










私が以前、作ったWEBアプリではアーティスト毎のページに歌詞の頻出語を可視化したWord Cloudにより生成した図を表示していました。(サムネイル参照)
本記事では、Word Cloudで歌詞を可視化するための、pythonを用いた以下の手法について記載します。
- ネットから歌詞を収集する。(スクレイピング)
- 「分かち書き」をする。
- Word Cloudで可視化する。
※掲載するソースコードは実際のWEBアプリで使用しているコードとは汎用性・例外処理・ログ出力有無の点で大きく異なります。ソースを利用する際はくれぐれも自己責任でお願いします。
スクレイピング
スクレイピングとは、ネットから情報をプログラム・ツールを使用して収集する事です。
まずは、好きなアーティストの歌詞をネット上の歌詞を提供しているサイトから収集する方法について記載します。
歌詞を提供しているサイトはいくつかありますが、ここでは、Uta-Netさんから歌詞をスクレイピングする例を記載します。
スクレイピングする際の注意点は大きく分けて3点ありますので留意してください。
- 「歌詞」のようにスクレイピング対象が著作権で保護されている場合は、あくまでも「情報解析目的」のための収集である事(著作権法第30条の4) 。ただし商用サイトで利用するなど「本気」の運営をするならば弁護士に相談することをお勧めします。
- 対象サイトでスクレイピングが禁止されていない事(robots.txt、利用規約で確認)
- 対象サイトに負荷をかけない事(最低でも1秒以上間隔を空ける)
スクレイピングに必要なパッケージをインポートします。(結果を格納するためのデータフレームを使用するためpandasも利用します。)
import time
import requests
import pandas as pd
from bs4 import BeautifulSoup
とあるアーティストのページのURLを変数に設定します。(どのアーティストかはアクセスすればわかります。)
#歌詞URL
lylics_url = "https://www.uta-net.com/artist/3891/"
実際に歌詞が掲載されているページは、上記URLにページ指定「/0/ページ番号/」が付与されております。(例:2ページ目ならば、「https://www.uta-net.com/artist/3891/0/2/」)
さらに1ページ内に曲の一覧が格納されている複数のテーブル(<table/>)が存在する仕組みとなっています。
これらの事をふまえて、ページ毎のテーブル構造を取得する関数を作成します。
def get_tables(url, page):
response = requests.get(f"{url}0/{page}/")
#lxmlはパーサー
soup = BeautifulSoup(response.text, 'lxml')
#ページ内の全テーブルを取得
tables = soup.find_all('table')
return tables
上記の関数をページ毎に繰り返し呼び出し、テーブルの内容と歌詞URLのリンク先をDデータフレームとして取得します。
def get_song_list(url):
# 保存するDataFrameのカラム名
columns_names = ['曲名', '歌手名', '作詞者名', '作曲者名', '歌い出し', '歌詞URL']
data = []
page_no = 0
#ページ毎のループ
while True:
page_no += 1
#ページ単位でのテーブルを取得する。
tables = get_tables(url, page_no)
#テーブルが取得できない場合は終了
if len(tables) == 0:
break
# 1秒間スリープ(負荷対策)
time.sleep(1)
#テーブル毎のループ
for table in tables:
for row in table.find_all('tr'):
row_data = []
#ヘッダー以外の行の場合に処理を実行する。
if row.find('td') is not None:
# 「曲名」〜「歌い出し」までのカラムを追加
for td in row.find_all('td'):
row_data.append(''.join(td.stripped_strings))
# 曲名のリンク先から歌詞URL(歌詞へのパス)を追加
url_td = row.find('td', class_='side td1')
url_song = url_td.a.get('href')
row_data.append(url_song)
# 行を追加
data.append(row_data)
#データフレームに格納して返す。
lyrics_df = pd.DataFrame(data, columns=columns_names)
return lyrics_df
取得したデータフレームの先頭行を表示すると以下のようになります。(アーティスト、バレバレですが・・)
lyrics_df = get_song_list(lylics_url)
