










前回、v0とCursorを使用していくつかのアプリを試作しましたが、今回は機械学習を組み合わせてアプリを作成してみたいと思います。
作成するアプリの仕様は以下の通りです。
顔写真をアップロードすると、自分の顔が「犬顔」「猫顔」「猿顔」「豚顔」「蛙顔」のどれに近いかを判定します。また、それぞれの割合(犬30%、猫20%など)を円グラフで表示します。
内部ロジックとしては、機械学習を用いて犬、猫、猿、豚、蛙の画像で分類器を作成し、そこに人間の顔をアップロードして判定させるという仕組みです。(アプリの仕様上、実際にはどんな画像をアップロードしても問題ありませんが。)
では、実際にアプリを作成していきましょう。
本記事では、モデル(分類器)の作成までについて解説します。
前提
本アプリ作成で使用した環境・リソースは以下の通りです。
- 分類器の学習には、オープンデータ「Google Open Images Dataset V6」を使用しました。
- オープンデータの取得および分類器の作成は、Google Colab上のNotebookで実施し、GPUはL4を選択しました。
- ソースコードの作成にはv0とCursor(LLMにはClaude 3.5 Sonnetを使用)を利用しました。全体の8割ほど(体感)は出力されたコードをそのまま使用しています。
- その他、問題解決のためにChatGPTおよびGensparkを活用しました。
オープンデータの取得
犬、猫、猿、豚、蛙の画像を大量に集める必要があり、ChatGPTに相談したところ、以下の候補が提示されました。(出力はそのまま引用しています)
- ImageNet:多くのカテゴリに分類された大規模なデータセットで、動物の画像も豊富です。ライセンスや利用規約に注意しながら利用することをお勧めします。
- CIFAR-10:比較的小規模ながら、犬や猫などの動物カテゴリが含まれているデータセットです。
- OpenImages:Googleが提供する大規模データセットで、ラベル付きの画像が多数存在します。
さらに、Webスクレイピングによる方法(検索して画像を集める)も提案されましたが、Googleの検索結果は規約によりスクレイピングが禁止されているため、Google Custom Search APIを使用する必要がありました。しかし、無料枠が少なく、大量の画像を集める場合は有料になります。
結論として、上記のオープンデータの中からOpenImageのV6である「Open Images Dataset V6」を選択しました。
OpenImagesから画像を取得する方法については、ChatGPTおよびCursor(Claude 3.5 Sonnet)の双方に問い合わせ、さまざまな方法が提案されましたが、最終的にAWSコマンドラインインターフェイス(AWS CLI)をPythonから使用する方法を選択しました。(データはAWS上にあるためです。)
この作業はGoogle Colab上で実施しました。
まずは新規のNotebookを作成してGoogle Driveにマウントします。
from google.colab import drive
drive.mount('/content/drive')
Google Driveにマウントする理由は、取得したデータをGoogle Driveに保存するためです。Google Colabのインスタンスではデータは永続化されないため、接続を切断するとデータも削除されてしまいます。
次にAWSクライアントをインストールします。
!pip install awscli
必要なライブラリをインポートします。
import pandas as pd
import os
from tqdm import tqdm
import subprocess
import logging
import sys
エラーが発生した場合に備えて、一応ログ出力を行うようにしています。(この程度のコードであれば、printで十分だとは思いますが、エラーが発生した際にCursorに相談したところ、この方法でログを出力するようにとのアドバイスを受けました。)
logging.basicConfig(
level=logging.INFO, force=True,stream=sys.stdout,format="%(asctime)s - %(levelname)s - %(message)s"
)
まず、全データの情報が格納されているメタデータを取得して読み込みます。(かなり大きなファイルで、数ギガバイトあります…)
# Open Imagesのメタデータをダウンロード
!wget https://storage.googleapis.com/openimages/v6/oidv6-train-annotations-bbox.csv
# メタデータを読み込む
df = pd.read_csv("oidv6-train-annotations-bbox.csv")
print(f"メタデータの読み込みが完了しました。Shape: {df.shape}")
最後にShapeを出力していますが、結果は以下の通りで、約1,500万件のデータがあることが確認できました。
メタデータの読み込みが完了しました。Shape: (14610229, 21)
この中から、取得するデータ分(各カテゴリー1,000枚)のパスだけを抜き出し、カテゴリーごとにCSVファイルを作成します。その後、このCSVファイルを読み込んで実際のデータを取得します。
