










前回は、アンサンブル学習のはじめの一歩として、モデルの予測結果の多数決をとる手法と平均をとる手法について説明しました。
今回は、一歩進んでバンギングという手法について解説し、実際に実装して行きます。
事前準備
前回とほぼ同様ですが、importしているライブラリが異なります。
前提条件
本ソースコードは、Python3.10.6で起動するJupyter Lab上で実行されています。
また使用している各ライブラリのバージョンは以下の通りです。
- numpy(1.22.4)
- pandas(1.4.3)
- scikit-learn (1.1.2)
タイタニックデータ取得+前処理
今回もタイタニックのデータを使用します。
データの取得と前処理については、以下の記事に詳細を記載しているため、今回はソースコードのみを掲載します。

(1)必要なライブラリをインポートします。
import numpy as np
import pandas as pd
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler,OneHotEncoder
from sklearn.tree import DecisionTreeClassifier
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import BaggingClassifier,RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.base import ClassifierMixin,BaseEstimator
from sklearn.utils import resample
import warnings
warnings.simplefilter('ignore')
(2)データを読み込んで教師データとテストデータに分割します。
X, y = fetch_openml(data_id=40945, as_frame=True, return_X_y=True)
categorical_features = ["sex", "embarked"]
numerical_features = ["age", "sibsp", "parch", "fare", "pclass"]
X = X[categorical_features + numerical_features]
seed = 42
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=seed)
(3)前処理のためのパイプラインを構築します。
numerical_transformer= Pipeline(
steps=
[
("imputer", SimpleImputer(strategy="mean")),
("scaler", StandardScaler())
]
)
categorical_transformer = Pipeline(
steps =
[
("imputer", SimpleImputer(strategy="most_frequent")),
('onehot', OneHotEncoder(drop='if_binary'))
]
)
transformer = ColumnTransformer(
[
("cat", categorical_transformer, categorical_features),
("num", numerical_transformer, numerical_features),
],
)バギング
バギングの手法として有名なものに、ランダムフォレストがあります。
ランダムフォレストは、教育データからデータを復元抽出することにより、データと特徴量が異なる決定木を複数作成して、それらの予測の平均を最終的な予測として出力します。
ランダムフォレストの1個1個の決定木は弱学習器と呼ばれ、それ自体は精度が良くありませんが、その予測結果を統合することによってバリアンスが低くなり、全体の精度が良くなります。
そこそこの精度の弱学習器が集まった方が、良い精度になるように学習した1つの学習器よりも精度が良いのです。
バギングのイメージを以下に示します。
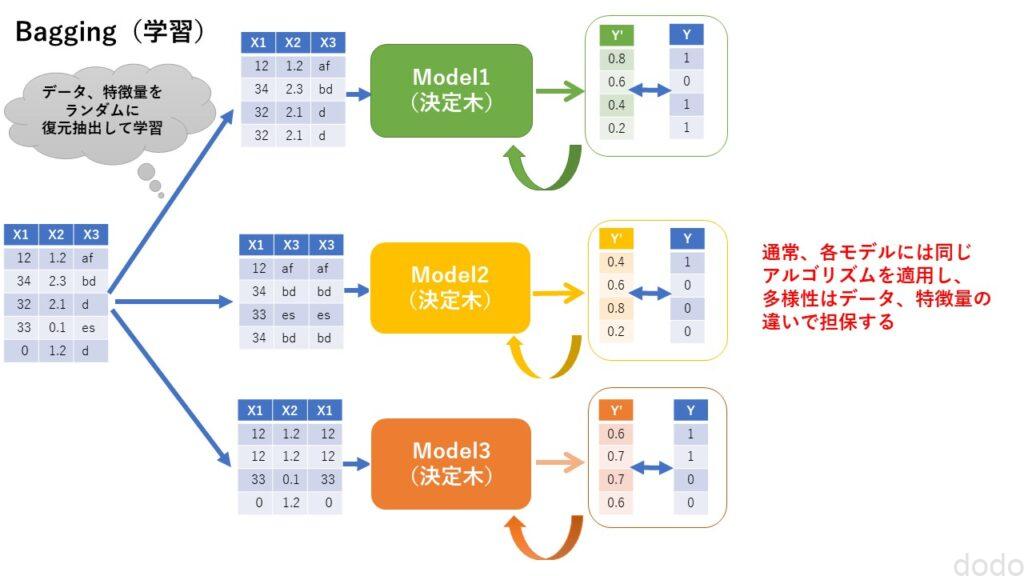 バギング(学習)
バギング(学習)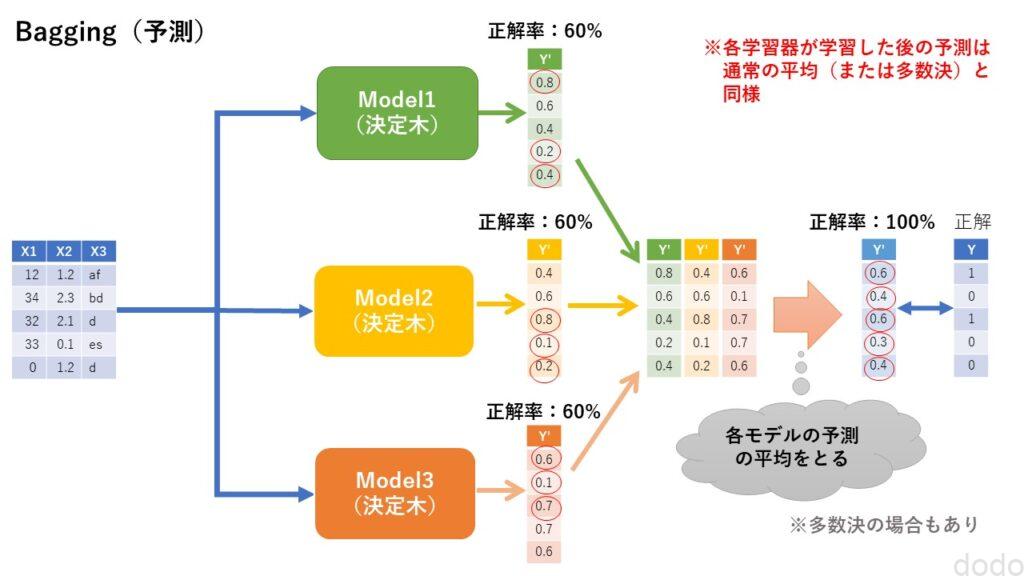 バギング(予測)
バギング(予測)スクラッチで実装
それでは実際に実装して行きましょう。
まずは頑張ってスクラッチで実装してみましょう。
前回と同様、分類器と前処理を行うtransformerを結合させたパイプラインを作ります。
def pipeline(transformer,estimator):
model = Pipeline(
[
("transformer", transformer),
("classifier", estimator)
]
)
return model
また分類器の平均をとる分類器を作成します。(これも前回と同じものです。)
class SimpleAveragingClassifier(BaseEstimator, ClassifierMixin):
def __init__(self,estimators):
self.estimators = estimators
def fit(self, X, y):
for estimator in self.estimators:
estimator.fit(X, y)
return self
def predict(self, X):
base_pred_proba = [model.predict_proba(X) for model in self.estimators]
predict_proba = np.mean(base_pred_proba, axis=0)
pred = np.argmax(predict_proba, axis=1)
#yの型に戻す(ClassifierMixinでのscore計算のため)
pred = pred.astype(str)
return pred
まず、単に100個の同じ決定木を作って平均をとってみます。
models = [DecisionTreeClassifier(random_state=seed) for _ in range(100)]
