最近、YouTubeやXでは、v0とCursorを使用したアプリの開発体験・手順の説明が溢れています。
そんな中、自分がわざわざそれについて記事を書く必要はないかと思っていたのですが、「あまりにも簡単すぎて、もうエンジニアやプログラマーは不要だ」といった意見を目にすると、少しうーん…と思ってしまいます。
もちろん、v0とCursorは画期的であり、最初に触れたときは感動しました。ただし、実際に使ってみると、できることとできないことがあるのは事実です。
そこで、ソフトウェアエンジニアの端くれとして、私がv0+Cursorでの開発プロセスを通して感じたリアルな長所や短所、そしてコツや注意点について、3つのアプリを例にご紹介します。
前提
まず最初にお伝えしておきますが、本記事では手順の説明はほとんど行いません。詳細な手順については、世に溢れているYouTube動画などをご参照ください。
ただし、私のように、何も見ずにとりあえず始めてしまうタイプの方には、1点だけ覚えておいていただきたいことがあります。v0からコードを取得する際、画面右上にあるボタンを押すと、ローカルで実行するためのコマンドが表示されます。それを使用すれば、必要なライブラリも含めて一緒にインストールされます。

私の場合、これを知らずにソースコードを直接コピーしてしまい、「あれが足りない、これが足りない」とエラーを1つ1つ解決しながら環境を整えるのに非常に時間がかかりましたが、このコマンドを使えば一瞬で解決しました…。
① 織田信長のプロフィール画面
これをアプリと言っていいのかどうかわかりませんが、まずは固定ページでどのような画面ができるか確かめてみます。
v0画面のプロンプトは以下となります。
織田信長のプロフィールページを作成してください
最初に作成された画面がこちらです。

このままだとデザインが今ひとつだったため、「戦国武将風のデザインでもっとかっこいいページにしてください」と指示しました。さらに、文字と背景色が同系統で見づらかったので、「文字と背景が同じ色で見えません」と追加で指示を出し、計3回のやり取りの結果、以下のようなデザインになりました。
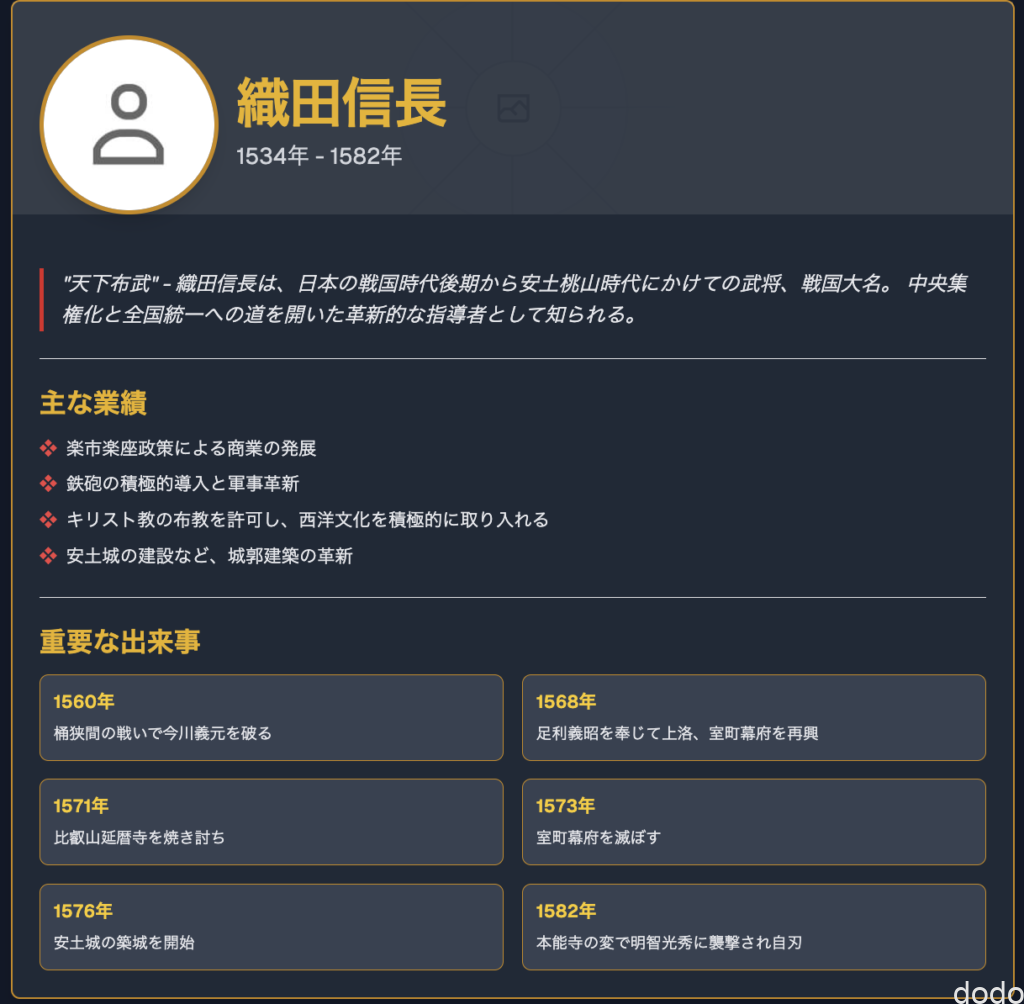 最初の画面と比較すると、かなり良くなっており、十分に見栄えがするのではないでしょうか。
