









アンサンブル学習は、機械学習で精度を上げるための非常に有効な手法です。
アンサンブル学習は複数のモデルの予測結果を統合して、最終的な予測結果を算出します。
複数の多様性があるモデルを使用することにより、バリアンスが抑えられ、個別のモデルよりも良い予測結果を出すことができます。
なお、モデルに多様性を持たせるためには、以下のような方法が考えられます。
- アルゴリズムが異なる。
- ハイパーパラメータが異なる。
- データが異なる。
- 特徴量が異なる。
アンサンブル学習にはいくつかの手法があり、どの手法を選択するかによって、どのような多様性を持たせるかということも変わってきます。
本記事では、アンサンブル学習の第一歩として、最もシンプルな方法である多数決と平均について解説、実装していきます。
事前準備
前提条件
本ソースコードは、Python3.10.6で起動するJupyter Lab上で実行されています。
また使用している各ライブラリのバージョンは以下の通りです。
- numpy(1.22.4)
- pandas(1.4.3)
- scikit-learn (1.1.2)
- scipy(1.9.1)
タイタニックデータ取得+前処理
今回もタイタニックのデータを使用します。
データの取得と前処理については、以下の記事に詳細を記載しているため、今回はソースコードのみを掲載します。

(1)必要なライブラリをインポートします。
import numpy as np
import pandas as pd
import scipy.stats as stats
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler,OneHotEncoder
from sklearn.tree import DecisionTreeClassifier
from sklearn.compose import ColumnTransformer
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import VotingClassifier
from sklearn.base import ClassifierMixin,BaseEstimator
from sklearn.svm import SVC
import warnings
warnings.simplefilter('ignore')
(2)データを読み込んで教師データとテストデータに分割します。
X, y = fetch_openml(data_id=40945, as_frame=True, return_X_y=True)
categorical_features = ["sex", "embarked"]
numerical_features = ["age", "sibsp", "parch", "fare", "pclass"]
X = X[categorical_features + numerical_features]
seed = 42
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=seed)
(3)前処理のためのパイプラインを構築します。
numerical_transformer= Pipeline(
steps=
[
("imputer", SimpleImputer(strategy="mean")),
("scaler", StandardScaler())
]
)
categorical_transformer = Pipeline(
steps =
[
("imputer", SimpleImputer(strategy="most_frequent")),
('onehot', OneHotEncoder(drop='if_binary'))
]
)
transformer = ColumnTransformer(
[
("cat", categorical_transformer, categorical_features),
("num", numerical_transformer, numerical_features),
],
)多数決
英語では、Voting(投票)と言いますが、要するに複数のモデルの結果で多数決を取る手法です。
分類で1か0かを決定する場合は、3つのモデルで2つが「1」と予測して1つが「0」と予測した場合、「1」が最終的な予測結果です。
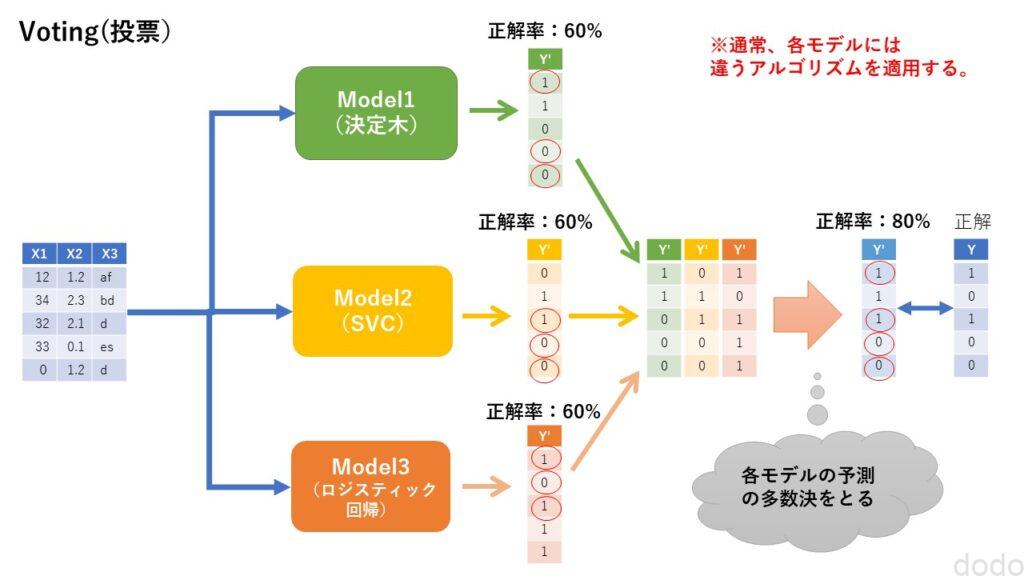 多数決
多数決
では実際に実装しましょう。
まずは、分類器と前処理を行うtransformerを結合させたパイプラインを作ります。複数の分類器について繰り返しこの処理を行うので以下の関数を作成して使用します。
def pipeline(transformer,estimator):
model = Pipeline(
[
("transformer", transformer),
("classifier", estimator)
]
)
return model
今回、モデルに多様性を持たせるために3つのアルゴリズムが異なる分類器(決定木、SVC、ロジスティック回帰)を使用してアンサンブル学習を実行します。
それぞれのモデルを作成して、教師データとテストデータの正解率を表示させます。
(1)決定木
#決定木のモデルを作成して精度を表示する。
model1 = pipeline(transformer,DecisionTreeClassifier(random_state=seed))