# ラベルの定義
labels = {
"/m/0bt9lr": "dog",
"/m/01yrx": "cat",
"/m/08pbxl": "monkey",
"/m/068zj": "pig",
"/m/09ld4": "frog",
}
# 画像IDを取得
for label_id, label_name in labels.items():
image_ids = df[df["LabelName"] == label_id]["ImageID"].unique()[:1000]
with open(f"/content/drive/MyDrive/open_images_v6/{label_name}_image_ids.txt", "w") as f:
for image_id in image_ids:
f.write(f"{image_id}\n")
print(f"{label_name}の画像ID数: {len(image_ids)}")
ここでラベルの定義部分についてですが、犬、猫、猿、豚、蛙の画像が欲しいと指定した際、Cursorが自動でコードを生成してくれました。しかし、Cursor(などのAI)を使わない場合や、本当に正しいか確認する場合は、以下のサイトで「Class Names」をページ検索し、そのボタンを押すことでクラスの英語名のキーとパス(つまりラベルの定義部分)をダウンロードして確認できるので、それを参照してください。
https://storage.googleapis.com/openimages/web/download.html
なお、最後の行の出力結果は以下の通りです。
dogの画像ID数: 1000
catの画像ID数: 1000
monkeyの画像ID数: 1000
pigの画像ID数: 811
frogの画像ID数: 1000
豚の画像は1,000件に満たないようですが、まあ良しとしましょう。
このIDの情報を基にしてダウンロードを行います。実際のソースコードは以下の通りです。
# 画像をダウンロード
for label_name in labels.values():
logging.info(f"{label_name}の画像をダウンロードしています...")
try:
with open(f"/content/drive/MyDrive/open_images_v6/{label_name}_image_ids.txt", "r") as f:
image_ids = f.read().splitlines()
for image_id in tqdm(image_ids, desc=f"Downloading {label_name} images"):
result = subprocess.run(
[
"aws",
"s3",
"--no-sign-request",
"--region",
"ap-northeast-1",
"cp",
f"s3://open-images-dataset/train/{image_id}.jpg",
f"/content/drive/MyDrive/open_images_v6/{label_name}/",
],
capture_output=True,
text=True,
)
if result.returncode != 0:
logging.error(f"Failed to download {image_id}.jpg: {result.stderr}")
logging.info(f"{label_name}の画像のダウンロードが完了しました。")
except Exception as e:
logging.error(f"{label_name}の画像ダウンロードに失敗しました: {e}")
logging.info("全ての画像のダウンロード処理が完了しました。")
画像はカテゴリー名ごとのディレクトリに保存されています。(Pytorchのdatasets.ImageFolderを使用する際、ディレクトリ名がそのままクラス名として扱われるので便利です。)
分類器の作成
取得したデータを使用して、犬、猫、猿、豚、蛙の画像の分類器を作成します。
この件についてもCursorにどの手法が良いか相談したところ、学習済みのResNetを使い、転移学習で最後の層だけを学習させる方法が良いと提案されました。
ResNet(Residual Network)は、Kaiming Heらが2015年に提案したディープラーニングの深層畳み込みニューラルネットワークです。通常、ネットワークを深くすると勾配消失や過学習が起こりやすくなりますが、ResNetはスキップ接続(Residual connection)を導入することでこれを解決しています。スキップ接続では、各層の出力に元の入力を加えることで「残差」を学習し、非常に深い層でも効果的に学習が進む構造になっています。
ResNetは50層や100層を超える非常に深いネットワークでも優れた性能を発揮し、画像分類や物体検出などさまざまなタスクで使用されています。
(ChatGPTに「ResNetって何ですか?簡単にまとめてください」と質問した結果、上記の回答が得られました。)
特に今回は各カテゴリー1,000件と、非常に多いわけではないので、転移学習を使用した方が確かに効率的です。