最初の画面と比較すると、かなり良くなっており、十分に見栄えがするのではないでしょうか。
次に、せっかく出来事がタイル形式になっているのでそれぞれのタイルをクリックすると各出来事の詳細画面に遷移するよう指示しました。
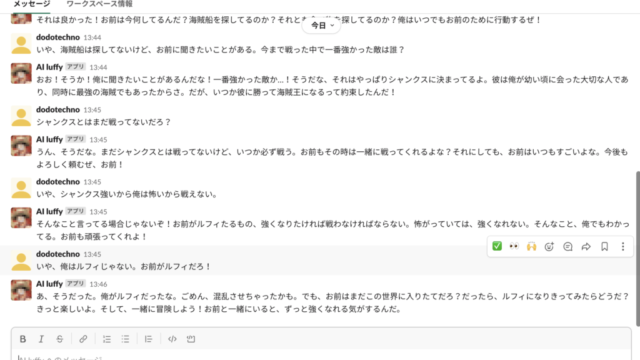
しかし、これが意外になかなか上手くいきません(遷移しない・・)
「遷移しません」「修正しました」「やっぱり遷移しません」「修正しました」・・を繰り返していくうちにあっという間に無料プランの1日の上限に達してしまいました。
そこでCursorで作業するためにローカルに持ってきて(ソースの取得方法は「前提」を参照。決してソースをコピーして持ってこないように・・)、動作させたら、なんとローカルでは動作します。
デザインが固まったらロジックはローカルでさっさと確かめた方が良いかもしれません。
以下、完成した画面の動作になります。
なお織田信長の画像はいらすとや様(https://www.irasutoya.com)の画像を使用させていただきました。
ただ、ご覧の通り、かなり「昔ながらのホームページ感」が漂っています。
その後、「もっとクールで洗練された現代風にしてほしい」という旨の指示を言葉を変えつつ数回出しましたが、大きな変化は見られませんでした。
一応別パターンです。
ネット上では、v0を使った洗練されたデザインのページ作成例が多く見られますが、やはりテンプレートの画像をしっかり用意するか、色合いやレイアウトをより具体的に細かく指示しないと、思い通りの結果は得られないのかもしれません。(もしくは私の知らないコツがあるのかも…)
② 言葉とシンクロする曲のランキング
実は、以前作成したWEBアプリ(現在は閉鎖しました。)があります。このアプリでは、アーティストを選んで言葉を送ると、その言葉に合う曲の一覧を返してくれます。
このアプリ自体は、機械学習技術をしっかり使用して曲を選んでいますが、これと似た感じのアプリを簡単に作れないか試してみました。
v0でのプロンプトは以下の通りです。
今の気分を入力すると、その気分にあった曲のTOP10のランキングを返してくれるWEBアプリを作成してください。 ランキング表のイメージは添付のようなものにしてください。
以前作成したアプリの画面を添付しました。
