿', '豚', '蛙']
const COLOR_LIST = ['#FF4136', '#2ECC40', '#0074D9', '#FF851B', '#B10DC9']
// 日本語の動物名を英語名にマッピングするオブジェクト
const ANIMAL_MAP: { [key: string]: string } = {
'犬': 'dog',
'猫': 'cat',
'猿': 'monkey',
'豚': 'pig',
'蛙': 'frog'
}
export function AnimalFaceDetector() {
// 状態の定義
const [result, setResult] = useState<{ name: string; value: number; }[] | null>(null)
const [image, setImage] = useState<string | null>(null)
const [error, setError] = useState<string | null>(null)
// 画像分析関数
const analyzeImage = useCallback(async (file: File) => {
const formData = new FormData()
formData.append('file', file)
try {
console.log('サーバーにリクエストを送信中...')
const response = await fetch('/api/predict', {
method: 'POST',
body: formData,
})
if (!response.ok) {
throw new Error(`HTTPエラー! ステータス: ${response.status}`);
}
const data = await response.json()
console.log('サーバーからのレスポンス:', data)
// 結果の調整:確率をパーセンテージに変換し、日本語の動物名と対応付ける
const animal_prob_list = ANIMAL_LIST.map(animal => ({
name: animal,
value: Math.round(data[ANIMAL_MAP[animal]] * 100)
}))
setResult(animal_prob_list)
setError(null)
console.log('更新された結果:', animal_prob_list)
} catch (error) {
console.error('画像分析エラー:', error)
setError(error instanceof Error ? error.message : '画像の分析中にエラーが発生しました。')
}
}, [])
// ドロップゾーンのコールバック関数
const onDrop = useCallback((acceptedFiles: File[]) => {
const file = acceptedFiles[0]
if (file) {
console.log('ファイルがドロップされました:', file.name)
const reader = new FileReader()
reader.onload = (e) => {
if (e.target && e.target.result) {
setImage(e.target.result as string)
analyzeImage(file)
}
}
reader.onerror = (e) => {
console.error('ファイル読み込みエラー:', e)
setError('ファイルの読み込み中にエラーが発生しました。')
}
reader.readAsDataURL(file)
}
}, [analyzeImage])
// react-dropzoneのフック
const { getRootProps, getInputProps, isDragActive } = useDropzone({
onDrop,
accept: {'image/*': []}
})
// 最大カテゴリ(最も高い確率の動物)を取得する関数
const getMaxCategory = useCallback(() => {
if (!result) return null
return result.reduce((max, item) => item.value > max.value ? item : max)
}, [result])
const maxCategory = getMaxCategory()
return (
<div className="min-h-screen bg-gradient-to-br from-blue-100 to-purple-100 py-12 px-4 sm:px-6 lg:px-8">
<div className="max-w-md mx-auto bg-white rounded-xl shadow-2xl overflow-hidden md:max-w-2xl">
<div className="p-8">
<h1 className="text-4xl font-bold text-center text-gray-800 mb-8">動物顔判定</h1>
<div className="mt-8">
{/* ドロップゾーン */}
<div
{...getRootProps()}
className="mb-8 relative rounded-lg overflow-hidden shadow-lg cursor-pointer"
style={{width: '100%', height: '250px'}}
>
<input {...getInputProps()} />
{image ? (
<Image src={image} alt="分析対象の顔" layout="fill" objectFit="cover" className="rounded-lg transition-transform duration-300 hover:scale-105" />
) : (
<div className="flex items-center justify-center h-full bg-gray-100">
<p className="text-gray-500 text-lg font-semibold">ここをクリックまたはドラッグ&ドロップで画像をアップロード</p>
</div>
)}
</div>
{/* エラーメッセージ */}
{error && (
<p className="text-red-500 text-center mb-4">{error}</p>
)}
{/* 結果の表示 */}
{result && maxCategory && (
<>
<h2 className="text-2xl font-bold text-center text-gray-800 mb-6 animate-fade-in">
あなたは{maxCategory.value}%、{maxCategory.name}です。
</h2>
{/* 円グラフ */}
<div className="bg-gray-50 rounded-lg p-4 shadow-inner mb-8">
<ResponsiveContainer width="100%" height={300}>
<PieChart>
<Pie
data={result}
cx="50%"
cy="50%"
labelLine={false}
outerRadius={100}
fill="#8884d8"
dataKey="value"
