










以前、以下のような記事を書きました。

簡単に説明すると「AIは知らない事を聞いた時に嘘をつく(ハルシネーション:幻覚)のでプロンプトで質問と一緒に正確な知識を渡せばいいよね」という記事です。
この方法はRAG(Retrieval-Augmented Generation)というもので、AIが知らないような専門的な知識について回答させたい場合に、専門知識が記載されたドキュメントやWEBページの情報などをプロンプトに一緒に与えることによって、正確な情報を得る方法です。
ただ、この記事で使用したLlamaindexというフレームワークの仕様が変更されて現在のバージョンでは記事投稿時のソースが動作しません。(後、記事中の説明のための用語の使い方が微妙・・)
そのような理由から最新のバージョンでソースを書き直して再投稿しようと思った次第です。
ただソースコードを書き直しただけだと面白くないので(それだったら元記事を更新すれば良い・・)、今回はLlamaindexを使うケースと使わないケースの両方でRAGを行い比較するというテーマで記載します。
通常はRAGを実装する場合、LlamaiindexやLangChainなどのフレームワークを使用するケースがほとんどだと思いますが、フレームワークなしで実装すると「中で何をやっているか」を理解することができます。
なお題材としては元記事と同様に北条時行に関連する情報を用います。(理由はAIが微妙に知らなくてちょうどいいからです。)
北条時行、誰やねんという方はぜひこちらを。
Embedding、RAGの仕組み
Embedding、RAGについてさらっとおさらいしておきましょう。(知ってる方は飛ばしてください。)
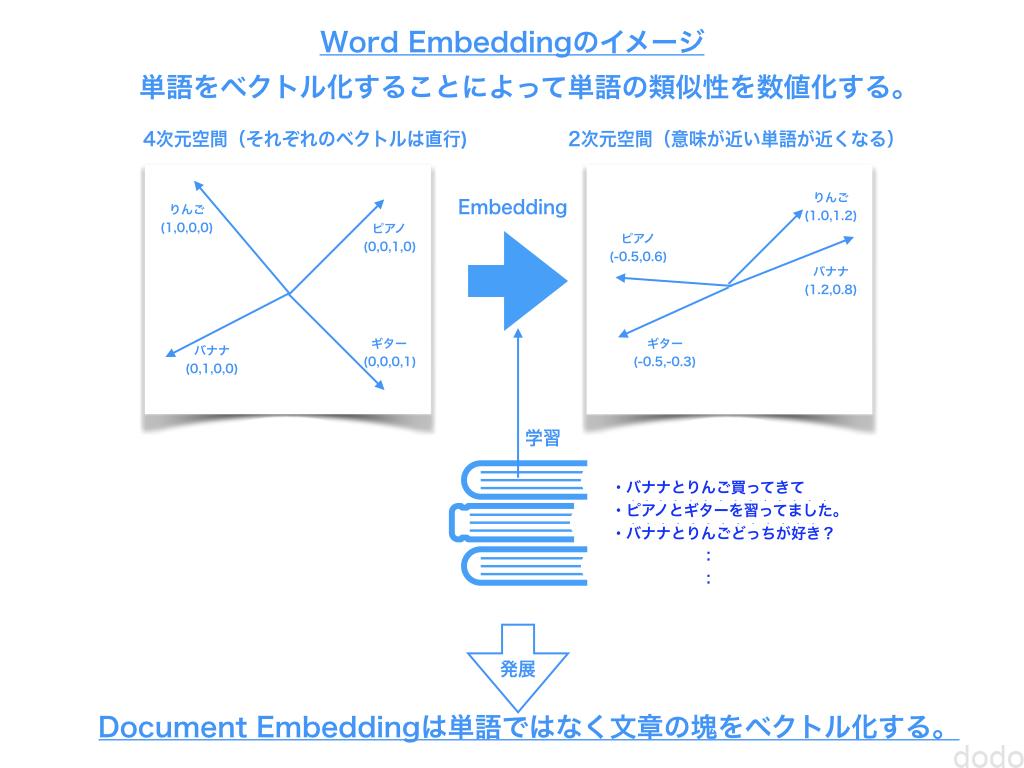
Embeddingは単語や文章などをベクトルに変換することです。
ベクトル化することにより、単語同士の意味の近さ、文章同士が意味の近さを数値化することができます。
 Embedding
Embedding
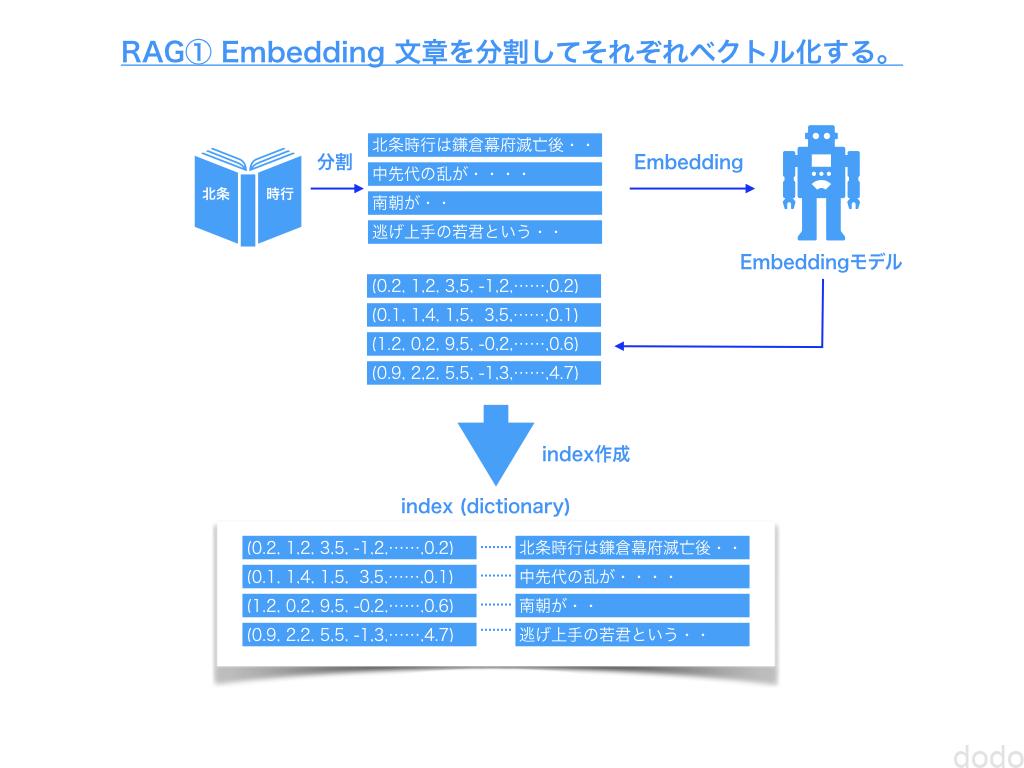
RAGはベクトル化された文章を利用することにより、質問と関連が高い文章を検索して質問と一緒にAIに問い合わせる事によって正確な情報を取得する手法です。
 ラグ① Embedding
ラグ① Embedding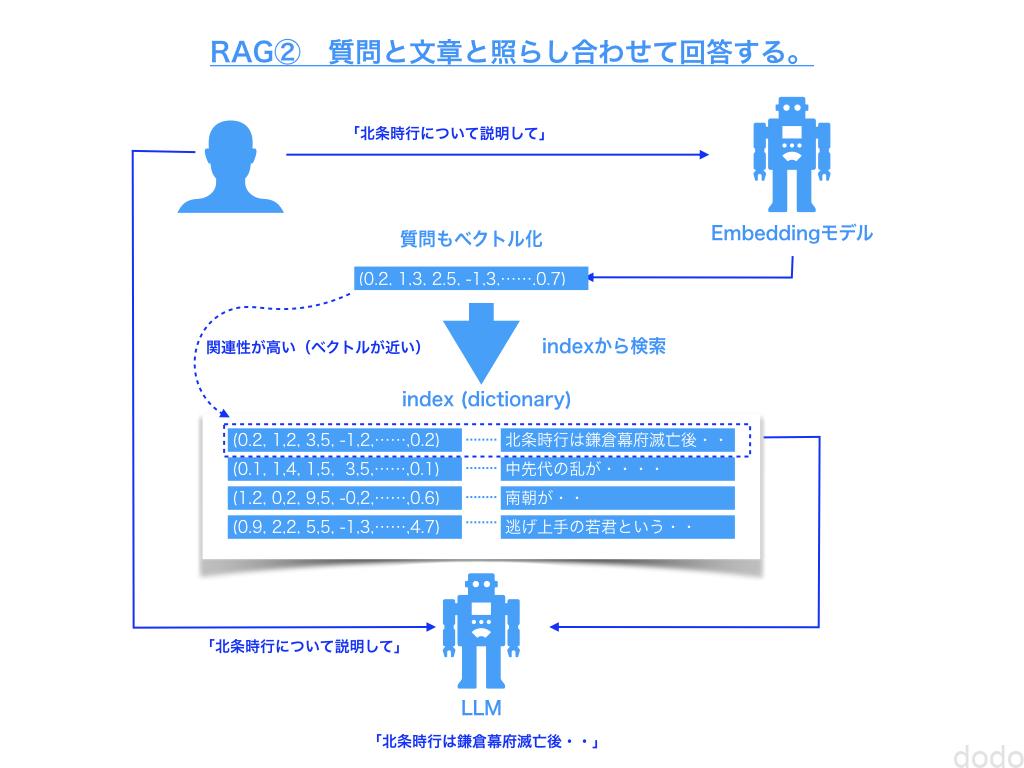 ラグ②検索と問い合わせ
ラグ②検索と問い合わせ
RAGはこのようにベクトルの類似性から検索するものに限定されません。
最近では、Graph RAGといったグラフデータベースを使用して検索するような手法も注目されています。
前提条件
RAGを使用したプログラミングについて説明する前に使用するライブラリのバージョンの確認とOpenAIのキー取得について確認します。
ライブラリ
本記事で使用するソースコードは、Python 3.10.3で起動するJupyter Lab上で実行されています。(Pythonのバージョンはもっと新しくても多分大丈夫)
また使用している各ライブラリのバージョンは以下の通りです。