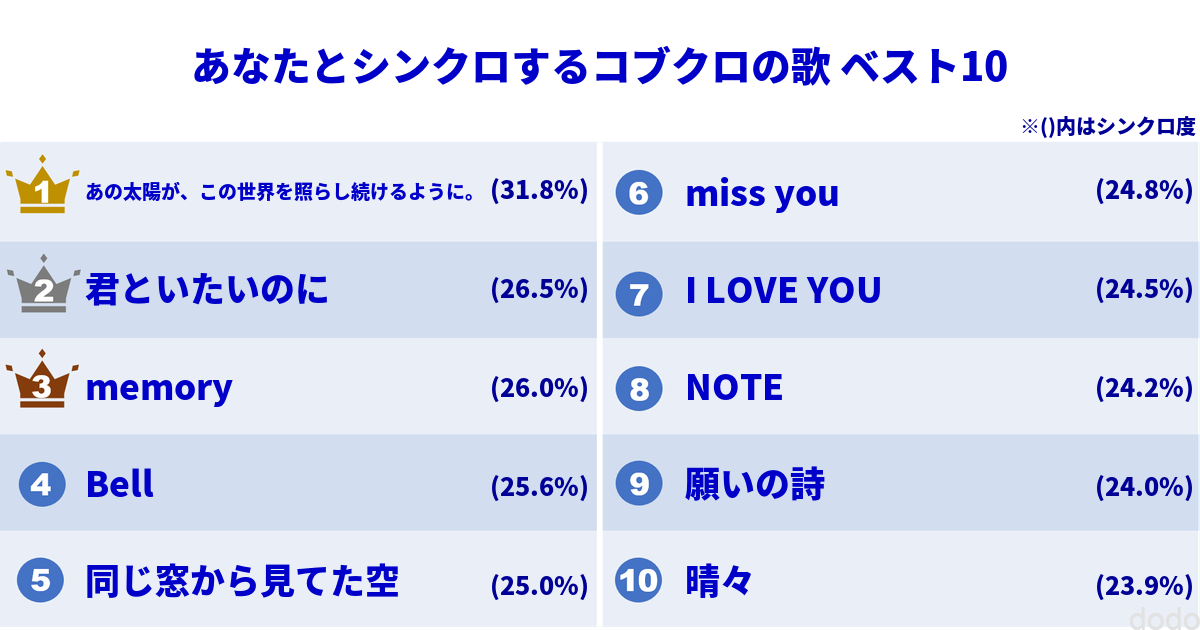
そして最初のプロンプトで出来上がった画面が以下となります。
なお、この時点ではランキングはソースコードに固定で書かれています。
この後、デザインや文言など諸々の調整を指示、OpenAIを使用することを想定してOpenAIのAPIキーを設定できるように指示して出来上がった画面が以下となります。(入力する時に1passwordのアシスタントが出てきますが私のローカルの問題なので画面仕様とは無関係です。)
実際にOpenAIから情報を取得するためにローカルに持ってきてCursorで作業します。
現状(2024/10/1現在)、v0で直接ソースを修正することはできません。つまり1度、ローカルに持ってきてソースを修正した後は、修正済みのコードをv0に戻して、再度デザインを調整といった作業はできないので注意してください。
(外国の方のXのポストなどでは「いつになったら修正できるようになる?」と嘆いている方が多々いるのでそのうち対応するかもしれません)
2024/10/6 追記
ソースを選んで引用して「ここをこのように修正してください」とやれば一応できるようにです。直接修正とは違いますが、とりあえず修正する手段はあります。(ただクレジットは消費します。)
2024/10/9 追記
ついに、直接編集できるようになりました!この改修は大きい!
You can now edit the generated code in UI Blocks for faster, more precise edits. pic.twitter.com/nO3eVuTGGI
— v0 (@v0) October 9, 2024
ローカルで確認した所、入力域がピンクになっていたので、まずはCursor Composerで「入力域の背景は白にしてください。」と指示して修正しました。
v0上で実行していた場合とローカルでデザインが異なって見える場合があります。その場合はCursor上で修正しましょう。
そしていよいよ本題の修正です。Cursor Composerで以下の指示をしました。
設定されたOpenAIのキーからOpenAIに問い合わせて曲名、アーティスト名、シンクロ度(vetorの類似度から算出)を取得して設定するようにしてください。
// ... 既存のインポート ...
