










前回の記事で、PyCaratを使用して、MNISTの評価を行いました。
この時、compare_modelsを使用して、自動でいくつかのモデルの種類を試すことができましたが、そのモデルはデフォルトで用意されたものでした。
本記事では、デフォルトのものではなく、選択したモデルで評価する方法について記載します。
前提条件
本ソースコードは、Python3.7.5で起動するJupyter Lab上で実行されています。
また使用している各ライブラリのバージョンは以下の通りです。
- numpy(1.20.3)
- pandas(1.3.5)
- scikit-learn (0.23.2)
- pycarat(2.3.10)
PyCaratの分類器を使用するため以下のようにインポートしております。
from pycaret.classification import *MNISTの読み込みから前処理まで
詳しい説明は前回の記事と重複するので省略します。
MNISTの読み込み
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1,)教師データ、テストデータの分割
from sklearn.model_selection import train_test_split
seed = 42
data_train, data_test = train_test_split(data,
test_size=300,
train_size=1000,
random_state=seed,
stratify=label)DataFrame形式への変換
import pandas as pd
label = pd.DataFrame(mnist.target,columns=["label"])
label = label.astype("int64")
data = pd.concat([label, pd.DataFrame(mnist.data)] ,axis=1)PyCaratによる前処理
clf1 = setup(data = data_train, target="label",normalize=True,normalize_method="minmax",session_id=seed)
モデルの比較
前回は、以下の関数によってモデルの比較をしました。
best = compare_models()
上記を実行した場合は、デフォルトのモデルでの比較でした。
デフォルトで、どのようなモデルが用意されているかは、以下のコマンドで確かめることができます。
models()
これを実行すると以下のような結果が表示されます。
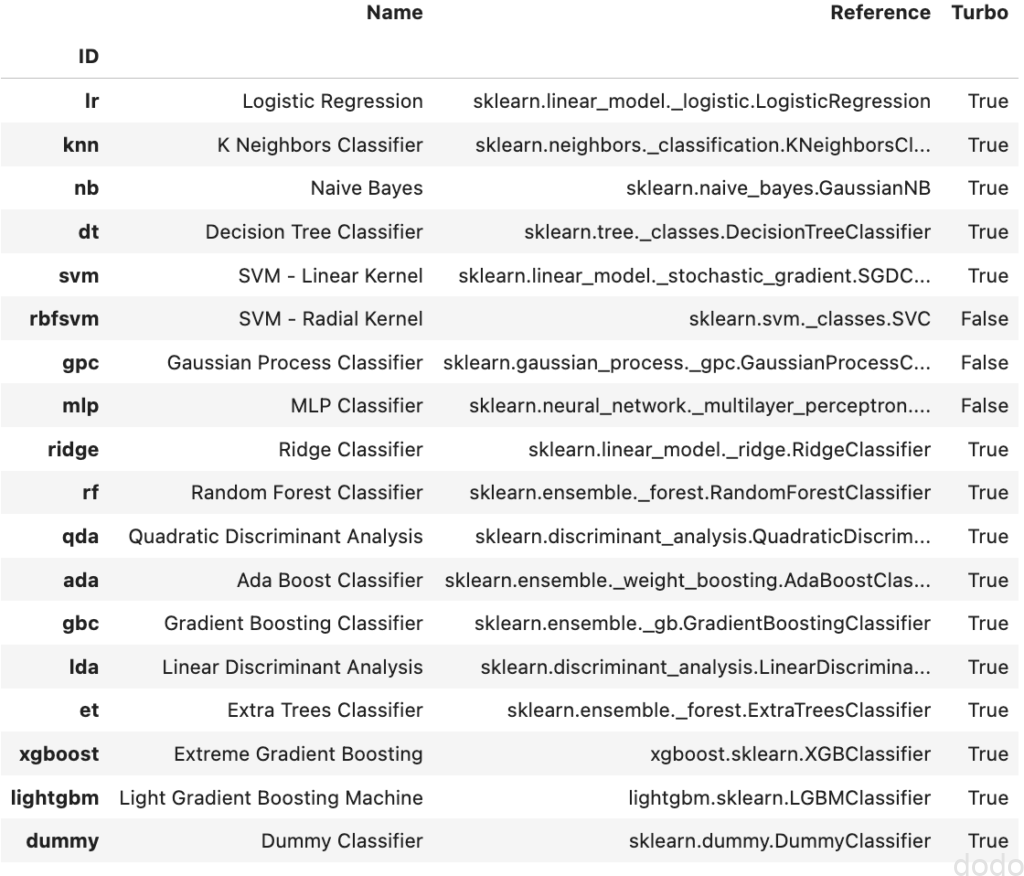 デフォルトのモデル