- openai(1.44.1)
- Wikipedia-API (0.6.0)
- llama-index (0.11.8)
- llama-index-readers-wikipedia(0.2.0)
OpenAIのAPIキー取得
OpenAIのアカウントを作成した後、以下にアクセスして「Create new secret key」によりAPIキーを取得してください。
https://platform.openai.com/account/api-keys
Llamaindexを使用しないRAG
まずはLlamaindexを使用せずにOpenAIのAPIを直接使用してRAGを実装します。
Llamaindexを使用した方が簡単なのは明白なのですが、使用しない方が中で何をやっているかがわかりやすいので、一度はやってみて損はないと思います。
まずはOpenAIのインスタンスを生成します。
from openai import OpenAI
client = OpenAI(api_key=<取得したAPIキー>)
回答の比較のためにRAGを実装する前に通常の方法で問い合わせをします。先述した通りAIが微妙に詳しくなさそうな北条時行について質問します。
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "system",
"content": "あなたは歴史学者です。",
},
{"role": "user", "content": "北条時行についておしえてください。"},
],
)
message = completion.choices[0].message.content
print(message)
以下のような回答が返ってきました。
北条時行(ほうじょう ときゆき)は、鎌倉時代後期の武士であり、北条氏の一員として知られています。彼は北条氏の最後の当主である北条貞時の弟であり、特に南北朝時代における重要な人物です。時行は、後醍醐天皇の正統性を支持し、南朝側に付くことを選びました。 ### 主な経歴と業績 – **北条氏の出自**: 北条氏は鎌倉幕府を支えた有力な武士団であり、時行はその一員として生まれ育ちました。 – **南朝への支持**: 時行は南朝に仕官し、南朝の正統性を主張する武士として活動しました。彼の活動は、南北朝の対立が激化する中で重要な位置を占めました。 – **軍事行動**: 時行は特に関東地域における南朝の活動を支援し、北条一族の中では南朝方の武将としての立場を強く打ち出しました。 – **最期**: 時行は、南朝のために戦い続けましたが、最終的には捕えられ、1336年に亡くなったとされています。北条氏の衰退と共に、時行の名は南北朝の乱の歴史に刻まれることとなります。 北条時行は、政治的かつ軍事的な背景を持ちながらも、南朝への忠誠を貫いたことで、武士の中でも特異な存在となりました。彼の行動は、当時の武士や民衆に与えた影響や、その後の歴史においても重要な役割を果たしました。
わかる人にはわかると思いますが、70%くらい(もっと?)間違っています。(楠木正成混じってない?)