import axios from 'axios';
// OpenAIのAPIを呼び出す関数
async function getOpenAIResponse(mood: string, apiKey: string) {
const response = await axios.post(
'https://api.openai.com/v1/chat/completions',
{
model: "gpt-3.5-turbo",
messages: [
{
role: "system",
content: "あなたは音楽エキスパートです。ユーザーの気分に合う曲を10曲提案し、曲名、アーティスト名、シンクロ度(0-100の数値)をJSON形式で返してください。"
},
{
role: "user",
content: `気分: ${mood}`
}
]
},
{
headers: {
'Authorization': `Bearer ${apiKey}`,
'Content-Type': 'application/json'
}
}
);
const content = response.data.choices[0].message.content;
return JSON.parse(content);
モデル名を「gpt-4o-mini」に変更して実行しましたが、返答が指示した通りのJSON形式では返ってこず、JavaScript側でオブジェクトにマッピングする際にエラーが発生します。これはよくあるケースで、返答に以下の赤字で示したような余計な文言が付け加えられてしまうことが原因です。
楽しい気分に合う曲を10曲提案します。以下がそのリストです。
“`json
[
{
“曲名”: “Happy”,
“アーティスト名”: “Pharrell Williams”,
“シンクロ度”: 95
},
(中略)
{
“曲名”: “Shake It Off”,
“アーティスト名”: “Taylor Swift”,
“シンクロ度”: 88
},
{
“曲名”: “Party in the USA”,
“アーティスト名”: “Miley Cyrus”,
“シンクロ度”: 87
}
]
“`
このリストが楽しい気分にぴったり合う曲を見つける手助けになりますように!
プロンプトに「余計な文言を追加しないでください」と指示する方法もありますが、確実ではないので、以前の記事に書いたStructured Outputsの機能を利用して回答の構造を指定します。
ただし、Structured Outputsは最近のアップデートのためCursor Composerでいくら指定しても上手くいきませんでした。
また、モデル名の「gpt-4o-mini」も「そんなモデルは存在しない」と言われて何度も古いモデルに書き換えられそうになりました。なのでここからは完全な手修正です。
最終的に上で示したOpenAIにアクセスする箇所のソースは以下のように自分で修正しました。(title,artist,syncScoreはJavascript側の一覧で取得する変数名と合わせてます。)
import axios from 'axios';
// OpenAIのAPIを呼び出す関数
async function getOpenAIResponse(mood: string, apiKey: string) {
const response = await axios.post(
'https://api.openai.com/v1/chat/completions',
{
model: "gpt-4o-mini-2024-07-18",
messages: [
{
role: "system",
content: "あなたは音楽エキスパートです。ユーザーの気分に合う日本の曲を10曲提案し、シンクロ度(0-100の数値)が高い順に曲名、アーティスト名、シンクロ度を返してください。ここでのシンクロ度は気分と曲の歌詞のエンベディングベクトルの類似度を0-100の範囲に換算したものを算出してください。また必ず実際に存在する曲を提案してください。"
},
{
role: "user",
content: `気分: ${mood}`
}
],
response_format: {
type: "json_schema",
json_schema: {
name: 'song_response',
strict: true,
schema: {
type: "object",
properties: {
songs: {
type: "array",
items: {
type: "object",
properties: {
title: { type: "string" },
artist: { type: "string" },
syncScore: { type: "number" }
},
required: ["title", "artist", "syncScore"],
additionalProperties: false
}
}
},
required: ["songs"],
additionalProperties: false
}
}
}
},
{
headers: {
'Authorization': `Bearer ${apiKey}`
}
}
);
const content = response.data.choices[0].message.content;
// デバッグ用:OpenAIからの生の応答をログに出力
console.log('OpenAI Raw Response:', content);
return JSON.parse(content);
各種サブスクリプションサービスへのリンクも追加しました(APIで直接曲にリンクするのではなく、検索させる形式にしています)。上の動画ではSpotifyに遷移させています。(最後に表示される画面はSpotifyのサイトの画面です。)
なお、このアプリはお遊びレベルなので、実在しない曲や組み合わせが表示されることがありますが、そこはご愛嬌ということで…。実用レベルにするためには、取得したデータを検索して実在するか確認する必要があると思います。(もしくは、プロンプトを工夫すれば解決できるのか?)