lyrics_df.head() 曲に歌詞URLを付与したデータフレーム(※「歌い出し」は著作権の都合上、非表示としています。)
曲に歌詞URLを付与したデータフレーム(※「歌い出し」は著作権の都合上、非表示としています。)次に歌詞URLを元に曲ごとの歌詞を取得します。
歌詞ページのURLから歌詞を取得する関数を作成します。
def get_lyrics(lyrics_url):
#歌詞URL
url = f"https://www.uta-net.com{lyrics_url}"
#歌詞取得
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
song_lyrics = soup.find('div', itemprop='lyrics')
lyrics = song_lyrics.text
#1秒間スリープ(負荷対策)
time.sleep(1)
return lyrics
この関数を呼び出す事によって歌詞を取得して、データフレームに歌詞を格納した列を追加します。
lyrics_df["歌詞"] = lyrics_df["歌詞URL"].apply(get_lyrics)
先頭行を表示すると以下のようになります。(著作権の都合上、非表示にしているのでわかりにくいですが・・)
 曲に歌詞を付与したデータフレーム(歌詞は著作権の都合上、非表示としています。)
曲に歌詞を付与したデータフレーム(歌詞は著作権の都合上、非表示としています。)分かち書き
「分ち書き」とは、簡単に言ってしまうと、文章を単語レベルで分解する事です。
英語のように単語毎に空白で区切られている場合は、簡単に単語を抽出できますが、日本語のように空白なしで続けて記載されている場合は、文章中の単語の品詞を分析(形態素解析)して、分解する必要があります。
「分かち書き」をするための形態素解析エンジンにはポピュラーなものではMecabとJUMANがありますが、ここではMecabを利用します。
インストール
Mecabをインストールするためには、mac(かつHomebrewインストール済)ならば以下のコマンドでインストールできます。
brew install mecab
brew install mecab-ipadic
2行目でインストールするmecab-ipadic(IPA辞書)は形態素解析で使用するための辞書でとなります。
Linux(Debian,Ubuntu系)ならば、aptを利用して以下のコマンドでインストールします。
sudo apt install mecab
sudo apt install libmecab-dev
sudo apt install mecab-ipadic-utf8
なお、Windowsは、http://taku910.github.io/mecab/のページからインストーラー(mecab-0.996.exe)をダウンロードして実行するようです。(私自身は未検証です。)
辞書は、IPA辞書でも良いのですが、最新の情報が随時追加されており、新語に強いと言われるmecab-ipadic-neologdをインストールします。
Mac,Linuxでは以下のようにgitから取得した後にインストールを実行します。(Windowsでどうやるかは、どなたか書いているのでそちらをご参照ください・・)
git clone --depth 1 git@github.com:neologd/mecab-ipadic-neologd.git
cd mecab-ipadic-neologd
./bin/install-mecab-ipadic-neologd -n
実行
インストールして準備が整ったら実際に実行してみます。
まずはMecabのパッケージをインポートし、Mecabの辞書としてmecab-ipadic-neologdを指定します。
import MeCab
#辞書としてmecab-ipadic-neologdを指定する。
mecab = MeCab.Tagger ('-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd')
#おまじない(mecabのバグ回避)
mecab.parse('')
曲毎の歌詞を単語に分割するための関数を作成します。
def text_to_words(text):
words_song = []
#分解した単語ごとにループする。
node = mecab.parseToNode(text)
while node:
word_type = node.feature.split(",")[0]
#名詞、形容詞、副詞、動詞の場合のみ追加
if word_type in ["名詞", "形容詞", "副詞", "動詞"]:
words_song.append(node.surface.upper())
node = node.next
#曲毎の単語の重複を削除して'空白区切のテキストを返す。
words = ' '.join(set(words_song))
return words
因みに私は歌詞毎に単語の重複を除去しています。