ポイントを絞って”北条時行と言えばこれ!”という北条時行が起こした乱について質問をします。
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "system",
"content": "あなたは歴史学者です。",
},
{"role": "user", "content": "北条時行が起こした乱について説明してください"},
],
)
message = completion.choices[0].message.content
print(message)
結果は以下のとおりです。完全に間違ってますね・・
北条時行が起こした乱は、「八王子乱(または北条時行の乱)」と呼ばれ、1331年から1333年にかけて発生しました。北条時行は、鎌倉幕府の北条氏の一族であり、彼の乱は幕府の滅亡に至る重要な出来事の一つとして位置づけられています。 背景には、鎌倉幕府の権威の低下と、南北朝の動乱がありました。北条時行は鎌倉幕府の後継者としての立場を持ち、反幕府勢力との対立を深めながら、幕府に対する反乱を決意しました。 1331年、彼は鎌倉で蜂起し、自らの権力を示す一方、幕府に対して不満を抱く武士や農民を支持に回させました。彼の指導下で起こったこの反乱は、最初は成功を収めたものの、次第に幕府の鎮圧軍に押され、次第に劣勢に追い込まれました。 最終的に北条時行の乱は1333年に鎮圧され、北条氏は滅亡に至ります。彼の乱は、鎌倉幕府の終焉を象徴する事件の一つであり、その結果、新たな政権である室町幕府が成立することになります。北条時行の乱は、武士の権力構造や政治の変遷において重要な位置を占める出来事となりました。
このように知ったかぶりをするAIにWikipediaの情報を与えて正しく答えてもらう事にします。(Wikipediaが正しいかどうかは、とりあえず置いておきます・・)
以下のようにしてWikipediaの北条時行のページからテキストを取得します。
from wikipediaapi import Wikipedia
wiki = Wikipedia('RAGBot/0.0', 'jp')
doc = wiki.page('北条時行').text
paragraphs = doc.split('\n\n')
paragraphsの中身がどうなっているか確かめてみます。
print(len(paragraphs))
for p in paragraphs:
print(f"{p[:30]}・・・・(略)・・・・")
結果は以下のとおりです。
24
北条 時行(ほうじょう ときゆき/ときつら)は、鎌倉時代末期・・・・(略)・・・・
生涯 誕生 鎌倉時代末期、鎌倉幕府の事実上の支配者北条氏の嫡・・・・(略)・・・・
鎌倉幕府滅亡 元徳3年(1331年)、鎌倉幕府と後醍醐天皇の・・・・(略)・・・・
建武の新政と北条与党の反乱 鎌倉幕府倒壊後に後醍醐天皇が開始・・・・(略)・・・・
時行挙兵、鎌倉奪還 建武2年(1335年)6月には、西園寺公・・・・(略)・・・・
「中先代」 当時の情報伝達速度からして、建武2年(1335年・・・・(略)・・・・
南朝への帰順 後醍醐天皇と足利尊氏の戦い建武の乱は尊氏が勝利・・・・(略)・・・・
復活と転戦、鎌倉再奪還 延元2年/建武4年(1337年)、南・・・・(略)・・・・
軍記物語『太平記』は、顕家が義貞に功を奪われることを嫌ったか・・・・(略)・・・・
三回目の鎌倉奪還 正平3年/貞和4年(1348年)ごろから、・・・・(略)・・・・
最期 逃走・潜伏を続けた時行だが、翌年の正平8年/文和2年5・・・・(略)・・・・
評価 鈴木由美によれば、「中先代」の「中」とは、「先代」(北・・・・(略)・・・・
中先代の乱の歴史的影響 通説における影響 時行が起こした中先・・・・(略)・・・・
新説における影響 一方で、21世紀初頭に進められている新説で・・・・(略)・・・・
伝承 愛刀 『太平記』流布本第32巻「直冬上洛の事附鬼丸鬼切・・・・(略)・・・・
伊勢潜伏説 『佐野本系図』が掲載する説の一つによると、時行は・・・・(略)・・・・
潜伏地 長野県の伊那地方(伊那谷・伊那市)には中先代の乱まで・・・・(略)・・・・
高遠町三義の御所平 高遠町藤澤御堂垣外の権殿屋敷かくれ久保 ・・・・(略)・・・・
大徳王寺城の戦い 諏訪大社上社の神長官を務めてきた守矢氏に伝・・・・(略)・・・・
子孫の伝承がある家系 『群書類従』第21輯合戦部所収の戦記物・・・・(略)・・・・
ギャラリー 関連作品 漫画 湯口聖子『夢語りシリーズ 明日菜・・・・(略)・・・・
脚注 注釈 出典 参考文献 池永二郎「中先代の乱」『国史大辞・・・・(略)・・・・
関連文献 鈴木由美 著「北条時行の名前について」、日本史史料・・・・(略)・・・・
外部リンク 狭雲月記念館 - 高遠彩華(日本史研究者の鈴木由・・・・(略)・・・
このように24個のテキストに分割されています。(これをチャンクと言います。)
OpenAIのtext-embedding-3-smallというモデルを使用してこのチャンクをベクトル化します。
#改行コード除去
paragraphs = [p.replace("\n", " ") for p in paragraphs]
#embedding
res = client.embeddings.create(input = paragraphs, model="text-embedding-3-small")
embed_paragraphes = [d.embedding for d in res.data]
embed_paragraphesはparagraphesと同様に24個の要素を持つリストです。類似性の計算に都合が良いようにnumpyの配列に変換しておきます。
import numpy as np
embed_paragraphes_array = np.array(embed_paragraphes)
embed_paragraphes_arrayは、(24, 1536)のnumpy配列となります。
この事から分割された24個のチャンクがそれぞれ1536の次元を持つベクトルに変換されている事がわかります。
チャンクと同様に質問もベクトル化します。
embed_query = client.embeddings.create(input = ["北条時行が起こした乱について説明してください"], model="text-embedding-3-small").data[0].embedding
embed_query_array = np.array(embed_query)embed_query_arrayは(1536,)のnumpy配列になっています。(ベクトルの要素の列がチャンクと異なる事に注意)