デフォルトのモデルcompare_modelsを実行すると、一番右のTurbo欄でTrueとなっているモデルについて交差検証を実施します。
ここでFalseかTrueかに関わらず、選択したモデルについてcompare_modelで実行させるためには、以下のように記載します。
best = compare_models(include=['rbfsvm', 'gpc', 'mlp'])
これを実行すると以下のような結果が表示されます。
 指定したモデルで比較
指定したモデルで比較なお、Jupyter Lab上で表示されるこの結果は、compare_modelsを実行後にpull()を実行することによりデータフレームとして取得できます。
df = pull()
「print(df)」を実行すると表示された情報を取得していることが確認できます。
Model Accuracy AUC Recall Prec. F1 \
mlp MLP Classifier 0.8713 0.9881 0.8677 0.8873 0.8679
gpc Gaussian Process Classifier 0.8455 0.9642 0.8398 0.8659 0.8432
rbfsvm SVM - Radial Kernel 0.8155 0.9809 0.8051 0.8373 0.8079
Kappa MCC TT (Sec)
mlp 0.8568 0.8592 0.836
gpc 0.8280 0.8308 2.371
rbfsvm 0.7945 0.7977 0.535 カスタムモデルの追加
models()で取得したリストに含まれないモデルもcompare_modelsの比較に追加することができます。
例として、以下のような0から9までをランダムで返すようなMNIST専用分類モデル(MNISTRandomeEstimator)を作成します。
from sklearn.base import BaseEstimator,ClassifierMixin
class MNISTRandomeEstimator(BaseEstimator,ClassifierMixin):
def __init__(self):
pass
def fit(self, X, y=None):
return self
def predict(self, X):
return np.round(9 * np.random.rand(X.shape[0]))カスタムクラスを作成するためには、scikit-learnの BaseEstimatorを継承して、fitとpredictを実装します。また分類器として認識させるためには、ClassfierMixinも多重継承(mixin)させます。
このカスタムモデルとMLPモデルを比較するには、以下を実行します。
