最近は流行りのLLM(大規模言語モデル)を使って色々遊んでおり、本サイトの記事もそれに関連したものばかりになってしまいました。
しかし、あくまでも「遊び」なので、ネタにしかなりません。
OpenAIを使ったビジネスに結びつけるにはどうすれば良いか?
・・と考える中でブログの記事のタイトルをAIに考えてもらうということをふと思いつきました。
例えば、本記事のタイトルをChatGPTに考えてもらいました。
 ChatGPTにこのブログのタイトルを考えてもらった。
ChatGPTにこのブログのタイトルを考えてもらった。2回目に聞いた二番目のタイトルが良さげだったので、それを少し修正して本記事のタイトルにしました。
それでは、今まで作成した記事のタイトルを修正したい場合はどうすれば良いでしょうか?
一つ一つの記事について上のような問い合わせをしていたら時間がかかってしまいます。
そこで既存の記事の内容からタイトルをつける方法を考えました。
事前準備
前提条件
本記事で掲載するソースコードは、Python3.10.3で記述されております。
使用している各ライブラリのバージョンは以下の通りです。
- openai (0.27.2)
- python-dotenv(1.0.0)
- numpy(1.24.3)
- requests(2.29.0)
- python-dotenv(1.0.0)
- sumy(0.11.0)
- beautifulsoup4(4.12.2)
- sumy(0.11.0)
OpenAIのAPIキー取得
OpenAIのアカウントを作成した後、以下にアクセスして「Create new secret key」によりAPIキーを取得してください。
https://platform.openai.com/account/api-keys
アカウント作成後$18以内かつ3ヶ月以内は無料ですがそれ以上は料金が発生します(2023/4/1現在)。詳細は、OpenAIのページを参照してください。
なお、有料課金した段階で無料利用の$18も支払い対象となるようなので注意が必要です。
実装
記事のタイトルと本文の一覧を取得する。
まずは対象のサイトの記事のタイトルと本文を取得してCSVファイルに保存します。
スクレイピングにはrequestsとbeatifulsoup4を使用します。
ソースコードは以下のようになります。
import re
import csv
import requests
from bs4 import BeautifulSoup
def get_aarticle_urls(blog_url):
# 記事URLを保存する空のリストを初期化する
article_urls = []
# サイトの各ページをループし、記事URLを抽出する
page_number = 1
while True:
page_url = blog_url + "/page/" + str(page_number) + "/"
# 現在のページURLにGETリクエストを送信する
response = requests.get(page_url)
# レスポンスステータスコードが200でない場合はループから抜ける
if response.status_code != 200:
break
# 現在のページのHTMLコンテンツを解析する
soup = BeautifulSoup(response.content, "html.parser")
# 現在のページのすべての記事要素を見つける
articles = soup.find_all("article")