次に質問と24個のチャンクの類似性を見るためにベクトルの内積をとります。(質問のベクトルを転置しているのは、上に述べたように文書とベクトルの要素の列が逆のためです。)
similarities = np.dot(embed_paragraphes_array, embed_query_array.T)
similaritiesを表示すると以下のようになります。
array([0.47393809, 0.32064675, 0.39080332, 0.42725077, 0.37307871,
0.45315674, 0.41948118, 0.36169622, 0.40930311, 0.35433039,
0.40280222, 0.31510778, 0.4117568 , 0.34765271, 0.3740024 ,
0.37967955, 0.39060801, 0.22278015, 0.36327699, 0.40628638,
0.19262971, 0.39276862, 0.41532748, 0.46833512])
この数値が大きいものほど類似性が高い事になります。昇順でソートした時のインデックスを見てみましょう。
np.argsort(similarities, axis=0)
以下のような結果になり、20番目の値(0.19262971)が一番小さく、0番目の値(0.47393809)が一番大きいことがわかります。
array([20, 17, 11, 1, 13, 9, 7, 18, 4, 14, 15, 16, 2, 21, 10, 19, 8,
12, 22, 6, 3, 5, 23, 0])
なお、実際にAIに質問する時に類似性が低いチャンクまでも含めて送信するのは無駄ですし、サイズも大きくなるのでその分、料金も多くかかってしまいます。そこで類似性が高いTOP3のチャンクのみ送信するようにします。
以下のようにして質問と類似性が高いTOP3 のチャンクを取得します。
top_3_idx = np.argsort(similarities, axis=0)[-3:][::-1].tolist()
most_similar_paragraphs = [paragraphs[idx] for idx in top_3_idx]
ちょっとだけ中身を見てみましょう。
for p in most_similar_paragraphs:
print(f"{p[:40]}・・・・(略)・・・・")
結果は以下のとおりです。2番目のやつは類似性があるのか疑問ですが、まあいいでしょう・・
北条 時行(ほうじょう ときゆき/ときつら)は、鎌倉時代末期から南北朝時代の武将・・・・(略)・・・・
外部リンク 狭雲月記念館 - 高遠彩華(日本史研究者の鈴木由美)による北条時行フ・・・・(略)・・・・
「中先代」 当時の情報伝達速度からして、建武2年(1335年)7月22日に時行が・・・・(略)・・・・
得られたTOP3のチャンクをプロンプトに与えるために統合します。textwrap.fillしているのは適当な長さで改行を混ぜてわかりやすくするため、”—“で区切っているのもチャンクの区切りをわかりやすくするためです。
import textwrap
CONTEXT = ""
for p in most_similar_paragraphs:
wrapped_text = textwrap.fill(p, width=100)
print("-----------------------------------------------------------------")
print(wrapped_text)
print("-----------------------------------------------------------------")
CONTEXT += wrapped_text + "\n\n"
それではここまでの結果を使ってAIに質問をしてみましょう。質問は以下のようテンプレートにチャンクを入れ込みます。
query = "北条時行が起こした乱について説明してください"
prompt = f"""
コンテキスト: {CONTEXT}
質問: {query}
"""
この値を用いて以下を実行します。
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "system",
"content": """
あなたは歴史学者です。与えられたコンテキストの内容を使って質問に答えてください。
解答を知らない場合は、知らないと答えて、無理矢理、解答を作りださないでください。
""",
},
{"role": "user", "content": prompt},
],
)
message = completion.choices[0].message.content
print(message)
結果は以下の通りになりました。
北条時行が起こした乱は「中先代の乱」と呼ばれ、建武2年(1335年)に発生しました。時行は、鎌倉幕府の最後の得宗である北条高時の次男であり、北条氏の復興を目指して挙兵しました。彼は、鎌倉幕府の残党を集めて軍を編成し、挙兵からわずか1か月で5万騎に増強した後、足利直義を破って鎌倉を奪還しました。 しかし、時行の支配は短期間で、わずか20日後には足利尊氏に敗れ、鎌倉から追われることになります。この乱は、時行が北条氏と足利氏の間に位置する重要な存在であったことから、「中先代」と呼ばれ、武家の府である鎌倉の一時的な支配者となったことが特に注目されました。時行の軍事行動は、当時の政治状況を反映した重要な出来事とされています。
しっかりとwikpediaの情報を元に回答しています。
以下質問の内容を変えて何回か試してみました。(RAG有り無しで比較します。)
質問1:”北条時行の最期はどうなりましたか?”
・RAGなし
北条時行(ほうじょう ときゆき)は、南北朝時代の武将で、北条氏の一族です。彼は、北条氏の再興を目指して戦ったものの、元弘3年(1333年)に鎌倉幕府が滅亡した後、南朝方に仕官しました。 時行の最期に関する詳細には諸説ありますが、彼は相模の大山で戦い、後に捕らえられました。結局、時行は自害したとされています。彼の死は、北条氏の抗戦と抵抗の象徴として記憶されています。北条時行の最期は、南北朝時代の動乱を象徴するエピソードとして多くの文献に記述されています。
・RAGあり
北条時行は、正平8年/文和2年5月20日(1353年6月21日)に足利方に捕らえられ、鎌倉龍ノ口(神奈川県藤沢市龍口)で処刑されました。享年は20代半ばと推測されています。この時、彼と共に代々の得宗被官である長崎氏と工藤氏の武将も斬られました。彼の処刑は、鎌倉幕府滅亡からちょうど20年後の出来事でした。
質問2:”北条時行を主人公にした漫画の名前はなんですか?”