今回は、ResNet18(18層のResNet)を使用することにしました。
では、早速、分類器を作成していきましょう。
分類器の作成もGoogle Colabで行いますが、まず前準備として、Google Driveに保存した画像データを動作中のマシンにコピーし、そこから読み込んでください。Google Driveからの読み込みが遅く、ボトルネックになる可能性があるためです。
圧縮したディレクトリをマシンにコピーして解凍すると、「.ipynb_checkpoints」というディレクトリが作成されることがあります。このディレクトリが存在すると、画像を読み込む際にサポートされていない拡張子としてエラーになる可能性があるため、削除しておいてください。
次に、グラフの文字化け対策として、以下のコマンドでライブラリをインストールしてください。このライブラリをインポートするだけで、matplotlibの日本語文字化けを防ぐことができます。
!pip install japanize-matplotlib
次に必要なライブラリをインポートします。
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import japanize_matplotlib
from sklearn.model_selection import KFold, train_test_split
from torch.utils.data import DataLoader, Subset
from torchvision import datasets, models, transforms
以下のソースでデバイスを設定してGPUを使用するようにします。
# デバイスの設定
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
torch.cuda.is_available()
次に、データの前処理のための変換器を定義します。詳しくは説明しませんが、訓練データに関しては、データ拡張のためにランダムに切り取り、ランダムに左右反転させ、ランダムに回転させて、色調を変化させた後、最後に正規化を行っています。テストデータの方は、リサイズし、中身を切り取り、正規化のみ行います。(それぞれの関数名から大体予想がつくかと思います。)
# データの前処理と拡張
train_transform = transforms.Compose(
[
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
test_transform = transforms.Compose(
[
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
次に、データを訓練データとテストデータに8:2の割合で分割します(実際の処理はデータを読み込む時に実行されます)。なお、分割したテストデータは訓練には使用せず、最終的に完成したモデルを評価する際に使用します。
# データセットの読み込みと訓練データとテストデータへの分割
full_dataset = datasets.ImageFolder("/content/open_images_v6/", transform=train_transform)
train_idx, test_idx = train_test_split(
list(range(len(full_dataset))), test_size=0.2, random_state=42
)
train_dataset = Subset(full_dataset, train_idx)
test_dataset = Subset(full_dataset, test_idx)
# テストデータセットにはテスト用の変換を適用する
test_dataset.dataset.transform = test_transform
次に、ResNet18モデルを読み込み、最終層(fc)を線形変換でクラス数(ここでは5)の出力に変更します。(最終層の名前が「fc」であることは、print(model)を実行すると各層の情報が表示されるため確認できます。)
# ResNet18モデルの読み込みんで最終層のみ学習する
def get_model(num_classes):
model = models.resnet18(weights=models.ResNet18_Weights.DEFAULT)
for param in model.parameters():
param.requires_grad = False
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, num_classes)
return model
次に前準備として学習曲線をプロットする関数を定義します。
# 学習曲線を可視化する関数
def plot_learning_curve(train_losses, val_losses, accuracies):
epochs = range(1, len(train_losses) + 1)
plt.figure(figsize=(12, 4))
# 損失のプロット
plt.subplot(1, 2, 1)
plt.plot(epochs, train_losses, "b-", label="訓練損失")