model1.fit(X_train,y_train)
print(f"train score = {model1.score(X_train,y_train)}")
print(f"test score = {model1.score(X_test,y_test)}")実行結果
train score = 0.9724770642201835
test score = 0.7621951219512195
(2)SVC
model2 = pipeline(transformer,SVC(random_state=seed, probability=True))
model2.fit(X_train,y_train)
print(f"train score = {model2.score(X_train,y_train)}")
print(f"test score = {model2.score(X_test,y_test)}")実行結果
train score = 0.8134556574923547
test score = 0.8262195121951219
(3)ロジスティック回帰
model3 = pipeline(transformer,LogisticRegression(random_state=seed))
model3.fit(X_train,y_train)
print(f"train score = {model3.score(X_train,y_train)}")
print(f"test score = {model3.score(X_test,y_test)}")実行結果
train score = 0.781855249745158
test score = 0.7987804878048781
全くパラメータチューニングしていない状態ですが、この中ではSVCが最も良い精度が出ています。(決定木は教師データの場合のみ精度が良いの過学習の傾向が出ています。)
では、それぞれの結果の多数決をとってみましょう。
まずはそれぞれのモデルの予測を実行して、結果の多数決をとる関数を作成します。
def get_ensemble_score_voting(models, X, y):
base_pred = [np.where(model.predict(X) == '0', -1, 1) for model in models]
pred = np.sign( np.sum(base_pred, axis=0))
pred = np.where(pred == -1, 0, 1)
score = np.sum((pred == y.to_numpy().astype(int)).astype(int))/len(y)
return score
この関数を呼び出して正解率を表示します。
models = [model1,model2,model3]
print(f"train score = {get_ensemble_score_voting(models, X_train, y_train)}")
print(f"test score = {get_ensemble_score_voting(models, X_test, y_test)}")実行結果
train score = 0.8338430173292558
test score = 0.8323170731707317
テストデータの正解率が3つのモデルの正解率よりも高くなっているのがわかります。(常にうまくいくとは限りません。)
以下のような独自の分類器を作成することで上記と同じことをスマートに実現することができます。(ラベルは’0′,’1’固定で汎用的ではないので注意してください。)
class SimpleVotingClassifier(BaseEstimator, ClassifierMixin):
def __init__(self,estimators):
self.estimators = estimators
def fit(self, X, y):
for estimator in self.estimators:
estimator.fit(X, y)
return self
def predict(self, X):
base_pred = [np.where(model.predict(X) == '0', -1, 1) for model in self.estimators]
pred = np.sign( np.sum(base_pred, axis=0))
#yの型に戻す(ClassifierMixinでのscore計算のため)
pred = np.where(pred == -1, '0', '1')
return pred
ClassifierMixinを継承したクラスを作成してfitとpredictを実装すれば親クラスでscoreを計算してくれるので、バグも少なく済むでしょう。
BaseEstimatorは本コードに限っては、継承しなくても動作します。ただしBaseEstimatorを継承すると内部のパラメータ(使用している分類器などの情報を取得することができます。)
以下、作成した分類器を呼び出して実行した結果です。(同じ結果になります。)
est1 = DecisionTreeClassifier(random_state=seed)
est2 = SVC(random_state=seed, probability=True)
est3 = LogisticRegression(random_state=seed)