・RAGなし
北条時行を主人公にした漫画の名前は「山桜」です。この作品は、北条時行の生涯や彼を取り巻く歴史的背景を描いています。
・RAGあり
北条時行を主人公にした漫画の名前は『逃げ上手の若君』です。
質問3:”北条時行の性格はどうですか?”
・RAGなし
北条時行は、鎌倉時代末期の日本の武将であり、北条氏の一員として重要な役割を果たしました。彼の性格については、歴史的な記録や伝承からいくつかの特徴が見えてきます。 1. **忠誠心**: 時行は北条氏の家族の一員として、彼の一族や家を守るために尽力したとされています。祖父や父の時代から受け継がれた忠誠心を持っていたと言えるでしょう。 2. **勇敢さ**: 時行は戦いにおいて果敢であったとされています。彼は多くの戦闘に参加し、戦術にも秀でていたと考えられます。 3. **冷静さと判断力**: 歴史的な文脈から、彼は厳しい状況において冷静に判断を下す能力を持っていたとも伝えられています。特に、鎌倉幕府の崩壊の中で状況を見極めることが求められました。 4. **理想主義的な側面**: 時行は、旧来の秩序の復興を目指すなど、理想を持って行動した面があります。彼は、北条氏の復興を志し、政権の再建を試みるなど、理想主義的な一面を持っていたとされています。 これらの特徴から、北条時行は、信義に厚く、戦略的かつ理想を追求する人物であったと言えるでしょう。しかし、彼の性格や行動については、異なる解釈も可能であり、時代や観点によって捉え方が変わることも考慮する必要があります。
・RAGあり
コンテキストには北条時行の性格に関する具体的な情報は含まれていないため、性格についてはわかりません。
質問4:”徳川家康について教えてください”
・RAGなし
徳川家康(とくがわ いえやす、1543年 – 1616年)は、日本の戦国時代から江戸時代初期にかけての重要な政治家であり、武将です。彼は徳川幕府の初代将軍として知られており、日本の歴史において非常に大きな影響を持った人物です。 ### 生涯 – **出自と若年期**: 徳川家康は、三河国(現在の愛知県)にある岡崎城の城主である松平広忠の子として生まれました。少年期は、今川氏に人質として送られ、後に縁を結びつつ、家康自身の勢力を確立していきました。 – **戦国時代の活動**: 家康は織田信長と同盟を結び、彼の死後は豊臣秀吉と協力しながら、戦国時代の混乱を乗り越えていきました。彼自身も多くの戦闘を経験し、特に関ヶ原の戦い(1600年)での勝利が、彼の権力を確立する大きな要因となりました。 ### 徳川幕府の成立 – **江戸幕府の創設**: 家康は1603年に征夷大将軍に任命され、江戸幕府を樹立しました。これにより、彼は日本の中央集権的政治体制を確立し、長期にわたる平和な時代(江戸時代)へと導きました。 – **政策と統治**: 家康は、商業の発展、農業の奢華化、国際的な交流の促進などを推進し、地方の大名に対しても厳しい統制を行いました。また、彼の統治下で、社会秩序の確立や武士の身分制度の整備が進められました。 ### 死後の影響 – **文化の発展**: 家康の政策は、江戸時代文化の発展にも寄与しました。商業や経済の発展は、町人文化や浮世絵、歌舞伎などの独自の文化を生み出す基盤となりました。 – **神格化と後世の評価**: 家康は1616年に死去した後、彼を祀る東照宮が建設され、神として崇拝されるようになりました。彼の治世やビジョンは、日本の歴史において高く評価されており、歴史学や文化での影響は今なお続いています。 徳川家康は、戦国時代の動乱を経て平和な時代を築き上げた重要な指導者であり、その業績は日本史において伝説的なものとなっています。
・RAGあり
知らない。
RAGを使用した場合、Wikipediaの情報から取得している事に加えて、質問3のような曖昧な質問や質問4のような北条時行と関係ない質問には回答しないようになっており、ハルシネーションを回避できています。
それにしても「知らなかったら知らないと答えてください」と書いたら本当に「知らない」と一言で返ってきましたね。。(ちなみにもう一度やったらちゃんとした文章で返ってきました。)
Llamaindexを使用したRAG
Llamainndexを使用しなくてもここまでできれば、Llamaindexいらないのでは?と思ってもきましたが(しょっちゅう仕様変えるし・・)、比較が目的なので、Llamaindexを使用したバージョンについても説明します。
まずは取得したOpenAIのキーを環境変数に設定します。
import os
os.environ["OPENAI_API_KEY"] = <取得したAPIキー>
必要なライブラリをインポートします。
from llama_index.core import Settings, VectorStoreIndex
from llama_index.readers.wikipedia import WikipediaReader
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
公式ページ的には後5行あれば実装できるのですが、Llamaindexの良いところでもあり悪いところでもあるのがデフォルトの設定が多い事です。
これにより書くコードが少なくて済むのですが、その一方、わかってないと何をされているのかわからないのが難点です。
一番の問題はデフォルトのモデルが設定されているのでモデルの指定を明示的にしなくて実行できてしまう事だと思います。料金とか気にして少しでも安いモデルを使いたい場合、どのモデルが使用されているかわからないのは困ります。
デフォルトの設定を見るため以下を実行します。
print(Settings.llm.model)
print(Settings.embed_model.model_name)
実行結果は以下のとおりです。
gpt-3.5-turbo
text-embedding-ada-002
LLMのモデルもembeddingのモデルも最新でもなければ最安でもないので、変更する必要があります。Llamaindexを使用しない場合で使用したモデルをこちらでも使用するように変更します。
Settings.llm = OpenAI(model="gpt-4o-mini", temperature=0.1)
Settings.embed_model = OpenAIEmbedding(
model="text-embedding-3-small", embed_batch_size=100
)
もう一度、以下を実行します。
print(Settings.llm.model)
print(Settings.embed_model.model_name)
実行結果は以下となります。
gpt-4o-mini
text-embedding-3-small
次にWikipediaからの情報を取得してベクトル化してindexを作成します。
documents = WikipediaReader().load_data(["北条時行"],"ja")