# 各記事のURLを取得し、記事URLリストに追加する
article_urls += [article.find("a")["href"] for article in articles]
# 次のイテレーションのためにページ番号をインクリメントする
page_number += 1
return article_urls
def save_article_data(article_urls):
# 記事データを保存するリストを初期化する
articles_data = []
# 各記事URLをループし、タイトルと内容を抽出する
for article_url in article_urls:
# 記事URLにGETリクエストを送信する
response = requests.get(article_url)
# 記事ページのHTMLコンテンツを解析する
soup = BeautifulSoup(response.content, "html.parser")
# 記事のタイトルを取得する
title = soup.find("h1").text.strip()
content = soup.find("div", class_="entry-content")
if content:
# コードブロックを削除する
for code_block in content.find_all("pre"):
code_block.decompose()
# 不要なタグや属性を削除する
for tag in content.find_all(["style", "script", "iframe", "img"]):
tag.decompose()
for tag in content.find_all(True):
tag.attrs = {}
# 過剰な空白文字や改行を削除する
content = re.sub(r"\s+", " ", content.text.strip())
content = re.sub(r"\n+", "\n", content)
# タイトルとコンテンツを辞書としてarticles_dataリストに追加する
articles_data.append({"title": title, "content": content})
# articles_dataリストをCSVファイルに保存する
with open("articles.csv", "w", newline="", encoding="utf-8") as csv_file:
writer = csv.writer(csv_file)
writer.writerow(["title", "content"])
for article in articles_data:
writer.writerow([article["title"], article["content"]])
if __name__ == "__main__":
blog_url = "https://dodotechno.com"
save_article_data(get_aarticle_urls(blog_url))
なお、実はこのコードもChatGPTに相談しながら作成しました。
最初のプロンプトは以下のようなものです。
 ChatGPTに聞いてみた
ChatGPTに聞いてみたこれ一発で上手くいった訳ではなく、最初は1ページ分しか取得しなかったり、本文自体を取得しなかったりしましたが、修正を重ねさせてようやく使えるものになりました。
WordPressの特有のタグなどは、通常は自分でブラウザの開発ツールを使用して確認しなければいけないのですが、「WordPressのブログ記事の内容を取得する」と指示することで、その手間が省略できただけでも良かったです。(本文からソースコードなどの余分な箇所を除外する部分はほぼChatGPTが出力したコードのままです。)