simple_vote_model = pipeline(transformer,SimpleVotingClassifier(estimators=[est1, est2, est3]))
simple_vote_model.fit(X_train, y_train)
print(f"train score = {simple_vote_model.score(X_train,y_train)}")
print(f"test score = {simple_vote_model.score(X_test,y_test)}")実行結果
train score = 0.8338430173292558
test score = 0.8323170731707317
scikit-learnには、VotingClassifierというクラスがあり、これを使用することで、同じ結果を得ることができます。(voting=”hard”の場合)
以下は、VotingClassifierを使用して多数決をとったコードで上の結果と全く同じ実行結果が出力されます。(シードを固定していることに注意)
est1 = DecisionTreeClassifier(random_state=seed)
est2 = SVC(random_state=seed, probability=True)
est3 = LogisticRegression(random_state=seed)
voting_model_hard = pipeline(transformer,VotingClassifier(estimators=[
('est1', est1), ('est2', est2), ('est3', est3)],
voting='hard'))
voting_model_hard.fit(X_train, y_train)
print(f"train score = {voting_model_hard.score(X_train,y_train)}")
print(f"test score = {voting_model_hard.score(X_test,y_test)}")実行結果
train score = 0.8338430173292558
test score = 0.8323170731707317
学習を実行させるたびにest1,est2,est3を定義しなおしているのは、(横着して)分類器の内部で参照を切り替えてないため、一度使用した後は学習済になってしまっているからです。(scikit-learnのライブラリはやっています。)
平均
平均は、文字通り予測結果の平均を取ることです。
回帰の場合は、わかりやすいと思いますが、分類の場合はどういう意味でしょう。
分類の場合は、「0」「1」のようなラベルではなく、確率の平均を計算します。
例えば、3つのモデルの予測が、45%、45%、90%の場合、50%を閾値とすれば、ラベルで多数決を取れば、0、0、1なので、結果は「0」です。
しかし、確率で平均を取れば、60%になるので、結果は「1」です。
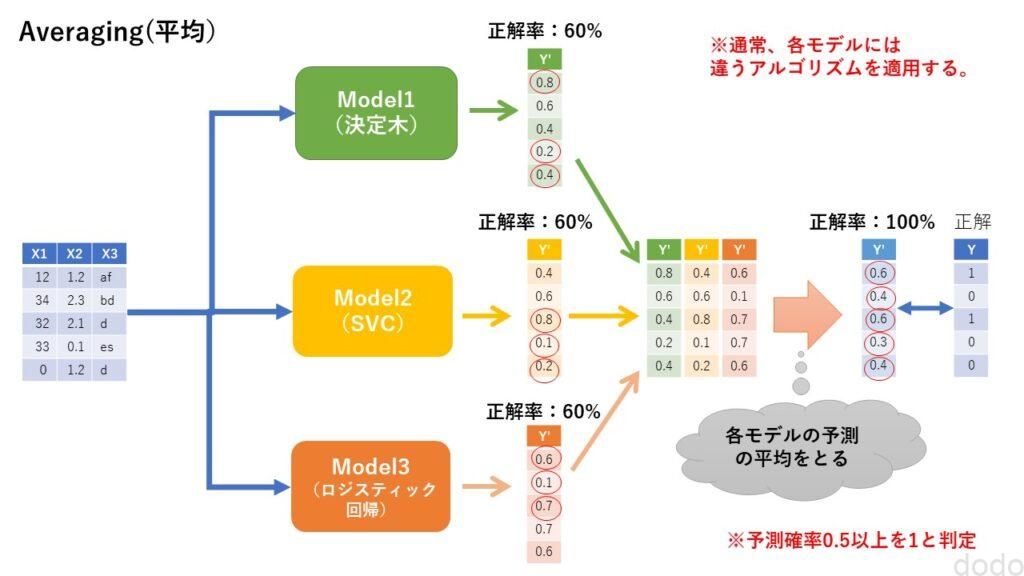 平均
平均SVCのようにその特性から確率を算出しないアルゴリズムもあります。本記事ではコード上でSVCのクラスを呼び出すときに「probability=True」を指定していますが、これは、内部で交差検証をすることにより、無理やり確率を出力するためです。通常より計算に時間がかかるので「probability=True」とする場合は注意が必要です。
では実際に実装しましょう。
モデルは、多数決で使用したものをそのまま流用します。
それぞれのモデルの予測結果(確率)を平均する関数を作成します。
def get_ensemble_score_averaging(models, X, y):
base_pred_proba = [model.predict_proba(X) for model in models]
predict_proba = np.mean(base_pred_proba, axis=0)
pred = np.argmax(predict_proba, axis=1)
score = np.sum((pred == y.to_numpy().astype(int)).astype(int))/len(y)
return score
この関数を呼び出して正解率を表示します。
print(f"train score = {get_ensemble_score_averaging(models, X_train, y_train)}")
print(f"test score = {get_ensemble_score_averaging(models, X_test, y_test)}")実行結果
train score = 0.9031600407747197
test score = 0.8262195121951219
今回は、テストデータでは多数決より低い精度になりましたが、一般的な傾向としては、多数決より平均の方が良い精度が出るようです。
多数決の場合と同様、分類器のクラスを作成して、スマートに実装することができます。(ラベルは’0′,’1’固定で汎用的ではないので注意してください。)
class SimpleAveragingClassifier(BaseEstimator, ClassifierMixin):
def __init__(self,estimators):
self.estimators = estimators
def fit(self, X, y):
for estimator in self.estimators:
estimator.fit(X, y)
return self
def predict(self, X):
base_pred_proba = [model.predict_proba(X) for model in self.estimators]
predict_proba = np.mean(base_pred_proba, axis=0)
pred = np.argmax(predict_proba, axis=1)
#yの型に戻す(ClassifierMixinでのscore計算のため)
pred = pred.astype(str)
return pred
以下、作成した分類器を呼び出して実行した結果です。(同じ結果になります。)
est1 = DecisionTreeClassifier(random_state=seed)
est2 = SVC(random_state=seed, probability=True)
est3 = LogisticRegression(random_state=seed)
simple_average_model = pipeline(transformer,SimpleAveragingClassifier(estimators=[est1, est2, est3]))
simple_average_model.fit(X_train, y_train)
print(f"train score = {simple_average_model.score(X_train,y_train)}")
print(f"test score = {simple_average_model.score(X_test,y_test)}")実行結果
train score = 0.9031600407747197
test score = 0.8262195121951219
多数決の場合と同じくsckit-learnのVotingClassifierを使用すると(引数を変更してvoting=”soft”とする)、上記の結果と同じ予測結果を得るることができます。
est1 = DecisionTreeClassifier(random_state=seed)
est2 = SVC(random_state=seed, probability=True)
est3 = LogisticRegression(random_state=seed)
voting_model_soft = pipeline(transformer,VotingClassifier(estimators=[
('est1', est1), ('est2', est2), ('est3', est3)],
voting='soft'))
voting_model_soft.fit(X_train, y_train)
print(f"train score = {voting_model_soft.score(X_train,y_train)}")
print(f"test score = {voting_model_soft.score(X_test,y_test)}")実行結果
train score = 0.9031600407747197
test score = 0.8262195121951219
加重平均
VotingClassifierでは、それぞれのモデルに重みを持たせることができます。
それぞれのモデルの個別の結果を見るとSVCの精度が最も良く、次に良いのがロジスティック回帰、最後が決定木でした。
精度が良いモデルの結果を重視するため、決定木、SVC、ロジスティック回帰の重みを適当に1、2、1.5として加重平均を計算します。
est1 = DecisionTreeClassifier(random_state=seed)
est2 = SVC(random_state=seed, probability=True)
est3 = LogisticRegression(random_state=seed)
voting_model_soft_weight = pipeline(transformer,VotingClassifier(estimators=[
('est1', est1), ('est2', est2), ('est3', est3)],
weights=[1,2,1.5] ,voting='soft'))
voting_model_soft_weight.fit(X_train, y_train)
print(f"train score = {voting_model_soft_weight.score(X_train,y_train)}")
print(f"test score = {voting_model_soft_weight.score(X_test,y_test)}")実行結果
train score = 0.8419979612640163
test score = 0.8384146341463414
実行結果から、テストデータの予測精度が改善されたのがわかります。(重みは適当なので、常にうまくいくとは限りません。)
なお、ここでは重みを適当に決めましたが、その重みをもっと論理的に決定する方法として発展させた手法がブースティングやスタッキングです。
まとめ
以上、アンサンブル学習の最も基本的な多数決と平均について、解説、実装しました。
非常にシンプルなロジックですが、予測結果の多数決や平均をとる事によって精度が向上するというのは、興味深いです。
次回は、さらに一歩進んで、バギングについて、解説、実装していきたいと思います。