index = VectorStoreIndex.from_documents(documents)
indexの中身を少し見てみましょう。
ベクトル部分を表示します。
for k, v in index.vector_store.data.embedding_dict.items():
print(f"{k[:10]=}, {len(v)=}, {v[:3]=}")
出力結果は以下のとおりです。
k[:10]='53618428-9', len(v)=1536, v[:3]=[0.023346971720457077, 0.020886287093162537, 0.008597631007432938]
k[:10]='e19cdab2-2', len(v)=1536, v[:3]=[0.01889823190867901, 0.005400231573730707, -0.013152426108717918]
k[:10]='b9756903-e', len(v)=1536, v[:3]=[0.0035904713440686464, 0.040434375405311584, 0.03119705058634281]
k[:10]='176a8b4d-0', len(v)=1536, v[:3]=[0.003302998375147581, 0.013072814792394638, 0.025867274031043053]
k[:10]='ea541198-9', len(v)=1536, v[:3]=[0.01402261946350336, 0.005798937287181616, 0.017791198566555977]
k[:10]='2211ff58-9', len(v)=1536, v[:3]=[0.010174387134611607, -0.01822754740715027, 0.027106670662760735]
k[:10]='90257129-c', len(v)=1536, v[:3]=[0.030356893315911293, -0.005078574642539024, 0.01824277453124523]
k[:10]='8d10bfd3-0', len(v)=1536, v[:3]=[0.01564165949821472, -0.003360243048518896, 0.025875352323055267]
k[:10]='ff01117e-c', len(v)=1536, v[:3]=[0.011453047394752502, -0.014714384451508522, -0.026474380865693092]
k[:10]='aacc3d13-9', len(v)=1536, v[:3]=[0.04107632860541344, 0.03803081810474396, 0.03275827690958977]
k[:10]='16cfa81f-b', len(v)=1536, v[:3]=[0.007781653665006161, 0.0275775995105505, 0.019684432074427605]
k[:10]='f99cf111-3', len(v)=1536, v[:3]=[-0.0038617446552962065, 0.0024793592747300863, 0.015655454248189926]
k[:10]='00c232d7-4', len(v)=1536, v[:3]=[0.019218815490603447, 0.03492388874292374, 0.03649633750319481]
k[:10]='f462bbba-b', len(v)=1536, v[:3]=[0.0310541782528162, 0.02060198038816452, 0.0034517766907811165]
k[:10]='d1619c10-c', len(v)=1536, v[:3]=[-0.009615539573132992, -0.015730753540992737, 0.029141763225197792]
k[:10]='6bae7f1f-d', len(v)=1536, v[:3]=[0.00697731226682663, 0.011263780295848846, 0.018061703070998192]
k[:10]='7e5c5e06-8', len(v)=1536, v[:3]=[0.0423387847840786, -0.002010618569329381, -0.005637100897729397]
k[:10]='74c638d0-c', len(v)=1536, v[:3]=[0.03915424272418022, 0.007660382892936468, 0.006940402090549469]
k[:10]='ab619650-0', len(v)=1536, v[:3]=[0.028773272410035133, 0.030641667544841766, -0.0029505060520023108]
k[:10]='fdf21814-a', len(v)=1536, v[:3]=[-0.014067783951759338, 0.04042717069387436, 0.012411468662321568]
k[:10]='1a496b6c-e', len(v)=1536, v[:3]=[0.01019256841391325, 0.035629503428936005, 0.001435955986380577]
k[:10]='20495b8d-3', len(v)=1536, v[:3]=[0.013838340528309345, 0.0318191796541214, -0.029237622395157814]
k[:10]='cbc421b5-e', len(v)=1536, v[:3]=[-0.0063645136542618275, 0.022305691614747047, -0.009484266862273216]
k[:10]='768ac038-6', len(v)=1536, v[:3]=[0.001278204726986587, 0.007388243917375803, -0.011217349208891392]
k[:10]='b7ef0eb6-9', len(v)=1536, v[:3]=[0.0196288600564003, 0.010945498943328857, -0.0038015067111700773]
テキスト部分を表示します。
for k, v in index.docstore.docs.items():
print(f"{k[:10]=}, {len(v.text)=}, {v.text[:30]=}")
出力結果は以下のとおりです。
k[:10]='53618428-9', len(v.text)=623, v.text[:30]='北条 時行(ほうじょう ときゆき/ときつら)は、鎌倉時代末期'