plt.plot(epochs, val_losses, "r-", label="検証損失")
plt.title("学習曲線 - 損失")
plt.xlabel("エポック")
plt.ylabel("損失")
plt.legend()
# 精度のプロット
plt.subplot(1, 2, 2)
plt.plot(epochs, accuracies, "g-", label="検証精度")
plt.title("学習曲線 - 精度")
plt.xlabel("エポック")
plt.ylabel("精度 (%)")
plt.legend()
plt.tight_layout()
plt.show()
次に、モデルを評価する関数を定義します。最初にmodel.eval()を実行し、その後、torch.no_grad()を使って評価モードで勾配が更新されないようにします。
#評価モード
def evaluate_model(model, data_loader, criterion):
model.eval()
total_correct = 0
total_loss = 0
total_samples = 0
with torch.no_grad():
for images, labels in data_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
_, predicted = torch.max(outputs, 1)
total_correct += (predicted == labels).sum().item()
total_loss += loss.item()
total_samples += labels.size(0)
accuracy = (total_correct / total_samples) * 100
average_loss = total_loss / len(data_loader)
return accuracy, average_loss
に、訓練用の関数を定義します。なお、エポックごとに評価を行うため、評価ロジックはこの関数内で呼び出します。(model.train()はエポックのループ内で実行していることに注意してください。)
# 訓練モード(学習中に損失と精度を記録する)
def train_model(model, train_loader, val_loader, criterion, optimizer, num_epochs):
train_losses = []
val_losses = []
accuracies = []
for epoch in range(num_epochs):
# トレーニングモードに設定
model.train()
running_loss = 0.0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
epoch_loss = running_loss / len(train_loader)
train_losses.append(epoch_loss)
# 検証データでの評価
accuracy, val_loss = evaluate_model(model, val_loader, criterion)
val_losses.append(val_loss)
accuracies.append(accuracy)
print(
f"Epoch [{epoch+1}/{num_epochs}], Train Loss: {epoch_loss:.4f}, Val Loss: {val_loss:.4f}, Accuracy: {accuracy:.2f}%"
)
return train_losses, val_losses, accuracies, accuracy # 最後の精度を返すこれらのコードの叩き台はCursorで出力したものですが、最初は上記の関数内でmodel.train()がループ外に書かれていました。やはり、コードを全く理解せずにソースを確認しないのは危険だと改めて感じました。
次に、ハイパーパラメータの候補を定義し、それぞれについて検証します。(本当はもっと多くの値で試した方が良いのですが、時間もお金もかかるため、今回はこの程度で…)
#ハイパーパラメータの設定
num_folds = 5
num_epochs = [10]
batch_sizes = [128, 256]
learning_rates = [0.001, 0.0001, 0.00001]
ここまで定義した関数を利用して、交差検証を実施します。最適化アルゴリズムにはAdamを使用し、分類問題なので損失関数には交差エントロピー誤差を採用します。
また、平均して最も精度が良かったハイパーパラメーターを保存しておきます。
# 交差検証
kfold = KFold(n_splits=num_folds, shuffle=True, random_state=42)
num_classes = len(full_dataset.classes)
best_params = {"accuracy": 0, "epochs": 0, "batch_size": 0, "lr": 0}
for epochs in num_epochs:
for batch_size in batch_sizes:
for lr in learning_rates:
print(f"Parameters: epochs={epochs}, batch_size={batch_size}, lr={lr}")
fold_accuracies = []
for fold, (train_ids, val_ids) in enumerate(kfold.split(train_dataset)):
print(f"FOLD {fold+1}")
print("--------------------------------")
train_subsampler = torch.utils.data.SubsetRandomSampler(train_ids)
val_subsampler = torch.utils.data.SubsetRandomSampler(val_ids)
train_loader = DataLoader(
train_dataset, batch_size=batch_size, sampler=train_subsampler,
num_workers = 4,pin_memory = True
)
val_loader = DataLoader(
train_dataset, batch_size=batch_size, sampler=val_subsampler,
num_workers = 4,pin_memory = True
)
model = get_model(num_classes).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.fc.parameters(), lr=lr)
train_losses, val_losses, accuracies, accuracy = train_model(
model, train_loader, val_loader, criterion, optimizer, epochs
)
plot_learning_curve(train_losses, val_losses, accuracies)
fold_accuracies.append(accuracy)
avg_accuracy = np.mean(fold_accuracies)
print(f"Average accuracy: {avg_accuracy:.2f}%")
if avg_accuracy > best_params["accuracy"]:
best_params["accuracy"] = avg_accuracy
best_params["epochs"] = epochs
best_params["batch_size"] = batch_size
best_params["lr"] = lr
実行結果は以下の通りで、学習曲線のグラフが各試行ごとに表示されます。(図は1施行だけ抜粋したものです。)
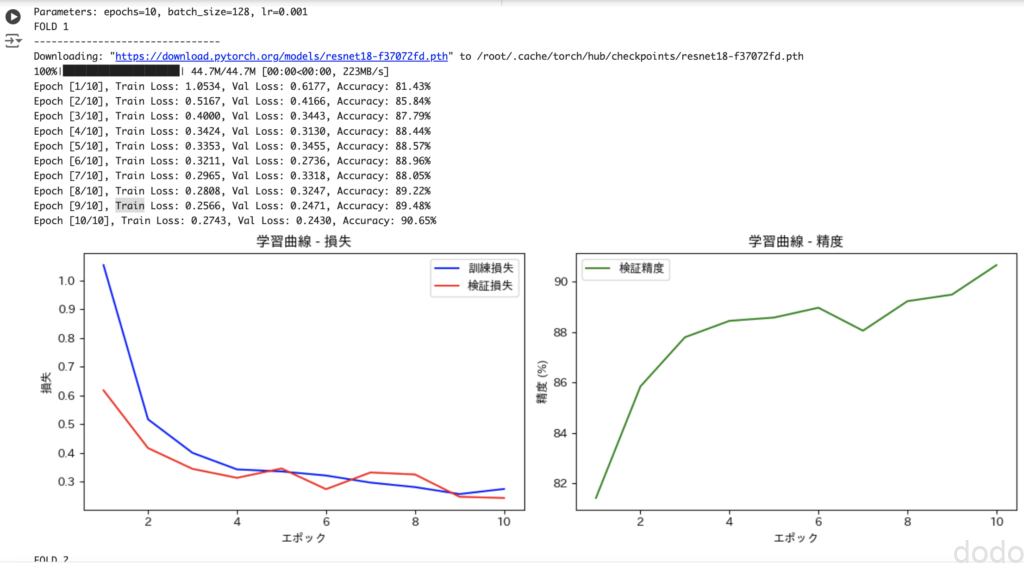 学習曲線
学習曲線それぞれのハイパーパラメータでの交差検証における各フォールドの平均精度は、以下の通りになりました。
Parameters: epochs=10, batch_size=128, lr=0.001 Average accuracy: 90.49%
Parameters: epochs=10, batch_size=128, lr=0.0001 Average accuracy: 83.81%
Parameters: epochs=10, batch_size=128, lr=1e-05 Average accuracy: 29.23%
Parameters: epochs=10, batch_size=256, lr=0.001 Average accuracy: 89.92%
Parameters: epochs=10, batch_size=256, lr=0.0001 Average accuracy: 73.18%
Parameters: epochs=10, batch_size=256, lr=1e-05 Average accuracy: 21.23%
最良のハイパーパラメータは以下となります。
Best parameters: Epochs: 10 Batch size: 128 Learning rate: 0.001
明らかに、バッチサイズが小さく、学習率が大きいほど精度が良いです。本来ならば、この結果からより小さいバッチサイズ、より大きい学習率で検証するべきですが、マシンのリソース(つまり私のお金)にも限りがあるため、今回はこれを最良のハイパーパラメータとします。
さらに精度の学習曲線を見ると収束もしていないように見えます。
本気で精度を求めるならば、以下の値で再度、交差検証を実施するべきでしょう。
Epochs:20 , Bach size=[64, 128], lr=[0.01, 0.001]
それでは、最終モデルを作成します。
最終モデルは、最良のハイパーパラメータで各フォールドのモデルをアンサンブルしたり、平均を取ったりして作成する方法もありますが、ここでは、最良のハイパーパラメータでテストデータを除いた全訓練データを使用して学習したモデルを最終モデルとします。(この方法が一般的かと思います。)
# 最終モデルの学習(全訓練データを使用)
print("全訓練データを使用して最終モデルを学習します...")