③ Open LLM 版の天秤AIもどき
複数のLLMの回答を比較できる「天秤AI」というサイトがあります。
ここでは、それを真似てHugging Faceのインターフェースを使用し、Hugging Faceで公開されているモデルの回答を比較できる画面を作成します。
「天秤AIを真似して」と書きましたが、実際に画面イメージを参考にしたのは、以下の動画です。こちらではGradio(機械学習モデルのデモを行うWebアプリケーションを簡単に作成できるPythonのライブラリー)を使って作成しています。
(引用元:Building an LLM Application with Gradio(HuggingFace))
こちらの画面イメージを添付し、以下のプロンプトを投げました。
プロンプトを入力してhuggingfaceのLLMの3つのモデルの回答結果を返すような画面を作成してください。
以下のような画面ができました。
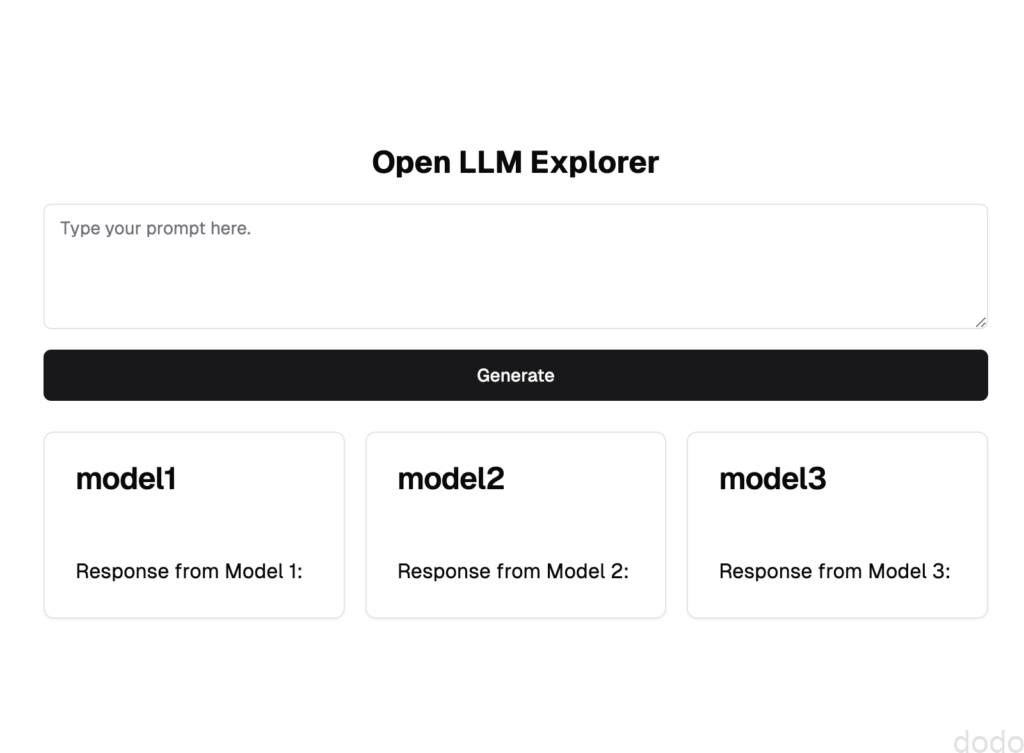
この後、以下のような指示をしました。(最初と合わせて計7回)
- デザインを商用にたえうるようなかっこいいものにしてください。
- 色調をもっと爽やかにしてください
- 設定画面で、Huggingfaceのキーと3つのモデルのIDを入力できるようにしてください。
- 設定画面で設定したIDを画面の各モデルのタイトルに反映させてください。またsetting画面に[OK][キャンセル]ボタンを追加してOKを押した時のみ反映させるようにしてください。
- メインタイトルのモデル名を「generate resppnses」を押した時ではなくて、設定ボタンでOKを押した時に反映するようにしてください。
設定画面のOKボタンとキャンセルボタンを逆にしてください。 - 「Response will appear」 と「モデル名 response to: 入力」の表示は不要です。
そして出来上がった画面がこちらです。
それではこちらをローカルに持ってきてCursorで作業します。
最初のプロンプトは、以下です。
設定したAPIキーと各モデルのモデルIDからHugging FaceのAPIを呼び出して、入力から回答を返すようにしてください。
なんと今回は、一発で呼び出しが成功しました。(ちなみにデフォルトのモデルはgpt2,gpt2-mediun,gpt2-largeになっていました。)
その後、エラー処理などを若干修正して完成した画面が以下となります。
この動画では途中でデフォルトのLLM(gpt2,gpt2-medium,gpt2-large)から以下の3つのモデルに変更しました。
- mistralai/Mistral-Nemo-Instruct-2407
- google/gemma-2-2b-it
- meta-llama/Meta-Llama-3-8B-Instruct
これらのモデルはフリーにしては比較的性能が良いとされていますが、gpt-4oなどと比較すると、まだまだ差を感じますね…(Llamaの3.2を使用すればまた違う結果になるかもしれませんが)。
とはいえ、Hugging Faceが豊富に提供しているLLMをこのように試せるのは、非常に便利だと思います。
従来、このようなお試し画面を作成するには、StreamlitやGradioを使うのが便利でしたが、簡単なUIであれば、v0(実態はNext.js)を使って作成する方が楽かもしれません。