label={({ name, value }) => `${name} ${value}%`}
>
{result.map((_, index: number) => (
<Cell key={`cell-${index}`} fill={COLOR_LIST[index % COLOR_LIST.length]} />
))}
</Pie>
<Legend
formatter={(value, _, index) => <span style={{ color: COLOR_LIST[index % COLOR_LIST.length], fontWeight: 'bold' }}>{value}</span>}
/>
</PieChart>
</ResponsiveContainer>
</div>
</>
)}
</div>
</div>
</div>
</div>
)
}
app.py
こちらに関しては、一部のコメント修正、ファイル読み込みパスの修正、その他の多少の微調整以外は、AIが生成したコードそのままです。
import io
import logging
import torch
from flask import Flask, jsonify, request
from PIL import Image
from torchvision import models, transforms # type: ignore
app = Flask(__name__)
logging.basicConfig(level=logging.INFO)
# クラス名のリスト(学習時のクラス順序と同じにする)
class_names = ["cat", "dog", "frog", "monkey", "pig"]
# クラス数
num_classes = len(class_names)
# デバイスの設定
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# モデルの定義と重みの読み込み
def get_model(num_classes):
model = models.resnet18(weights=models.ResNet18_Weights.DEFAULT)
for param in model.parameters():
param.requires_grad = False
num_ftrs = model.fc.in_features
model.fc = torch.nn.Linear(num_ftrs, num_classes)
return model
model = get_model(num_classes)
model.load_state_dict(
torch.load("../model/resnet18_transfer_learning_final.pth", map_location=device)
)
model.to(device)
model.eval()
# 画像の前処理
def preprocess_image(image_bytes):
transform = transforms.Compose(
[
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
image = Image.open(io.BytesIO(image_bytes)).convert("RGB")
return transform(image).unsqueeze(0)
@app.route("/predict", methods=["POST"])
def predict():
app.logger.info("Received prediction request")
if "file" not in request.files:
app.logger.error("No file part in the request")
return jsonify({"error": "No file part in the request"}), 400
file = request.files["file"]
if file.filename == "":
app.logger.error("No file selected for uploading")
return jsonify({"error": "No file selected for uploading"}), 400
if file:
try:
app.logger.info(f"Processing file: {file.filename}")
image_bytes = file.read()
image = preprocess_image(image_bytes).to(device)
with torch.no_grad():
outputs = model(image)
probabilities = torch.nn.functional.softmax(outputs[0], dim=0)
# クラスごとの確率を取得
class_probs = {
class_names[i]: prob.item() for i, prob in enumerate(probabilities)
}
app.logger.info(f"Prediction results: {class_probs}")
return jsonify(class_probs)
except Exception as e:
app.logger.error(f"Error during prediction: {str(e)}")
return jsonify({"error": "An error occurred during prediction"}), 500
if __name__ == "__main__":
app.run(host="localhost", port=5000, debug=True)
余談ですが、Cursorを使用していて感動するのはコード補完機能です。まさに自分が書こうと思っていたコードを先に書いてくれることがしばしばあります。
さらに感動、むしろ恐怖すら感じるのがコメント補完です。コードを理解しているから、どのようなコメントが適切か分かるのは当然なのかもしれませんが、日本語という母国語で自分が書こうとしていたことを先に書かれると、正直ちょっと引いてしまいます(笑)。
まとめ
2回に分けてアプリ開発について記載しました。
後半のこの記事は、前々回の記事の続きのようなもので、v0+Cursorでの開発がどこまでできるかを知っていただければ幸いです。
アプリ開発でAIが生成したソースコードは、機械学習のモデル作成に比べると、かなり安心して使用できました。
理由は前回も述べた通り、機械学習のモデル作成などのデータ分析系のコードでは、出力結果からバグを発見するのが難しいのに対して、アプリの場合は「正常に動作しているか」の判断が明確だからです。
もちろん、裏で機能要件を満たしていないコードや、無駄が多いコードの可能性はありますので、ざっとは目を通しておくべきですが、それでも一から作成するよりは断然楽です。
大企業がリリースするような大規模なWebサービスの場合は慎重になる必要がありますが、個人開発者が「お遊び」アプリを開発・リリースするケースでは、かなりの効率化が期待できると思います。
こうなってくると、あとはアイデア勝負になるので、その点もAIに相談してみようと思います(笑)。
なお、せっかくなので Vercel にデプロイしようとしたのですが、Python 側の問題で諦めました。理由は、Vercel は AWS Lambda を使用しており、容量制限が 250MB なので、PyTorch のライブラリだけで容量を超過してしまうからです。では一体どうやって解決したか?
それは以下の記事をお読み下さい。