単語の頻出度を知りたいのに、何故、単語の重複を除去しているかと言うと、1曲に繰り返しある単語が現れる場合、その単語があまりにも目立ってしまうケースがあったで、同じ単語は1曲1カウントとしました。(1つの曲で「WowWow・・・」とか多く出現すると、そればかり目立ってしまうので・・)
試しに、この関数に適当な文章を渡して実行してみます。
print(text_to_words("明日は明日。今日は今日。明日晴れると良いですね。"))
結果は以下のようになります。
晴れる 良い 明日 今日Word Cloudで可視化する準備として、スクリーニングで生成したデータフレームに分かち書きした歌詞を格納する列を追加します。
lyrics_df["words"] = lyrics_df["歌詞"].apply(text_to_words)
曲名、歌手名、そして歌詞を分かち書きした列を表示すると以下のようになります。(流石に、分かち書きして重複削除してシャッフルすれば、もう単語の羅列なので表示してもいいはず・・)
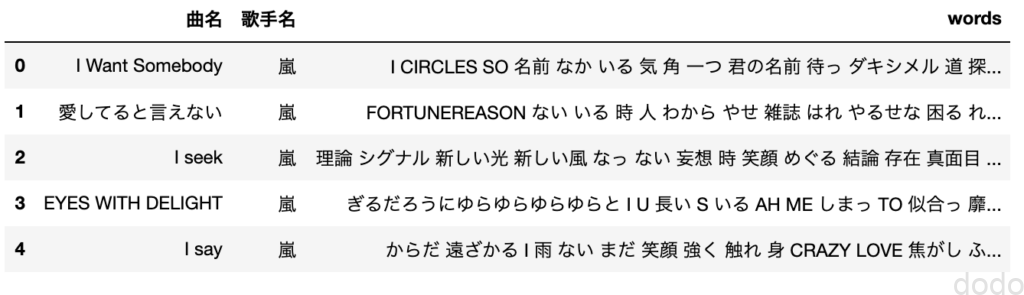 分かち書きした歌詞を追加したデータフレーム
分かち書きした歌詞を追加したデータフレームWord Cloudで可視化
ようやくWord Cloudを使用する段階になりました。
まずは必要なパッケージをインポートします。(図を表示するためにmatplotlibを使用します。)
from wordcloud import WordCloud
%matplotlib inline
import matplotlib.pyplot as plt
Mecabで分かち書きを実行した際に、品詞をある程度制限しましたが、指示代名詞(あの、この、その等)や、あまり意味をなさなそうな言葉が残っているので、それらは表示しないようにします。
そのための言葉(無意味そうで表示しない言葉)の配列を宣言します。
# wordcloud用の無意味そうな単語除去
stop_words = ['そう', 'ない', 'いる', 'する', 'まま', 'よう',
'てる', 'なる', 'こと', 'もう', 'いい', 'ある',
'ゆく', 'れる', 'なっ', 'ちゃっ', 'ちょっ',
'ちょっ', 'やっ', 'あっ', 'ちゃう', 'その', 'あの',
'この', 'どの', 'それ', 'あれ', 'これ', 'どれ',
'から', 'なら', 'だけ', 'じゃあ', 'られ', 'たら', 'のに',
'って', 'られ', 'ずっ', 'じゃ', 'ちゃ', 'くれ', 'なんて', 'だろ',
'でしょ', 'せる', 'なれ', 'どう', 'たい', 'けど', 'でも', 'って',
'まで', 'なく', 'もの', 'ここ', 'どこ', 'そこ', 'さえ', 'なく',
'たり', 'なり', 'だっ', 'まで', 'ため', 'ながら', 'より', 'られる', 'です']※当初、品詞を制限していなかった関係で、現状では除去する必要がない品詞の単語(分かち書きした時点で除去済み)も含まれています。(改めて精査して削除するのも面倒臭かったのでそのままにしています。)
いよいよWord Cloudで可視化してみます。
なお、font_pathに指定されている使用フォントは、ご自身の環境に合わせてください。
#全曲の単語を結合する。
words_all = ' '.join(lyrics_df['words'].tolist())
#wordCloud生成
wordcloud = WordCloud(background_color="white",
font_path="/Library/Fonts/NotoSansCJKjp-Bold.otf",
width=800,
height=600,
collocations=False,
stopwords=set(stop_words)).generate(words_all)
#可視化
fig,ax = plt.subplots(figsize=(15,12))
ax.imshow(wordcloud)
ax.axis("off")
#保存
wordcloud.to_file("wordcloud.png")
上記のソースコードでのポイントは、WordCloudのコンストラクタの引数に「collocations=False」を指定している事です。
デフォルトでは「collocations=True」となっておりますが、その場合、2つの単語を連結して別の単語として扱ってしまう場合がありました。
一見、重複した単語が表示されてしまうという弊害に加えて、単語の順番によって連結有無が変わり結果(頻出度)が変わってしまうと現象が発生し、原因がわからず結構ハマりました・・(せっかく分かち書きしているのに余計な事しないで欲しい・・)
上記ソースコードを実行すると以下のような画像が生成されます。
 歌詞のWordCloud可視化
歌詞のWordCloud可視化なお、位置や文字の色はランダムなので実行する毎に異なる画像になります。
また、ピックアップされる文字はデフォルトで2文字以上となっており、変更したい場合は、正規表現の引数(regexp)を追加します。