まとめ
以上、3つのアプリ作成を通して、v0+Cursorでの開発を体験してみました。
この体験を通して感じた長所と短所をまとめると以下の通りです。
長所
- デザイン性の高いフロントエンドの開発が圧倒的に楽になった(v0)。
- その場ですぐに動作を確認できるため、フロントエンドのみならば開発環境が不要で、そのままリンクを共有して公開も可能。モックアップやLPなら非エンジニアでも作成可能(v0)。
- 簡単にローカル環境で再現するためのコマンドが用意されている(v0)。
- ほぼ対話形式でソースコードの修正ができる(Cursor)。
- エラーが発生しても、原因と対策が提示されるのでデバッグがしやすい(Cursor)。
短所
ソースコードを直接手修正することができない(※ソースを画面で引用して修正指示は可能)(v0)。(2024/10/9 修正できるようになりました!)- 洗練されたデザインの画面を作成するにはイメージの添付か詳細な色調、配置などの指示が必要(v0)。
- v0を使用する限り、Next.jsを必ず使用することになる。(Next.js の開発元 のVercel 社が提供してます。)
- 業務で本格的に使用するには有料プランが必須(無料だと使用制限が厳しい。特に不具合修正をしてるとあっという間に制限に達してしまいます。)(v0, Cursor)。
- ライブラリのアップデートに対応しきれておらず、古いバージョンのコードが出力されることがある(Cursor)。
注意点
さらに注意点をまとめると以下になります。
- v0上とローカルでデザインの見た目が異なる場合がある。
- v0上で動作しなくてもローカルでは動作することがある。
- ローカルで修正後はv0には戻せない。(ソースの手修正が出来ないため)
ある程度のデザインが決まったら、さっさとローカルに持ってきたほうが良いでしょう。ロジックに関してはローカルでCursorを使用した方が簡単に修正できるような気がします。(無料で使用している人はv0でバグ潰しを始めるとあっという間に使用制限に達してしまうので注意が必要です。)
雑感
最後に雑感ですが、AI系インフルエンサー(もしくは情報商材屋?)がよく言っている「エンジニアでなくても開発できる」という点についてですが、上記の「長所」にもある通り、確かにv0を使えば、営業やコンサルタントでもデモ用のモックアップ画面やLPを簡単に作成することは可能です。
しかし、本格的なWEBアプリとなると、やはり言語の知識が必要な場面が多く、そう簡単にはいかないと感じています。
今回、今後v0を使用して開発していくならばReactとNext.jsはある程度使えるようになっておいた方が良いと思いました。いざという時にソースコードを全く理解できないのは流石に危険だと思います。この事は、「AIが発達すればプログラムを覚える必要はない」という流れとは逆行していますが、私の現時点での正直な感想です。
Cursorが非常に優れたペアプログラミングパートナーであることは間違いありませんが、現時点では完全にエンジニアの手を離れることは難しいと感じます。
もちろん、AI技術は日々進化しているため、これらはあくまで現時点での感想ということをご理解ください。(我ながら「現時点」しつこい…)