プロンプトの内容で質問を英語に翻訳して、回答の英語を日本語に翻訳して返す旨の指示を書いてます。
理由は英語の方が精度が高い回答が得られる確率が高いためです。通常の質問などでもその傾向があるので、皆さんもお試しあれ。
上記のコードを実行すると以下のようなCSVファイルが保存されます。
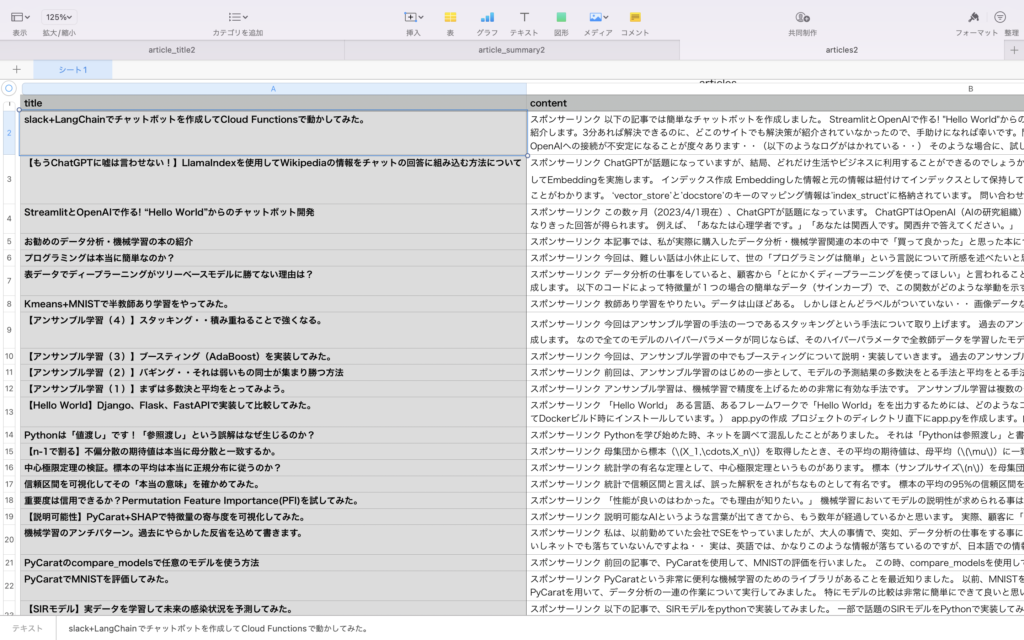 タイトルと本文の一覧
タイトルと本文の一覧本文を要約する。
次に本文を要約します。
最初、この本文の要約にもOpenAIを使用しようとしたのですが、トークン数が足りません。(“This model’s maximum context length is 4097 tokens,…”というエラーが返されます。)
そこで、別のsummyという要約するためのライブラリを使用することにしました。
ソースコードは以下になります。
import csv
from sumy.parsers.plaintext import PlaintextParser
from sumy.nlp.tokenizers import Tokenizer
from sumy.summarizers.lex_rank import LexRankSummarizer
def generate_summary(content):
# トークナイズしたcorpusを使ってparserインスタンスを生成する
parser = PlaintextParser.from_string(content, Tokenizer('japanese'))
# LexRankSummarizerのインスタンスを生成する
summarizer = LexRankSummarizer()
# スペースも1単語として認識されるため、ストップワードにすることで除外する
summarizer.stop_words = [' ']
# sentencres_countに要約後の文の数を指定します。
summary = summarizer(document=parser.document, sentences_count=10)
doc = ""
for sentence in summary:
doc = doc + str(sentence)
return doc
if __name__ == "__main__":
summarized_articles = []
# 入力ファイルを開いて記事を読み込む
with open("articles.csv", "r", encoding="utf-8") as f:
reader = csv.reader(f)
# 最初の行(ヘッダ)を読み飛ばす
next(reader)
for row in reader:
content = row[1]
# generate_summary関数を使って記事の要約を生成する
summary = generate_summary(row[1])
row[1] = summary
# 要約された記事をリストに追加する
summarized_articles.append(row)
# 出力ファイルを開いて、要約された記事を書き出す
with open("article_summary.csv", "w", encoding="utf-8", newline="") as f:
writer = csv.writer(f)
# ヘッダ行を書き出す
writer.writerow(["title", "summary"])