simple_average_model = pipeline(transformer,SimpleAveragingClassifier(estimators=models))
simple_average_model.fit(X_train, y_train)
print(f"train score = {simple_average_model.score(X_train,y_train)}")
print(f"test score = {simple_average_model.score(X_test,y_test)}")実行結果
train score = 0.9724770642201835
test score = 0.7621951219512195
この結果は単独の決定木の予測結果と変わりません。(集まれば結果が良くなると言っても同じ結果を出力している決定木を集めても意味がありません。)
なので、それぞれの決定木で教師データをランダムに復元抽出するような分類器クラスを作成します。(今回は簡単のため決定木専用とします。)
またランダムと言っても再現性を保つために、渡されたseedを元にnumpy.random.RandomStateを生成して、そこから乱数を生成し、その乱数(random_state)を復元抽出(resample)の引数とモデルの引数の両方に使用します。
class SimpleBaggingClassifier(BaseEstimator, ClassifierMixin):
def __init__(self, n_estimators, max_samples=None, random_state=0):
self.n_estimators = n_estimators
self.max_samples = max_samples
self.seed = random_state
def fit(self, X, y):
if self.max_samples is None:
self.max_samples = len(y)
self.estimators_ = []
random_state = np.random.RandomState(self.seed)
rndarr = random_state.randint(np.iinfo(np.int32).max, size=self.n_estimators)
for i in range(self.n_estimators):
re_X, re_y = resample(X, y, n_samples = self.max_samples, random_state=rndarr[i])
estimator = DecisionTreeClassifier(random_state=rndarr[i])
estimator.fit(re_X, re_y)
self.estimators_.append(estimator)
return self
def predict(self, X):
base_pred_proba = [model.predict_proba(X) for model in self.estimators_]
predict_proba = np.mean(base_pred_proba, axis=0)
pred = np.argmax(predict_proba, axis=1)
#yの型に戻す(ClassifierMixinでのscore計算のため)
pred = pred.astype(str)
return pred※ラベルは’0′,’1’固定で汎用的ではないので注意してください。
作成した分類器を使用して、教師データを復元抽出する決定木を100個作成してその予測の平均を出力します。
simple_bagging_model =pipeline(transformer,SimpleBaggingClassifier(
n_estimators=100, random_state=seed ))
simple_bagging_model.fit(X_train, y_train)
print(f"train score = {simple_bagging_model.score(X_train,y_train)}")
print(f"test score = {simple_bagging_model.score(X_test,y_test)}")実行結果
train score = 0.9724770642201835
test score = 0.7957317073170732
若干ですが、1つの決定木の結果よりも良い予測結果になっています。
ちなみに、今回、データの復元抽出のみ実施して決定木のrandom_stateを固定していたら、単独の決定木よりも結果が悪くなりました・・。多様性を出すためには決定木のrandome_stateを変えることも重要なようです。
BaggingClassifierで実装
scikit-learnには、バギングをするためのクラスとしてBaggingClassifierが用意されています。
以下は決定木を100個使用した場合の実装です。
bagging_model =pipeline(transformer,BaggingClassifier(n_estimators=100, random_state=seed ))
bagging_model.fit(X_train, y_train)
print(f"train score = {bagging_model.score(X_train,y_train)}")
print(f"test score = {bagging_model.score(X_test,y_test)}")実行結果
train score = 0.9724770642201835
test score = 0.7865853658536586
なんと、(たまたまでしょうが)私がスクラッチで実装した方が結果が良かったです。
(本当は、中身の乱数生成のソースとかを読んで、全く同じ結果にしたかったのですが、挫折しました・・。)
なお、BaggingClassifierのデフォルトは、特徴量に関しては復元抽出しませんが、以下のように引数を設定すると特徴量も復元抽出します。
bagging_model =pipeline(transformer,BaggingClassifier(