k[:10]='e19cdab2-2', len(v.text)=459, v.text[:30]='== 生涯 ==\n\n\n=== 誕生 ===\n鎌倉時代末期、鎌'
k[:10]='b9756903-e', len(v.text)=425, v.text[:30]='=== 鎌倉幕府滅亡 ===\n\n元徳3年(1331年)、鎌倉'
k[:10]='176a8b4d-0', len(v.text)=864, v.text[:30]='=== 建武の新政と北条与党の反乱 ===\n鎌倉幕府倒壊後に'
k[:10]='ea541198-9', len(v.text)=779, v.text[:30]='日本史研究者の鈴木由美によれば、『太平記』のこの物語を直接支'
k[:10]='2211ff58-9', len(v.text)=501, v.text[:30]='7月25日、時行は鎌倉に入り、武家にとっての旧都の奪還を成功'
k[:10]='90257129-c', len(v.text)=880, v.text[:30]='したがって、亀田の推測によれば、直義が護良を殺害したのは、単'
k[:10]='8d10bfd3-0', len(v.text)=799, v.text[:30]='=== 南朝への帰順 ===\n後醍醐天皇と足利尊氏の戦い建武'
k[:10]='ff01117e-c', len(v.text)=786, v.text[:30]='その一方で、足利尊氏が今の地位にあるのは鎌倉時代に北条氏が恩'
k[:10]='aacc3d13-9', len(v.text)=838, v.text[:30]='なお、時行はこの後、得宗家と父の高時を直接滅ぼした武将である'
k[:10]='16cfa81f-b', len(v.text)=828, v.text[:30]='翌延元3年/建武5年(1338年)1月2日、顕家らは京の奪還'
k[:10]='f99cf111-3', len(v.text)=814, v.text[:30]='一方、岡野は、時行が義貞を恨んでいたとする佐藤進一説は支持し'
k[:10]='00c232d7-4', len(v.text)=678, v.text[:30]='しかし正平7年(1352年)初頭、准大臣・歴史家の北畠親房を'
k[:10]='f462bbba-b', len(v.text)=523, v.text[:30]='その後、時行がいつまで義興と同じ軍に加わっていたかは不明であ'
k[:10]='d1619c10-c', len(v.text)=481, v.text[:30]='== 評価 ==\n鈴木由美によれば、「中先代」の「中」とは、'
k[:10]='6bae7f1f-d', len(v.text)=725, v.text[:30]='=== 中先代の乱の歴史的影響 ===\n\n\n==== 通説に'
k[:10]='7e5c5e06-8', len(v.text)=707, v.text[:30]='==== 新説における影響 ====\n一方で、21世紀初頭に'
k[:10]='74c638d0-c', len(v.text)=787, v.text[:30]='しかし、珣子に生まれたのは皇位を継ぐことができない皇女だった'
k[:10]='ab619650-0', len(v.text)=852, v.text[:30]='同書によれば、鬼丸はもともと鎌倉幕府初代執権北条時政の伝説に'
k[:10]='fdf21814-a', len(v.text)=607, v.text[:30]='なお、元弘の乱では、高時の長男(時行の兄)の邦時は、義貞の配'
k[:10]='1a496b6c-e', len(v.text)=760, v.text[:30]='=== 潜伏地 ===\n長野県の伊那地方(伊那谷・伊那市)に'
k[:10]='20495b8d-3', len(v.text)=880, v.text[:30]='=== 子孫の伝承がある家系 ===\n『群書類従』第21輯合'
k[:10]='cbc421b5-e', len(v.text)=961, v.text[:30]='== 脚注 ==\n\n\n=== 注釈 ===\n\n\n=== 出典'
k[:10]='768ac038-6', len(v.text)=981, v.text[:30]='呉座勇一 編『南朝研究の最前線 : ここまでわかった「建武政'
k[:10]='b7ef0eb6-9', len(v.text)=356, v.text[:30]='呉座勇一 編『南朝研究の最前線 : ここまでわかった「建武政'
以上からベクトルと対応するチャンクがキーの値によって紐づけられているのがわかります。
なお以下を実行するとわかるのですが、デフォルトではchunk_size=1024,chunk_overlap=200となっており、1024以下のサイズでチャンクを区切る事と、中途半端に区切られた時に文脈が損なわれないように200文字ほどオーバーラップするようになっています。(これも設定で変えられます。)
print(Settings.text_splitter.chunk_size)
print(Settings.text_splitter.chunk_overlap)
indexから質問するためのクエリーエンジンのインスタンスを生成します。(こちらも色々とオプションがありますが今回は省略)
query_engine = index.as_query_engine()
ここまで来れば質問を投げるだけです。まずは定番の質問をします。
response = query_engine.query("北条時行が起こした乱について説明してください")
print(response)
ちゃんとWikipediaの情報に基づいて説明されています。
北条時行が起こした乱は「中先代の乱」と呼ばれ、建武2年(1335年)に発生しました。この乱は、北条氏の復興を目指して、鎌倉幕府の残党を集結させた結果、時行が鎌倉街道を進撃し、足利直義を破って鎌倉を奪還することに成功したものです。彼の軍勢は5万騎に達し、挙兵からわずか1か月での勝利を収めましたが、その後、足利尊氏に追われ、わずか20日で鎌倉を失いました。この乱は、南北朝時代の内乱の一環として位置づけられています。
さらにLlamaindexなしの場合と同じ質問をしてみましょう。
response = query_engine.query("北条時行の最期はどうなりましたか?")
print(response)北条時行は、逃走・潜伏を続けた後、正平8年/文和2年5月20日(1353年6月21日)に足利方に捕らえられ、鎌倉龍ノ口で処刑されました。享年は20代半ばと推測されています。この時、彼と共に長崎駿河四郎と工藤二郎も斬られました。
response = query_engine.query("北条時行を主人公にした漫画の名前はなんですか?")
print(response)逃げ上手の若君』です。
response = query_engine.query("北条時行の性格はどうですか?")