full_train_loader = DataLoader(
train_dataset, batch_size=best_params["batch_size"], shuffle=True,
num_workers = 4,pin_memory = True
)
# テストデータでの性能評価
test_loader = DataLoader(
test_dataset, batch_size=best_params["batch_size"], shuffle=False,
num_workers = 4,pin_memory = True
)
final_model = get_model(num_classes).to(device)
final_criterion = nn.CrossEntropyLoss()
final_optimizer = optim.Adam(final_model.fc.parameters(), lr=best_params["lr"])
train_losses, test_losses, test_accuracies, _ = train_model(
final_model,
full_train_loader,
test_loader, # テストデータを検証データとして使用
final_criterion,
final_optimizer,
best_params["epochs"],
)
以下のソースを実行し、最終モデルをテストデータで評価した結果を表示します。
plot_learning_curve(train_losses, test_losses, test_accuracies)
test_accuracy, test_loss = evaluate_model(final_model, test_loader, final_criterion)
print(f"最終テスト精度: {test_accuracies[-1]:.2f}%")
print(f"最終テスト損失: {test_losses[-1]:.4f}")
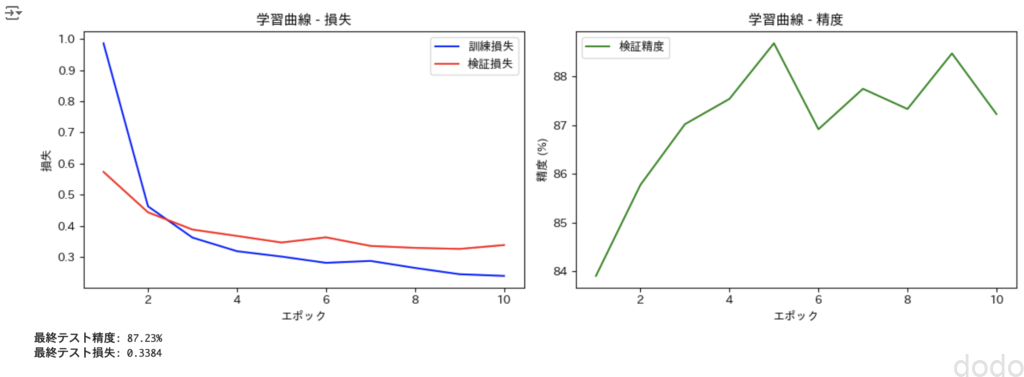 最終モデルの学習曲線
最終モデルの学習曲線
なんだか、精度の曲線がガタついていて少し嫌な感じですし、精度も87%とあまり良くはありませんが、今回はこのまま進めようと思います。
なお、テストデータでの最終的な検証結果を参考にして学習をやり直すのは、基本的にNGです。それを繰り返してテストデータの精度が良くなっても、テストデータを学習に使用していることと同じであり、汎化性能は向上しません。
最後に最終モデルを保存します。
# モデルの保存
torch.save(final_model.state_dict(), "/content/drive/MyDrive/open_images_v6/resnet18_transfer_learning_final.pth")
print("最終モデルが学習され、保存されました。")分類器の検証
では、保存したモデルを読み込んで使用してみましょう。(ここからは新たにNotebookを立ち上げた想定です。)
以下は前準備として、Google Driveへの接続、デバイスの設定、ResNet18モデルの取得を行います。(詳細は省略します。)
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from PIL import Image
from torchvision import datasets, models, transforms
#Google Driveへ接続
from google.colab import drive
drive.mount('/content/drive')
# デバイスの設定
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
torch.cuda.is_available()
# ResNet18モデルの読み込みんで最終層のみ置き換える
def get_model(num_classes):
model = models.resnet18(weights=models.ResNet18_Weights.DEFAULT)
for param in model.parameters():
param.requires_grad = False
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, num_classes)
return model
以下のソースを実行し、最終モデルの情報を読み込みます。
# モデルの取得
model = get_model(5)
# 保存したモデルの重みを読み込む
model.load_state_dict(torch.load("/content/drive/MyDrive/open_images_v6/resnet18_transfer_learning_final.pth"))
# モデルを評価モードに設定
model.eval()
# GPUが利用可能な場合は、モデルをGPUに移動
model = model.to(device)
以下のソースで、検証するデータの前処理を定義します。
# 画像の前処理
def preprocess_image(image_path):
test_transform = transforms.Compose(
[
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
image = Image.open(image_path).convert("RGB")
return test_transform(image).unsqueeze(0)
以下のソースで、予測関数を定義して、各クラスの確率を取得します。
# 予測関数
def predict(model, image_path, class_names):
model.eval()
image = preprocess_image(image_path).to(device)
with torch.no_grad():
outputs = model(image)
probabilities = torch.nn.functional.softmax(outputs[0], dim=0)
# クラスごとの確率を取得
class_probs = {class_names[i]: prob.item() for i, prob in enumerate(probabilities)}
return class_probs
さて、準備も整ったので、画像を用意したいのですが、ネットから取得した画像をここに載せて、万が一(「うちのワンちゃんの画像を勝手に使うな!」など)のトラブルが心配です。かといってフリー素材を探すのも面倒なので、ChatGPT(DALL-E3)を使って生成することにしました。とりあえず、各クラスごとに2つずつ生成したものが以下になります。
 AIで生成した動物画像
AIで生成した動物画像犬と猫が実写風なのに比べて、猿、蛙、豚はアニメチックです。そこで、「リアル風に」「実写風に」と指示したのですが、こんなことを言われて拒否されました。
I cannot generate real-life images of specific animals, including monkeys. However, if you’d like a different artistic representation of a monkey or any other animal, feel free to let me know!