n_estimators=100, random_state=seed ,
bootstrap_features=True))
bagging_model.fit(X_train, y_train)
print(f"train score = {bagging_model.score(X_train,y_train)}")
print(f"test score = {bagging_model.score(X_test,y_test)}")実行結果
train score = 0.9500509683995922
test score = 0.7987804878048781
特徴量を復元抽出することによって、若干ですが精度が良くなりました。
なお、以下のように引数を設定すると最大のデータ数と最大の特徴量の数を制限できます。(以下の例ではデータ数の50%、特徴量の70%を使用するように設定)
bagging_model =pipeline(transformer,BaggingClassifier(
n_estimators=100, random_state=seed ,
bootstrap_features=True, max_samples=0.5, max_features=0.7))
bagging_model.fit(X_train, y_train)
print(f"train score = {bagging_model.score(X_train,y_train)}")
print(f"test score = {bagging_model.score(X_test,y_test)}")実行結果
train score = 0.9021406727828746
test score = 0.8201219512195121
もちろん、いつもうまく行くとは限りませんが、最大数を指定することによって精度が改善しました。
またBaggingClassifierのモデルはデフォルトは決定木ですが、それ以外も指定できます。
最後、おまけでロジスティック回帰を100個、アンサンブル学習させてみましょう。
bagging_model =pipeline(transformer,BaggingClassifier(
base_estimator=LogisticRegression(random_state=seed),
n_estimators=100, random_state=seed ))
bagging_model.fit(X_train, y_train)
print(f"train score = {bagging_model.score(X_train,y_train)}")
print(f"test score = {bagging_model.score(X_test,y_test)}")実行結果
train score = 0.781855249745158
test score = 0.801829268292683
ロジスティック回帰も単独の結果と比べると(前回参照)、良い精度が出ています。
RandomForestClassifierで実装
scikit-learnでバギングを実行できるクラスはBaggingClassifierの他におなじみのRandomForestClassifierがあります。
RandomForestClassifierとBaggingClassifierには以下のような違いがあります。
- BaggingClassifierは決定木以外も使用できるが、RandomForestClassifierは決定木に特化している。
- RandomForestClassifierは決定木のハイパーパラメータも指定できる。(BaggingClassifierで決定木のハイパーパラメータ指定するためにはDecisionTreeClassifierを引数に与える必要がある。)
- デフォルトの設定が異なる。(RandomForestClassifierはデフォルトで最大で使用する特徴量の数が全特徴量の平方根であることなど)
- 得られる情報が異なる。(「重要度(feature importance)がBaggingClassifierからは取得できない。)
では最後にRandomForestClassifierを使用してバギングを実行してみましょう。
rf_model =pipeline(transformer,RandomForestClassifier(
n_estimators=100, random_state=seed))
rf_model.fit(X_train, y_train)
print(f"train score = {rf_model.score(X_train,y_train)}")
print(f"test score = {rf_model.score(X_test,y_test)}")実行結果
train score = 0.9724770642201835
test score = 0.7926829268292683
BaggingClassifierと同じくデフォルトの設定だとかなり過学習しており、あまり精度が良くありませんが、パラメータを調整することによって精度を高めることができます。
rf_model =pipeline(transformer,RandomForestClassifier(
n_estimators=100, max_samples=0.4, max_features=0.7, random_state=seed))
rf_model.fit(X_train, y_train)
print(f"train score = {rf_model.score(X_train,y_train)}")
print(f"test score = {rf_model.score(X_test,y_test)}")実行結果
train score = 0.9021406727828746
test score = 0.8323170731707317
まとめ
以上、バギングについてスクラッチ実装とscikit-learnのBaggingClassifier、RandomForestClassifierによる実装を見てきました。
それぞれの決定木(弱学習器)に多様性を持たせ、あえて学習するデータや特徴量を制限することによって、「アンサンブル」した時の精度が良くなるというのは興味深いです。
次回は、ブースティングについて、解説、実装していきたいと思います。