# 要約された記事を書き出す
for row in summarized_articles:
writer.writerow(row)
実行すると以下のようなCSVファイルが出力されます。
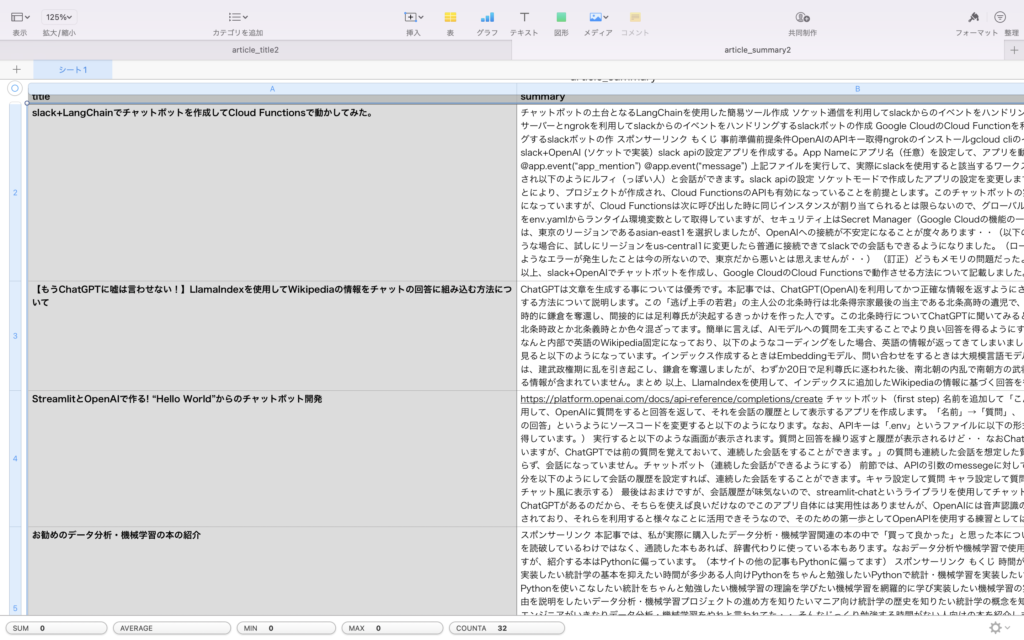 記事の要約
記事の要約ChatGPTの要約と比べると、文書をピックアップして繋ぎ合わせた感が否めませんが、今回はこれで良しとします。
要約文からSEOタイトルを生成する。
最後に要約文から記事のタイトルを生成します。このタイトル生成にOpenAIを使用します。
ソースコードは以下になります。(OPENAI_API_KEYは.envファイルに記載しています。)
import os
import csv
from dotenv import load_dotenv
import openai
from os.path import join, dirname
# OpenAI APIキーを設定する
# APIキーの設定
load_dotenv(join(dirname(__file__), '.env'))
openai.api_key = os.environ.get("OPENAI_API_KEY")
# OpenAIを使用して記事の本文から概要を生成する関数
def generate_title(content, n):
# タイトルを生成するためのプロンプトを作成する
prompt = \
f"""以下はブログの記事の概要です。
記事にマッチしたSEOを考慮した日本語のブログのタイトルを{n}個考えて半角のカンマ(,)区切りで返してください。
なお以下のフォーマットを厳守してください。
・タイトルは日本語で絶対に30文字から60文字の長さにしてくだい。
誤った例 簡単なログラミングの方法
誤った例 猿でもわかる?本当にわかる?流石に今までやったことない人には無理なのでは?やれば信じられる!今日から誰でも始められる簡単なプログラミングの方法"
正しい例 猿でもわかる?今日から誰でも始められる簡単なプログラミングの方法
・タイトルを引用符や鉤括弧で絶対に囲まないでください。
誤った例 「猿でもわかる?今日から誰でも始められる簡単なプログラミングの方法」
誤った例 "猿でもわかる?今日から誰でも始められる簡単なプログラミングの方法"
正しい例 猿でもわかる?今日から誰でも始められる簡単なプログラミングの方法
・タイトルの文字列に半角のカンマ(,)は絶対に使用しないでください。
誤った例 猿でもわかる?,今日から誰でも始められる簡単なプログラミングの方法
正しい例 猿でもわかる?今日から誰でも始められる簡単なプログラミングの方法
・タイトルの間の区切りは必ず全角ではなく半角のカンマ(,)を使用してださい。
誤った例 タイトル1、タイトル2、タイトル3
正しい例 タイトル1,タイトル2,タイトル3
:{content}"""
# OpenAIを使用して、記事からタイトルを生成する
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt},],
temperature=1
)
title = response.choices[0]["message"]["content"].strip()
return title
if __name__ == "__main__":
# タイトル候補数
title_num = 3
summarized_articles = []
# 入力ファイルを開いて記事を読み込む
with open("article_summary.csv", "r", encoding="utf-8") as f:
reader = csv.reader(f)
# 最初の行(ヘッダ)を読み飛ばす
next(reader)
for row in reader:
# 記事からtitle_num個のタイトルを生成する
titles = generate_title(row[1], title_num).split(",")
del row[1]
row.extend(titles)
summarized_articles.append(row)
# 出力ファイルを開いて、タイトルが追加された記事を書き出す
with open("article_title.csv", "w", encoding="utf-8", newline="") as f:
writer = csv.writer(f)
# ヘッダ行を書き出す
title_headers = ["title"]
title_headers.extend([f"seo title{i+1}" for i in range(title_num)])
writer.writerow(title_headers)
# タイトルが追加された記事を書き出す
for row in summarized_articles:
writer.writerow(row)
単に要約文から記事のタイトルを考えろという指示なのにプロンプトが長いと思われたかと思います。
これには理由があって、本ソースコードはタイトルを指定した数だけ(上のコードでは3つ)カンマ区切りで生成して、CSVに保存しようとしてるのですが、カンマが全角になったり、その他色々と指示を守ってくれなくて大変なので、しつこく指示を書きました。
一応、コツとしてはOKケースとNGケースを例示すると良い結果が得られる傾向があるとのことで、それを記載しています。(実はこれでも全ては上手くいかない・・)
実行すると以下のようなCSVファイルが出力されます。
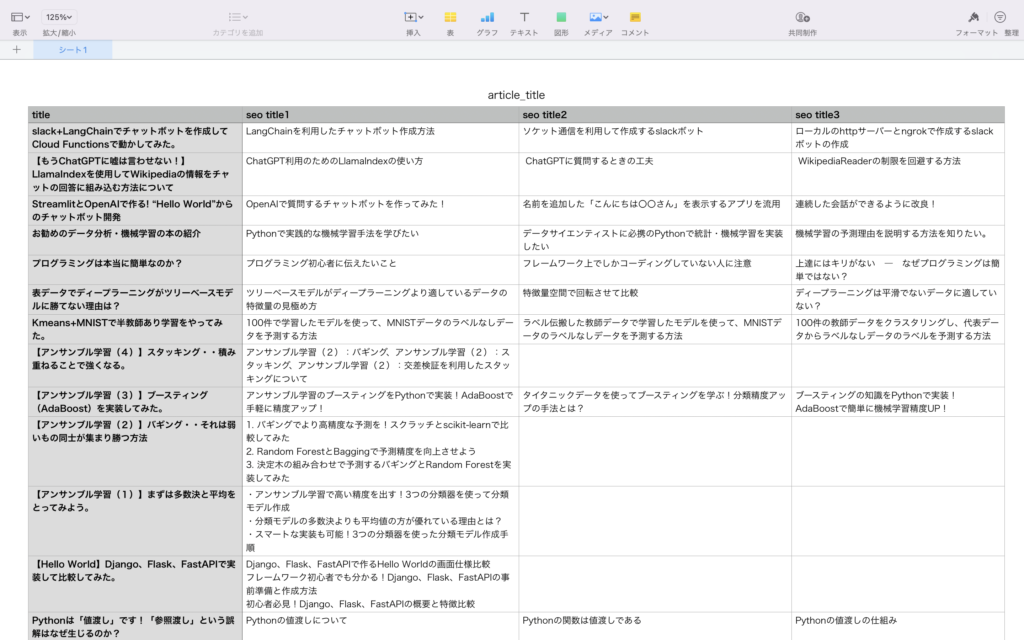 SEOに強いタイトル?
SEOに強いタイトル?プロンプトでこれだけ強く言ったのに、記事によって文字数の条件が守られていなかったり、カンマ区切りでなく箇条書きで出力されたため1列に押し込められたりしています。
OpenAIを呼び出す時のtemperatureの値(上記コードでは1)が高すぎるからかなと実行しいた後に思いましたが(temperaturegが大きいと偶然性が高くなる)、これ以上、API呼び出しにお金をかけたくないので、今回はここでやめておきます。
肝心のSEOタイトルですが、これはいいなと思うものもあれば、残念なものもあります。
結局、最後は人による取捨選択が必要な気がします。
まとめ
以上、本記事ではOpenAIを使用して記事の内容からSEOに強いタイトルを生成する方法について説明しました。
全てのタイトルが素晴らしかったら、そのタイトルをもとに自動でブログのタイトルを付け直すところまでやろうと思ってましたが、現実的ではないので、今回は生成するところまでにしておきます。
現在、ChatGPTブームで様々なアプリが開発されており、思いついたもの勝ちみたいになっている感じがします。(世に出ているアプリは実は作成自体は割と簡単なものが多いのです・・)
あわよくば自分でも何か思いついてアプリをという気持ちもあり今後も色々と試していきたいと思います。
余談ですが、本記事のサムネイルは、Stable Diffusionで作成しました。(呪文は”robot is writing article”です。)
これまではpixabayのフリー画像を使用していましたが、今後はStable Diffusionで事足りるような気がします。