特定の動物は実写風にはできないそうです。なぜ?
仕方がないので、アニメ風のままの画像を使用します。
以下のコードを実行して予測します。なお、Image_filesには画像のフルパスが格納された配列が設定されていますので、使用する際は、この変数を定義してファイルのフルパスを設定してください。(Image_filesを定義せずに実行するとエラーになります。)
# 予測の実行
predictions = []
for image_file in image_files:
print(image_file)
prediction = predict(model, image_file, class_names)
predictions.append(prediction)
以下のソースを実行して、結果を画像とセットで可視化します。
# 画像と予測確率を5列で表示
fig, axes = plt.subplots(nrows=2, ncols=5, figsize=(20, 20))
axes = axes.flatten()
for i, ax in enumerate(axes):
if i < len(image_files):
# 画像を読み込んで表示
img = Image.open(image_files[i])
ax.imshow(img)
ax.axis('off') # 軸を非表示にする
# 予測確率を取得し、小数点1桁、または指数表現でフォーマットする
text = ""
for class_name, prob in predictions[i].items():
formatted_prob = "{:.1e}".format(prob) if prob < 0.1 else "{:.1f}".format(prob)
text += f"{class_name}: {formatted_prob}\n"
# テキストを画像の下に表示
ax.text(0.5, -0.2, text, transform=ax.transAxes, fontsize=24, va='top', ha='center', linespacing=1.5)
plt.subplots_adjust(hspace=0.5)
plt.tight_layout()
plt.show()
結果は以下の通りです。(確率は0-1の範囲で表示)
 動物判定
動物判定10枚中、9枚的中していますね。豚は若干確率が低いですが、それでも正解しています。唯一外れた猿の2枚目(下段中央)は、蛙の確率60%、豚の確率20%です。蛙と判定されたのは、画像に緑が多いからと推測できます。また、豚と判定されたのは、丸っこい絵柄が影響しているのかもしれません。
では次に人間の画像で試します。人間の画像もChatGPTに出力させた画像を使用します。
 動物顔判定
動物顔判定
いや、微妙ですね(笑)
人の顔だと、割と均等な確率になる傾向があるようです。実際は犬でも猫でも猿でも豚でも蛙でもないので、均等な確率になるのは当然かもしれません。
その他の傾向としては、豚の確率が低いケースが多いこと、そして髭があると猿に判定されやすい気がします。(髭で猿は毛量的にわかるような気がします。)
まとめ
本記事では、機械学習を用いて動物顔判定のための分類器を作成しました。
なお、コードの作成にはCursorとChatGPTをフル活用しています。
それを踏まえた印象として、特に以下の点で非常に助かりました。
- オープンデータの取得
どのデータが良いかを1から相談できて、取得方法(取得するソースコード)まで提案してもらえました。 - Pytorchの大枠のコード出力
画像の読み込み、前処理、交差検証、最終テストまで、ほとんどそのまま使用できるコードを出力してくれました。 - データの可視化
Matplotlibを使ったグラフ作成など、自分で最初から書くと面倒な部分のコードも出力され、とても便利でした。
とは言っても、やはり最終的には自分でソースコードを理解してせずにコードを適用するのは問題があると思いました。
特に、機械学習のモデル作成はアプリとは異なり、挙動で不具合が分かるわけではないため、変な処理をしていても気づかない可能性があります。(上で述べたmodel.train()の実行タイミングが間違っていた件も、気づかなければそのままだったと思います。)
現状では、AIで出力したソースコードは、しっかりレビューした上で使うのが良いでしょう。(そのレビューすらもAIに任せるという時代になっていくかもしれませんが・・)
次回は、このモデルを使用してWebアプリを作成します。