元々、英語が基準で考えられているので、確かに「A」とか「B」とか表示されても意味ないからでしょう。
ただ日本語だと漢字ならば1文字でも意味があるので、最初は漢字の1文字だけは含めるようにしていたのですが、1文字は見た目が面白くない事、そして、どのアーティストの歌詞でもびっくりするくらい同じ単語が上位に来る(君とか夢とか心とか・・)ので、差が出にくく、デフォルトに戻しました。。
なお、もし1文字以上にしたければWordCloudのコンストラクタの引数に以下を追加します。
regexp=r"\w+"
また、もし漢字の場合のみ1文字以上にしたければ、以下を追加します。(もっと酔い指定方法があるかもしれませんが、あまり正規表現得意じゃないので・・・)
regexp=r"\w[\w']+|[^ぁ-んァ-ン0-9a-zA-Z0-9\-!#$%&'()\*\+\-\.,\/:;<=>?@\[\\\]^_`{|}~]"
参考までに、漢字の場合のみ1文字以上とした場合の画像は以下のようになります。
 歌詞のWordCloud可視化(漢字1文字を含めた場合)
歌詞のWordCloud可視化(漢字1文字を含めた場合)
ここで本当に出現頻度が高い単語が大きくなっているか確かめるため頻度が高いTOP10をグラフ化してみましょう。(stopwordに含まれず、かつ2文字以上の単語のみの場合とします。)
import collections
#2文字以上、stopwordsに指定されていない単語をリスト化する。
words_all_list = [w for w in words_all.split() if w not in stop_words and len(w) > 1]
counter = collections.Counter(words_all_list)
#TOP10を取得
word_10 = dict(counter.most_common(10))
#棒グラフで表示
plt.figure(figsize=(10, 6))
plt.bar(range(len(word_10)),list(word_10.values()), align='center')
plt.xticks(range(len(word_10)), list(word_10.keys()))
plt.tick_params(labelsize=18)
plt.show()
plt.savefig("word-ranking-sample-1.png")
結果は以下のようになり、出現頻度が高い単語がWord Cloudの図(2文字以上とした場合)で大きく表示されている事がわかります。
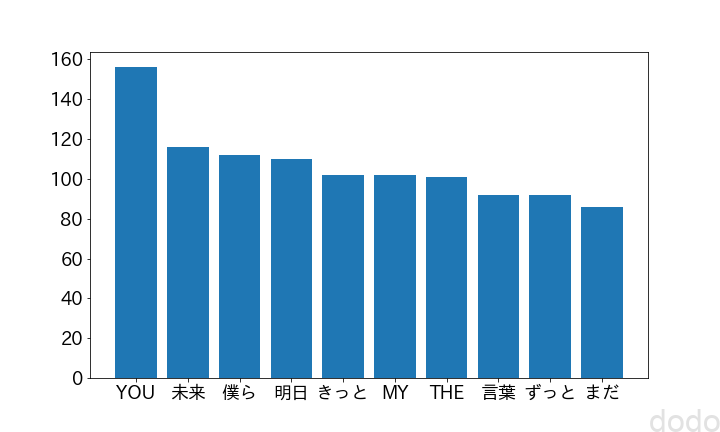 頻出単語TOP10
頻出単語TOP10最後に「おまけ」です。
Word Cloudの画像は他の画像を使用して以下のようにマスク処理をする事ができます。
from PIL import Image
import numpy as np
#マスクイメージ読み込み
image_color = np.array( Image.open( "maskimage.png" ))
#wordCloud生成
wordcloud = WordCloud(background_color="white",
font_path="/Library/Fonts/NotoSansCJKjp-Bold.otf",
width=800,
height=600,
collocations=False,
mask =image_color ,
stopwords=set(stop_words)).generate(words_all)
#可視化
fig,ax = plt.subplots(figsize=(15,12))
ax.imshow(wordcloud)
ax.axis("off")
wordcloud.to_file("wordcloud-sample-2.png") マスクイメージ(※パワポで作ったのでちょっと荒いです・・)
マスクイメージ(※パワポで作ったのでちょっと荒いです・・) 歌詞をWordCloudで可視化(マスクイメージ適用)
歌詞をWordCloudで可視化(マスクイメージ適用)マスク画像に合わせて、文字を表示する領域を決めることができます。
領域以外でもマスクイメージの色調に合わせて、文字色を決めるなども出来るので、興味ある方は調べてみてください。
まとめ
以上、歌詞のスクレイピングからWord Cloudによる可視化までの一連の処理についての手法を記載しました。
Word Cloudを使うと、パッと見て、どの単語が多く使われているかがわかるので、なかなか面白いです。
ただ、ビジネスとしての分析の報告で使えるかというと微妙だと思います。
Word Cloudは、キャッチーさはありますが「お遊び」の要素が強いので、真面目に単語の頻出度を表現するためには、素直に棒グラフを書いた方が良いでしょう。
なお「分かち書き」については、日本語のよう空白で単語が区切られていない言語の場合は、自然言語処理をするための第一歩になるので、ビジネスでも重要な処理となります。
別途、「分かち書き」した歌詞から単語の類似性などを学習する処理について記載する予定です。