print(response)北条時行の性格について具体的な記述はありませんが、彼の行動や戦歴からは、復興を目指す強い意志やリーダーシップ、戦略的な思考が伺えます。また、南朝方の武将として戦ったことから、忠誠心や義理を重んじる性格もあったと考えられます。彼の戦いの中での成功と失敗は、彼の性格や決断力に影響を与えた可能性があります。
response = query_engine.query("徳川家康について教えてください")
print(response)徳川家康に関する情報は提供されていません。質問があれば、他のテーマについてお答えできますので、お知らせください。
大体、良い感じですが、3つ目の北条時行の性格に関してだけ憶測が返ってきました。
これに関してはプロンプトで「知らないことは知らないと答えてください」と言わないとだめかもしれません。以下のように変更して再度問い合わせると憶測をしない回答が返されました。
response = query_engine.query("北条時行の性格はどうですか?与えられた情報にない場合は憶測で回答しないでください")
print(response)与えられた情報には、北条時行の性格に関する具体的な記述は含まれていません。そのため、性格についての詳細は提供できません。
ところで、あまりにもあっさり行くので忘れそうになっていましたが、以下の2点がブラックボックスです。
- 類似性が高いチャンクの何番目まで(top-k)をプロンプトに追加しているのか
- 実際のプロンプトのテキストはどうなっているのか
以下のようにログを出力すればわかるようなので以下を実行します。(Tracing and Debugging(公式)参照)
import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
再度、以下を実行するとログが出力されます。
response = query_engine.query("北条時行が起こした乱について説明してください")
print(response)
ログの内容は以下のようになっています。(冒頭のみ抜粋)
DEBUG:openai._base_client:Request options: {'method': 'post', 'url': '/embeddings', 'files': None, 'post_parser': <function Embeddings.create.<locals>.parser at 0x11f93e3b0>, 'json_data': {'input': ['北条時行が起こした乱はなんですか?'], 'model': 'text-embedding-3-small', 'encoding_format': 'base64'}}
Request options: {'method': 'post', 'url': '/embeddings', 'files': None, 'post_parser': <function Embeddings.create.<locals>.parser at 0x11f93e3b0>, 'json_data': {'input': ['北条時行が起こした乱はなんですか?'], 'model': 'text-embedding-3-small', 'encoding_format': 'base64'}}
DEBUG:openai._base_client:Sending HTTP Request: POST https://api.openai.com/v1/embeddings
Sending HTTP Request: POST https://api.openai.com/v1/embeddings
(後略)
ログを追っていくと知りたかった情報が見つかりました。
まずは類似性の高いTOP2のチャンクを付与していることがわかります。(※後半は省略しました)
DEBUG:llama_index.core.indices.utils:> Top 2 nodes:
> [Node 53618428-9e92-4314-ac32-bd04c59789b6] [Similarity score:0.482948] 北条 時行(ほうじょう ときゆき/ときつら)は、鎌倉時代末期から ・・・・・
> [Node 90257129-c132-418d-9600-fee6e85b0fad] [Similarity score:0.457244] したがって、亀田の推測によれば、直義が護良を殺害したのは、・・・・・
次に実際のプロンプトは以下のようになっていることがわかります。(改行コード部分は改行してコンテキストの後半は省略しました。)
{'role': 'system', 'content': "You are an expert Q&A system that is trusted around the world.
Always answer the query using the provided context information, and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like 'Based on the context, ...' or 'The context information ...' or anything along those lines."},
{'role': 'user', 'content': 'Context information is below.
---------------------
北条 時行(ほうじょう ときゆき/ときつら)は、鎌倉時代末期から ・・・・・・
したがって、亀田の推測によれば、直義が護良を殺害したのは、・・・・・
---------------------
Given the context information and not prior knowledge, answer the query.
Query: 北条時行が起こした乱はなんですか?
Answer: '}
これらについて「知らなくてもできる」と言えば聞こえはいいかもしれませんが、さすがにブラックボックスすぎるかと・・
なお、当然これらはカスタマイズできます。以下の部分を・・
query_engine = index.as_query_engine()
response = query_engine.query("北条時行が起こした乱はなんですか?")
print(response)
以下のように変更すれば、類似性の高いTOP3を取得、カスタマイズしたプロンプトも変更できます。(まあ、カスタマイズすればそれなりにコード量は増えるということで・・)
詳細な説明、結果は省略しますので興味ある方は確かめてください。(一応、動作確認はしてますが、回答結果は大きく変わらないので・・)
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.llms import ChatMessage, MessageRole
from llama_index.core.prompts import ChatPromptTemplate
# top_kを3に設定
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=3,
)
# query_engine生成
query_engine = RetrieverQueryEngine(retriever=retriever)
# System prompt
system_prompt_content = """あなたは歴史学者です。与えられたコンテキストの内容を使って質問に答えてください。
解答を知らない場合は、知らないと答えて、無理矢理、解答を作りださないでください。"""
# User prompt
user_prompt_content = """コンテキスト: {context_str}
質問: {query_str}"""
# message
msgs = [
ChatMessage(
role=MessageRole.SYSTEM,
content=system_prompt_content,
),
ChatMessage(role=MessageRole.USER, content=user_prompt_content),
]
#prompt template更新
text_qa_template = ChatPromptTemplate(msgs)
query_engine.update_prompts({"response_synthesizer:text_qa_template": text_qa_template})
response = query_engine.query("北条時行が起こした乱はなんですか?")
print(response)
まとめ
以上、RAGについてLlamaindexを使用しない場合と使用した場合を比較して検証しました。
RAGというとフレームワーク必須のようなイメージもありますが、Llamaindexを使わなくても一度コードを書いて関数化してしまえば、それほど大変なコードを書かなくても実装できることがわかりました。
それでもLlamaindexのようなフレームワークを使う理由は、以下のようなものかと思います。
- それでもやはりコード量が少ない。
- 細かいロジックを理解していなくても実装できる。
- LLMの差をAPIで吸収できる。
- APIの詳細な使用を理解すれば様々なデータストア、インデックスに対応したRAGを実装できる。
ただし①②に関しては諸刃の剣で、逆にいうとデフォルトの設定で裏でやってることが多くて「何やってるかよくわからないけど上手く行ってる」みたいな感覚になります。特に個人的な感想としてはモデルのデフォルト指定はやめた方が良いのではないかと思います。(性能のみならず料金にも大きく関わってくるので・・)
また性能が出ている場合は問題はないのかもしれませんが、いざチューニングしたい場合はやはりちゃんと理解しないといけなく、⑤にあるように低レベルのAPIも用意されていルノで、それを使いこなす必要があります。
そして、これは現時点のみの問題かもしれませんが、APIの仕様がドラスティックに変わってるため、ググっても以前のバージョンのコードばかりヒットします。なので公式のドキュメントしか頼れるものがありませんが、それもわかりにくい・・上でテンプレートを置き換えるのにどれだけ調べたか・・・
なお、テンプレートの置き換えに関しては以下のサイトを参考にさせていただきました。(https://zenn.dev/kun432/scraps/20372f51bb016d)
結論としては、おそらく業務ではLlamaindexのようなフレームワークを使用することにはなると思いますが「デフォルトの設定には注意、そして使いこなすならば、低レベルのAPIについてもちゃんと理解せよ」といったところでしょうか。
なお、Llamaindexを使用しないRAGのコーディングについては以下のPrompt Engineeringというチャンネルの動画を参考にさせていただきました。英語がわからなくてもなんとなくわかるので興味がある方はご視聴ください。