rnd = MNISTRandomeEstimator()
best = compare_models(include=[rnd, 'mlp'])
実行結果は以下のようになります。
 カスタムモデルとの比較
カスタムモデルとの比較因みにですが、MNISTRandomeEstimatorのAccuracy=0.1187は、1/9=0.1111・・・とほぼ同じなので、ちゃんと実行されてそうです。
なお、ここまでは返り値のモデルはAccuracyがTOPのモデルだけでしたが、引数にn_selectを指定するとTOPから指定した数のモデルを配列で返すようにできます。
classifiers = compare_models(include=[rnd, 'mlp'] , n_select=2)グラフ出力
PyCaratには、plot_modelという簡単にグラフを出力できる関数が用意されています。
以下は、ROC曲線を出力します。
plot_model(classifiers[0], plot="auc")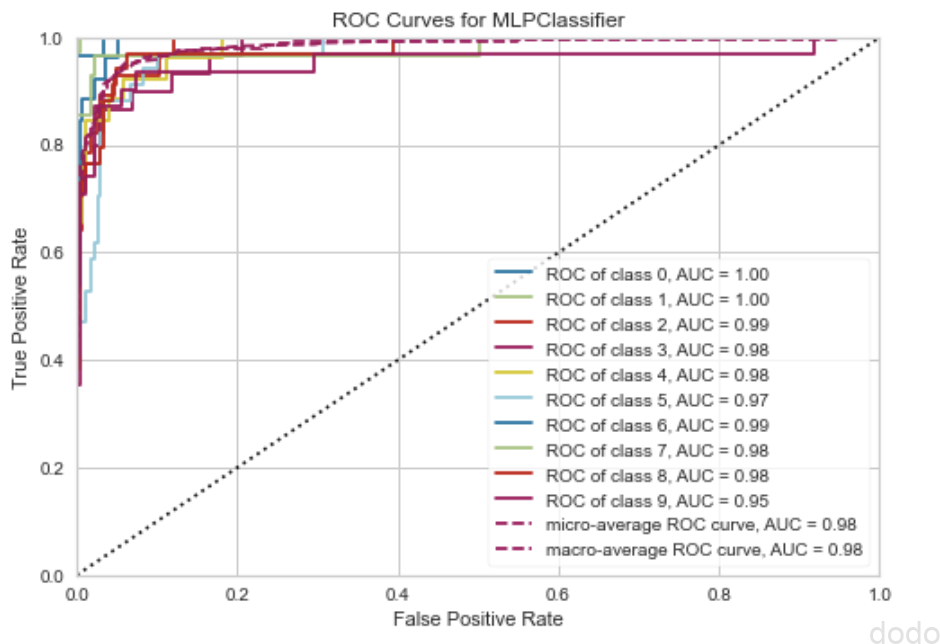 ROC曲線(MLP)
ROC曲線(MLP)
また、以下は、Confusion Matrixを出力します。
plot_model(classifiers[0], plot="confusion_matrix")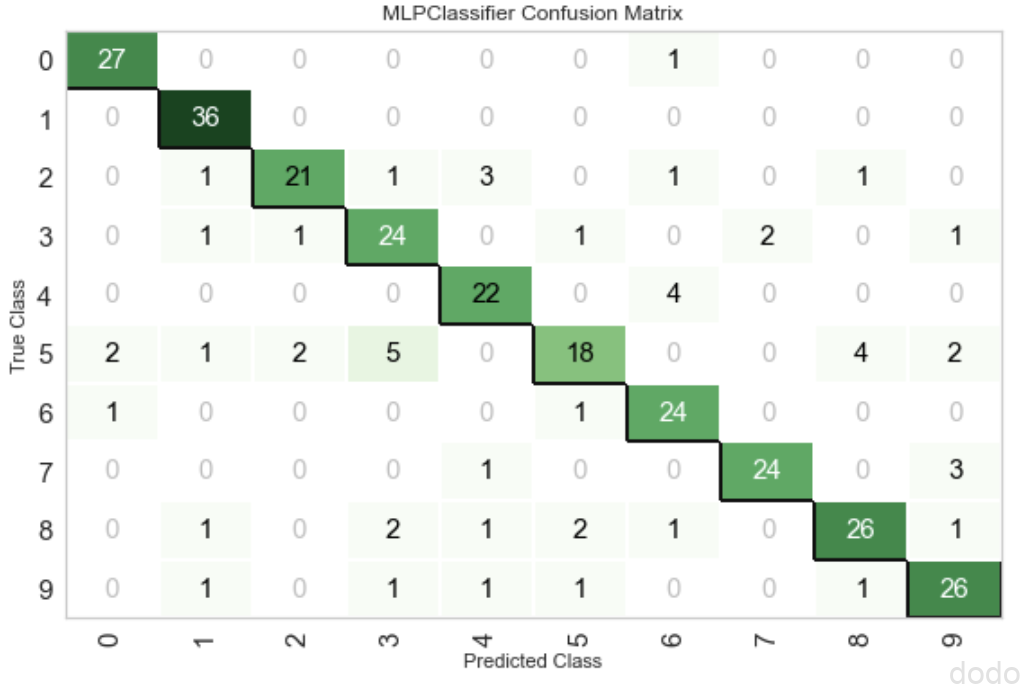 Confusion Matrix(MLP)
Confusion Matrix(MLP)なお、これらの結果はホールドアウト法で検証データについて予測した結果となります。
このように非常に簡単に分析でよく使われるグラフを出力できます。(他にも学習曲線や重PR曲線などなど・・)
ただし、例えば、複数のモデルについて並べて出力するなどは、できなそうです。(一応、matplotlibのaxisを引数で渡すことはできましたが、うまくいきませんでした・・)
自分の好きなレイアウトで出力するためには、自分でモデルにデータを渡して分析させた結果をmatplotlibでグラフ化した方が良さそうです。
まとめ
以上、PyCaratのcompare_modelsで任意のモデルを使う方法について記載しました。
これらの方法によって、カスタムクラスはもちろん、同じ種類の分類器で異なるパラメータのものを比較する事もできます。
ただ、グラフ化の関数(plot_model)については、簡単に使える分、応用が効かず、自分の好きなグラフを好きなレイアウトで表示するには、予測結果のデータを用いてmatplotlibで表示する方が良いかなと思いました。
機会があれば、またPyCaratのもう少し応用した使い方の記事も書こうと思います。


